【Python】Googleアナリティクス4(GA4)のAPIを使ってアナリティクスデータを取得する
投稿日 2023年12月22日 >> 更新日 2024年2月11日
概要
今回はGoogleアナリティクス4のAPIモジュールを使用して、アナリティクスデータを取得していきます。
APIモジュールでは、単純に1~10までのデータを取得できるほか、5~9間のデータや、1~4と10のデータのように「フィルター」をかけてデータを取得することができるので、余計なデータを取得せずに済んだりします。
恐らく取得してきたデータを「pandas」等のデータ分析ツールでテーブル化させたいと思うので、その辺りの実装も少しだけ行いたいと思います。
APIモジュールを使用するためには認証情報の取得や各種設定が必要なので、設定していない場合はこちら「【Googleアナリティクス4(GA4)】Google Analytics Data API v1の各種設定と実装」をご参照ください。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| 使用ライブラリ | ライセンス |
|---|---|
| google-analytics-data==0.12.1 | Apache 2.0 |
実装前の準備¶
Googleアナリティクス4のAPIモジュールをインストールしていきます。
APIモジュールを使用するためには認証情報の取得や各種設定が必要なので、設定していない場合はこちら「【Googleアナリティクス4(GA4)】Google Analytics Data API v1の各種設定と実装」をご参照ください。
インストール手順の公式リファレンスはこちらです。
$ pip install google-analytics-data
インストールされていることを確認します。
$ pip show google-analytics-data
Name: google-analytics-data
Version: 0.12.1
Summary: None
Home-page: https://github.com/googleapis/python-analytics-data
Author: Google LLC
Author-email: googleapis-packages@google.com
License: Apache 2.0
Location: /mnt/c/Users/name/Documents/venv/lib/python3.6/site-packages
Requires: protobuf, proto-plus, google-api-core
アナリティクスデータの取得¶
アナリティクスデータの取得方法はこちらのGoogle公式ドキュメントにあるサンプルコードを参考にしています。
以下は参考にしたサンプルコードの簡易版です。
実際にアナリティクスデータを取得するための雛形だと思って覚えてしまうと良いと思います。
# googleドキュメントのサンプルコード
from google.analytics.data_v1beta import BetaAnalyticsDataClient
from google.analytics.data_v1beta.types import (
DateRange,
Dimension,
Metric,
RunReportRequest,
)
def run_sample():
property_id = "ご自身のGoogleアナリティクス4のプロパティID"
run_report(property_id)
def run_report(property_id="YOUR-GA4-PROPERTY-ID"):
client = BetaAnalyticsDataClient()
# レスポンス定義の内容
# dimensionsには日付を定義
# metricsにはアクティブユーザーを定義
# date_rangesには昨日から過去7日間
# 上記を合わせると、日付に分けてアクティブユーザー数の過去7日間のレポートを取得
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="date")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="7daysAgo", end_date="yesterday")]
)
response = client.run_report(request)
print(type(response)
print()
print(response)
# 実行
run_sample()
<class 'google.analytics.data_v1beta.types.analytics_data_api.RunReportResponse'>
dimension_headers {
name: "date"
}
metric_headers {
name: "activeUsers"
type_: TYPE_INTEGER
}
rows {
dimension_values {
value: "20240131"
}
metric_values {
value: "427"
}
}
rows {
dimension_values {
value: "20240202"
}
metric_values {
value: "426"
}
}
rows {
...
}
row_count: 8
metadata {
currency_code: "JPY"
time_zone: "Asia/Tokyo"
}
kind: "analyticsData#runReport"
上記レポートの戻り値は、JSON形式のようなインスタンス変数となっています。
辞書で言うところのキーとなっているところは属性値となっており、直接アクセスすることができます。
print(response.dimension_headers)
# [name: "date"]
print(response.dimension_headers[0].name)
# date
どのようにしてレスポンスを定義していくかと言うと、run_report関数内にあるRunReportRequestクラスの各パラメータ引数にリクエストを送りたい値の入ったインスタンスオブジェクトを渡します。
from google.analytics.data_v1beta.types import (
DateRange,
Dimension,
Metric,
RunReportRequest,
)
...
