【Python】ものすごく単純なスクレイピングツールの作成
投稿日 2019年6月3日 >> 更新日 2023年3月3日
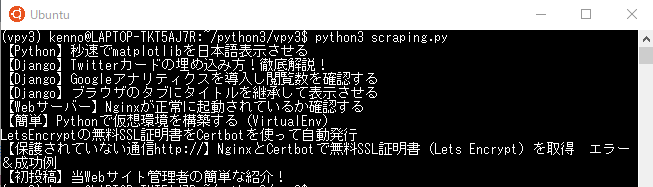
今回は一枚のPythonファイルに12行のコードを使ったスクレイピングツールを作成していこうと思います。
ただ表示させるだけではなく、取得したHTMLの要素をテキストエディタに保存していきます。
果たしてツールとして成り立つのかは不明ですが、URL・HTMLタグ・テキスト名を記述しターミナルにて実行するだけで取得、保存が可能なのでぜひ試してみください。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.8 |
| pip 9.0.1 |
| 使用ライブラリ | ライセンス |
|---|---|
| requests | Apache Software |
| bs4(beautifulsoup4) | MIT |
スクレイピングの注意事項¶
そもそもスクレイピングとは何か、それは擦り取るや削り取るといった意味を持ちIT界隈ではサイト内の欲しい情報を取得するといった意味になります。
ただし欲しい情報があるからといって闇雲にスクレイピングしていいとは限りません。
そのサイトに負荷を与えてしまったり、最悪相手側から訴えられる可能性も話題としてあります。なので欲しい情報があってもそのサイトの注意事項などをよく読み正しくスクレイピングを行いましょう。
準備¶
それでは準備をしていきます。まずはターミナルにてスクレイピングに使うモジュールをインストールします。
$ pip3 install requests
$ pip3 install bs4
requestsはサイトのURLを取得するためのモジュール、bs4とはBeautifulSoup4(ビューティフルスープ)の略で取得したURL内のHTML要素を操作するために使います。
インストールが完了しましたらPythonファイルを作成していきます。
Pythonファイルの作成¶
エディタを開きましたら次のように記述します。
ちなみに自身のサイトを持っていない方は、私のサイトでお試しください。
- https://zerofromlight.com/blogs
取得する前に予めブラウザにてサイトを検証し、拾ってきたいタグがあるかどうか確認し実行してください。
from bs4 import BeautifulSoup
import requests
"""URLを取得"""
gets = requests.get('https://zerofromlight.com/blogs')
"""bs4にてパーサーする(HTMLを公文表示させる)"""
soup = BeautifulSoup(gets.text, 'html.parser')
"""要素の格納用に空のリストを準備"""
airs = []
"""find_allでh5タグの要素を順番に全て取得し空リストに格納"""
for tag in soup.find_all('h5'):
print(tag.text)
airs.append(tag.text)
"""格納されたら保存用のファイルを開き保存し閉じる。
'at'にすることで上書きせず追記してくれる"""
for air in airs:
file = open('newtext.txt', 'at')
print(air, file=file)
file.close()
ターミナルにてPythonファイルを実行してください。
※ディレクトリに注意
そして開いたら
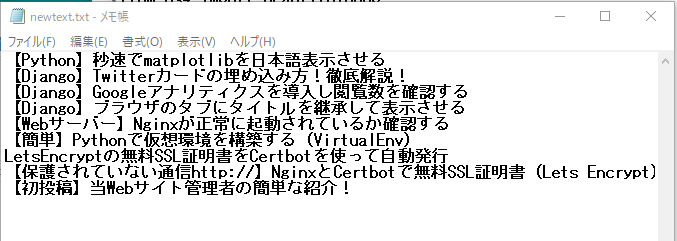
こちらはサイトをコピペして貼り付けたテキストです。
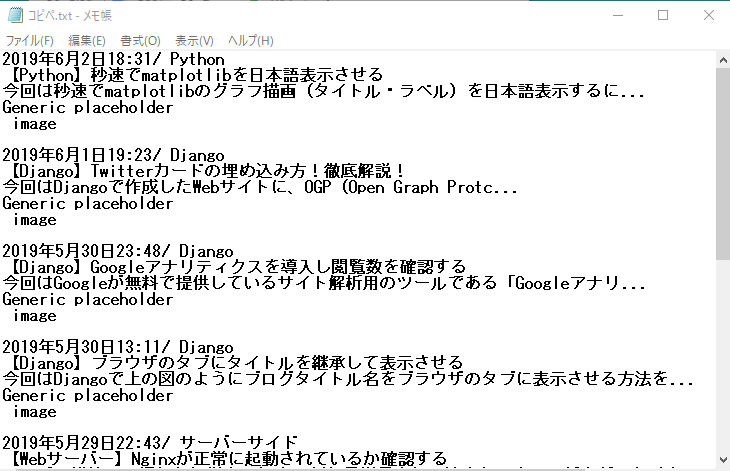
見ての通り余計な要素までコピーしてしまいます。
応用次第ではもっと効率的に欲しい要素を取得することができるでしょう。
単純で小さなスクレイピングツールはいかがでしたか?小さいだけに記事の規模も小さいです。
今回は極一部を紹介しましたが別の機会でpandasなどを使用した処理なども紹介していきたいと思います。
それでは以上になります。
最後までご覧いただきありがとうございました。