def run_report(property_id="YOUR-GA4-PROPERTY-ID"):
client = BetaAnalyticsDataClient()
# レスポンス定義の内容
# dimensionsには日付を定義
# metricsにはアクティブユーザーを定義
# date_rangesには昨日から過去7日間
# 上記を合わせると、日付に分けてアクティブユーザー数の過去7日間のレポートを取得
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="date")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="7daysAgo", end_date="today")]
)
操作をする部分は主に、「dimensions」「metrics」「date_ranges」の引数となります。
フィルターをかける要素もありますがそれは後半で実装します。
それぞれのパラメータ引数にはリストでインスタンオブジェクトを渡す必要があり、それぞれのオブジェクトは事前にインポートして使用します。
from google.analytics.data_v1beta.types import (
DateRange,
Dimension,
Metric,
RunReportRequest,
)
...
def run_report(property_id="YOUR-GA4-PROPERTY-ID"):
...
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="date")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="7daysAgo", end_date="today")]
)
Dimensionsクラスに渡している「date」やMetricクラスに渡している「activeUsers」という名前はどこを参考にしているかと言うと、Google公式ドキュメントの「API のディメンションと指標」からです。
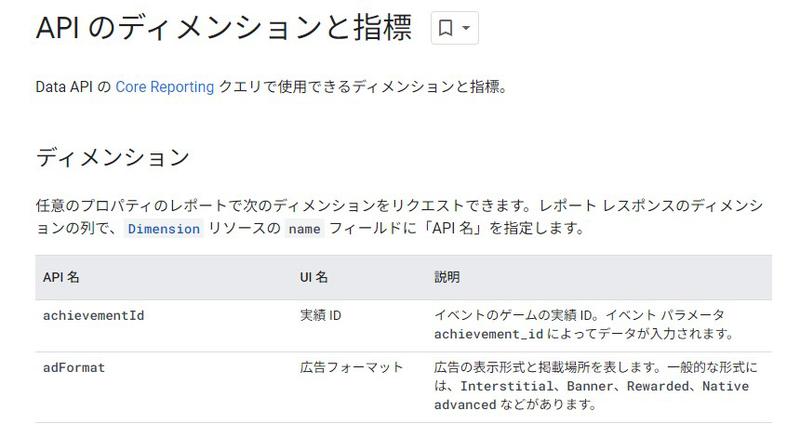
各一覧表のAPI名を選んで、各パラメータ引数のリストに定義することで特定のアナリティクスデータを取得することができます。
dimensionsやmetricsに与えられるインスタンスオブジェクトは、互換性があえば複数渡しても可能です。
例えば以下は、ディメンションに「日付(date)」と「国(country)」を定義し、メトリックには「アクティブユーザー(activeUsers)」と「新規ユーザー(NewUsers)」を定義してリクエストを送っています。
def run_report(property_id="YOUR-GA4-PROPERTY-ID"):
"""Runs a report of active users grouped by country."""
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[
Dimension(name="date"),
Dimension(name="country")
],
metrics=[
Metric(name="activeUsers"),
Metric(name="NewUsers")
],
date_ranges=[DateRange(start_date="2024-02-01", end_date="2024-02-02")],
)
response = client.run_report(request)
print(
response.dimension_headers[0].name,
'|',
response.dimension_headers[1].name,
'|',
response.metric_headers[0].name,
'|',
response.metric_headers[1].name
)
print('---------------------------')
for row in response.rows:
print(
row.dimension_values[0].value,
'|',
row.dimension_values[1].value,
'|',
row.metric_values[0].value,
'|',
row.metric_values[1].value
)
# 実行
run_sample()
date | country | activeUsers | NewUsers
---------------------------
20240202 | Japan | 422 | 349
20240201 | Japan | 420 | 340
20240201 | United States | 2 | 1
20240202 | United States | 2 | 2
20240201 | Botswana | 1 | 1
20240201 | China | 1 | 0
20240202 | Canada | 1 | 1
20240202 | China | 1 | 1
2024年2月1日~2月2日間の日付と国でグループ化されたアクティブユーザー数と新規ユーザー数のデータを取得しました。
レスポンスを受け取った際のデータ抽出¶
アナリティクスのリクエストを送ったらRunReportResponseというレスポンスオブジェクトを受け取ります。
戻り値はGoogleアナリティクス公式ドキュメントの「レスポンスを読む」でも書いている通り、JSON表現なデータ形式となっています。
以下はディメンションに「国」、メトリックに「アクティブユーザー」を設定したリクエストで返ってきたレスポンスの中身です。
// ドキュメントから一部抜粋
{
"dimensionHeaders": [
{
"name": "country"
}
],
"metricHeaders": [
{
"name": "activeUsers",
"type": "TYPE_INTEGER"
}
],
"rows": [
{
"dimensionValues": [
{
"value": "Japan"
}
],
"metricValues": [
{
"value": "2541"
}
]
},
],
"metadata": {},
"rowCount": 2
}
上記のコードを見る限りJSON形式ということで、Pythonでは辞書型として処理されるので、キーバリューと言う形で値を取得すると思います。
# json形式の例
import json
js_text = """{"dimensionHeaders":[{"name":"country"}]}"""
js_data = json.loads(js_text)
print(type(js_data))
print(js_data['dimensionHeaders'][0]['name'])
<class 'dict'>
country
しかしRunReportResponseオブジェクトから生成されるインスタンスオブジェクトでは、キー名で値を取得するのではなく、属性名として値を取得します。
# レスポンスオブジェクトの例
...
response = client.run_report(request)
print(type(response))
print(response.dimensionHeaders[0].name)
<class 'google.analytics.data_v1beta.types.analytics_data_api.RunReportResponse'>
country
属性にアクセスするとシーケンス型として取得されるので、リストのような扱いができます。
# 例
...
response = client.run_report(request)
print(
response.dimensionHeaders[0].name,
':',
response.metricHeaders[0].name
)
print('------------------------')
for row in response.rows:
print(
row.dimensionValues[0].value,
':',
row.metricValues[0].value
)
country : activeUsers
------------------------
Japan : 2185
以下はPython標準ライブラリにある「inspect」モジュールを使用して、レスポンスオブジェクトの詳細情報を取得した内容です。各属性についての説明を得られます。
import inspect
print(inspect.getdoc(response))
The response report table corresponding to a request.
Attributes:
dimension_headers (Sequence[google.analytics.data_v1beta.types.DimensionHeader]):
Describes dimension columns. The number of
DimensionHeaders and ordering of
DimensionHeaders matches the dimensions present
in rows.
metric_headers (Sequence[google.analytics.data_v1beta.types.MetricHeader]):
Describes metric columns. The number of
MetricHeaders and ordering of MetricHeaders
matches the metrics present in rows.
rows (Sequence[google.analytics.data_v1beta.types.Row]):
Rows of dimension value combinations and
metric values in the report.
totals (Sequence[google.analytics.data_v1beta.types.Row]):
If requested, the totaled values of metrics.
maximums (Sequence[google.analytics.data_v1beta.types.Row]):
If requested, the maximum values of metrics.
minimums (Sequence[google.analytics.data_v1beta.types.Row]):
If requested, the minimum values of metrics.
row_count (int):
The total number of rows in the query result. ``rowCount``
is independent of the number of rows returned in the
response, the ``limit`` request parameter, and the
``offset`` request parameter. For example if a query returns
175 rows and includes ``limit`` of 50 in the API request,
the response will contain ``rowCount`` of 175 but only 50
rows.
To learn more about this pagination parameter, see
`Pagination <https://developers.google.com/analytics/devguides/reporting/data/v1/basics#pagination>`__.
metadata (google.analytics.data_v1beta.types.ResponseMetaData):
Metadata for the report.
property_quota (google.analytics.data_v1beta.types.PropertyQuota):
This Analytics Property's quota state
including this request.
kind (str):
Identifies what kind of resource this message is. This
``kind`` is always the fixed string
"analyticsData#runReport". Useful to distinguish between
response types in JSON.
フィルタリングをして特定のデータを取得する¶
フィルタリングを使用して不要なデータを取り除いたりすることができます。
ディメンション値やメトリック値にそれぞれフィルターをかけることができ、それぞれ1つ1つの値にフィルターかけることができます。
例として、ディメンション値である「country」に対してフィルターを設定してみます。
必要なフィルタークラスをインポートして、RunReportRequestクラスのパラメータ引数に定義します。
※以下のコードは必要な部分だけにフォーカスしています
from google.analytics.data_v1beta.types import (
DateRange,
Dimension,
Filter, # 追加
FilterExpression, # 追加
Metric,
RunReportRequest,
)
...
def run_report(property_id):
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="country")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="7daysAgo", end_date="yesterday")],
# ディメンション値に対してフィルターをかける
dimension_filter=FilterExpression(
filter=Filter(
field_name="country",
string_filter=Filter.StringFilter(
value='Japan',
),
)
),
)
response = client.run_report(request)
print(
response.dimension_headers[0].name,
':',
response.metric_headers[0].name
)
print('--------------------')
for row in response.rows:
print(
row.dimension_values[0].value,
':',
row.metric_values[0].value
)
# 実行
run_sample()
country : activeUsers
--------------------
Japan : 2164
上記の結果は、ディメンション値である「国(country)」に対してフィルターをかけています。
以下のように、ディメンションに対してのフィルターだったら「dimension_filter」引数を設定し、どのディメンション値で絞り込むかは「field_name」引数で指定します。
# 一部抜粋
...
def run_report(property_id):
...
request = RunReportRequest(
...
dimensions=[Dimension(name="country")],
...
...
dimension_filter=FilterExpression(
filter=Filter(
field_name="country",
string_filter=Filter.StringFilter(
value='Japan',
),
)
),
)
「string_filter」引数に設定している「StringFilter」は文字列によってフィルタリングを行うことができるので、「value」引数には「日本(Japan)」と指定し、「日本」のデータ以外は取り除かれて取得することができています。
もちろん逆の動作も実行することができます。
「日本」以外のデータを取得したい場合は、FilterExpressionクラスの「not_expression」引数にFilterクラスを与えます。
以下は「not_expression」引数を追加しただけの例です。
def run_report(property_id):
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="country")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="7daysAgo", end_date="yesterday")],
# ディメンション値に対してフィルターをかける
# dimension_filter=FilterExpression(
# filter=Filter(
# field_name="country",
# string_filter=Filter.StringFilter(
# value='Japan',
# ),
# )
# ),
# FilterExpressionにnot_expression引数を追加
dimension_filter=FilterExpression(
not_expression=FilterExpression(
filter=Filter(
field_name="country",
string_filter=Filter.StringFilter(
value="Japan"
)
)
)
)
)
response = client.run_report(request)
print(
response.dimension_headers[0].name,
':',
response.metric_headers[0].name
)
print('--------------------')
for row in response.rows:
print(
row.dimension_values[0].value,
':',
row.metric_values[0].value
)
# 実行
run_sample()
country : activeUsers
--------------------
United States : 14
Australia : 4
Canada : 4
China : 2
India : 2
...
FilterExpressionクラスの引数「not_expression」を定義するだけで、指定した要素のみを取り除くことができます。
これまで使用したフィルターは「StringFilter」といって、文字列に特化したフィルタークラスになります。
ディメンション値やメトリック値によって文字列や整数、日付といった要素で取得されるので、それぞれの型に対応したフィルタークラスが用意されています。
BetweenFilterクラスでnからnまでの間隔に対するフィルターをかける¶
BetweenFilterクラスはメトリック値の整数や浮動小数点数に対してフィルタリングすることができます。
Filterクラスに与える引数は「Filter(between_filter=Filter.BetweenFIlter())」とします。
BetweenFilter(from_value, to_value)という必須の引数があり、開始(from_value)から終わり(to_value)までの数字を設定することができます。
BetweenFilterクラスの引数に渡す値は、NumericValueクラスのインスタンスオブジェクトで渡す必要があります。
以下はメトリック値の「アクティブユーザー数」に対してフィルタリングを実装している例です。
from google.analytics.data_v1beta.types import (
DateRange,
Dimension,
Filter,
FilterExpression,
Metric,
RunReportRequest,
NumericValue # 追加
)
...
def run_report(property_id):
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="pageTitle")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="7daysAgo", end_date="yesterday")],
# メトリックに対してのフィルター
# アクティブユーザー数が100~200までにある数を取得する
metric_filter=FilterExpression(
filter=Filter(
field_name="activeUsers",
between_filter=Filter.BetweenFilter(
from_value=NumericValue(int64_value=100),
to_value=NumericValue(int64_value=200)
),
)
),
)
response = client.run_report(request)
print(
response.dimension_headers[0].name,
':',
response.metric_headers[0].name
)
print('--------------------')
for row in response.rows:
print(
row.dimension_values[0].value,
':',
row.metric_values[0].value
)
# 実行
run_sample()
pageTitle : activeUsers
--------------------
【Python】文字コードを把握してEncode(エンコード)・Decode(デコード)エラーを回避する : 177
【Python】CSVファイル読み込み時のヘッダー(列名)有り無し処理について : 146
【Webサーバー】Nginxが正常に起動されているか確認する : 110
ページタイトルに対してのアクティブユーザー数が100から200の間でカウントされているデータを取得しています。
InListFilterクラスでリストによるフィルターをかける¶
InListFilterクラスはディメンション値の文字列に対してフィルタリングすることができます。
Filterクラスに与える引数は「Filter(in_list_filter=Filter.InListFIlter())」とします。
InListFilter(values, case_sensitive=False)という引数があり、「values」の引数にはリストを渡し、「case_sensitive」の引数はブール値としてデフォルトでFalse値が設定されています。False値ではリストに与えられた文字列に対して大文字小文字問わずデータを抽出できます。True値では完全一致となります。
以下はディメンション値の「ページタイトル(pageTitle)」に対してフィルタリングを実装している例です。
from google.analytics.data_v1beta.types import (
DateRange,
Dimension,
Filter,
FilterExpression,
Metric,
RunReportRequest,
)
...
def run_report(property_id):
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="pageTitle")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="7daysAgo", end_date="yesterday")],
# ディメンション値にフィルターをかける
# リストに指定されているページタイトルのデータを抽出する
dimension_filter=FilterExpression(
filter=Filter(
field_name="pageTitle",
in_list_filter=Filter.InListFilter(
values=[
"blog",
"【webサーバー】Nginxが正常に起動されているか確認する"
],
case_sensitive=False # デフォルトで大文字小文字問わない
),
)
)
)
response = client.run_report(request)
print(
response.dimension_headers[0].name,
':',
response.metric_headers[0].name
)
print('--------------------')
for row in response.rows:
print(
row.dimension_values[0].value,
':',
row.metric_values[0].value
)
# 実行
run_sample()
pageTitle : activeUsers
--------------------
【Webサーバー】Nginxが正常に起動されているか確認する : 110
Blog : 6
リストに指定した「blog」「【webサーバー】Nginxが正常に起動されているか確認する」のページタイトルであるデータを取得しています。
NumericFilterクラスで整数または日付によるフィルターをかける¶
NumericFilterクラスはディメンション値とメトリック値の整数や日付に対してフィルタリングすることができます。
Filterクラスに与える引数は「Filter(numeric_filter=Filter.NumericFIlter())」とします。
NumericFilter(operation=Filter.NumericFilter.Operation(0 ro 1), value)という引数があり、「operation」の引数にはOperationクラスのインスタンスオブジェクトを渡し、「value」の引数はBetweenFilterクラスの時と同様にNumericValueクラスオブジェクトのインスタンスを与えます。「operation」引数では、「value」の振る舞いをコントロールすることができ、デフォルト値では何もしない設定となっています。
以下はディメンション値の「日付(date)」に対して、デフォルトの「operation」引数でフィルタリングを実装している例です。
from google.analytics.data_v1beta.types import (
DateRange,
Dimension,
Filter,
FilterExpression,
Metric,
RunReportRequest,
NumericValue # 追加
)
...
def run_report(property_id):
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="date")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="2024-02-01", end_date="2024-02-09")],
# ディメンション値かメトリック値にフィルターをかける
# 2024年2月7日のデータを取得
dimension_filter=FilterExpression(
filter=Filter(
field_name="date",
numeric_filter=Filter.NumericFilter(
value=NumericValue(int64_value=20240207)
),
)
)
)
response = client.run_report(request)
print(
response.dimension_headers[0].name,
':',
response.metric_headers[0].name
)
print('--------------------')
for row in response.rows:
print(
row.dimension_values[0].value,
':',
row.metric_values[0].value
)
# 実行
run_sample()
date : activeUsers
--------------------
20240207 : 421
整数型の日付(20240207)によってフィルタリングされたデータを取得しました。
NumericFilterクラスの「operation」引数のデフォルトでは、「operation=Filter.NumericFilter.Operation(0 or 1)」により操作が「未指定」もしくは「等しい」となっていたので、「value」で指定された要素のみ取得されましたが、Operationクラスに特定の整数を与える事で「value」引数の振る舞いを操作することができます。
以下はOperationクラスの操作表です。
| operatioin | 日本語 | 割り当て数字 |
|---|---|---|
| OPERATION UNSPECIFIED | 操作未指定 | 0 |
| EQUAL | 等しい | 1 |
| LESS THAN | 未満 | 2 |
| LESS THAN_OR_EQUAL | 以下 | 3 |
| GREATER THAN | より大きい | 4 |
| GREATER THAN OR EQUAL | 以上 | 5 |
以下はディメンション値の「日付(date)」に対して、2024年2月7日よりも過去のデータをフィルタリングしている例です。
...
def run_report(property_id):
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="date")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="2024-02-01", end_date="2024-02-09")],
# オペレーション「2」に従って、20240207未満の日付データを抽出する
dimension_filter=FilterExpression(
filter=Filter(
field_name="date",
numeric_filter=Filter.NumericFilter(
operation=Filter.NumericFilter.Operation(2),
value=NumericValue(int64_value=20240207)
),
)
)
)
response = client.run_report(request)
print(
response.dimension_headers[0].name,
':',
response.metric_headers[0].name
)
print('--------------------')
for row in response.rows:
print(
row.dimension_values[0].value,
':',
row.metric_values[0].value
)
# 実行
run_sample()
date : activeUsers
--------------------
20240202 : 426
20240201 : 424
20240206 : 400
20240205 : 394
20240204 : 162
20240203 : 152
「data_ranges」で設定した2024年2月1日~2月9日の範囲から、2月7日より過去のデータをフィルタリングして取得しています。
StringFilterクラスで文字列によるフィルターをかける¶
StringFilterクラスはディメンション値の文字列に対してフィルタリングすることができます。
Filterクラスに与える引数は「Filter(string_filter=Filter.StringFIlter())」とします。
StringFilter(match_type=Filter.StringFilter.MatchType(0 or 1), value, case_sensitive=False)という引数があり、「match_type」の引数にはMatchTypeクラスのインスタンスオブジェクトを渡し、「value」の引数は文字列を与えます。「match_type」引数では、「value」文字列の振る舞いをコントロールすることができ、デフォルト値では「未指定」もしくは「正確」の設定となっています。
以下はディメンション値の「ページタイトル(pageTitle)」に対して、デフォルトの「match_type」引数でフィルタリングを実装している例です。
from google.analytics.data_v1beta.types import (
DateRange,
Dimension,
Filter,
FilterExpression,
Metric,
RunReportRequest,
)
...
def run_report(property_id):
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="pageTitle")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="7daysAgo", end_date="yesterday")],
# ディメンション値にフィルターをかける
# 正確に一致した文字列からデータを抽出
dimension_filter=FilterExpression(
filter=Filter(
field_name="pageTitle",
string_filter=Filter.StringFilter(
value='【Webサーバー】Nginxが正常に起動されているか確認する',
),
)
),
)
response = client.run_report(request)
print(
response.dimension_headers[0].name,
':',
response.metric_headers[0].name
)
print('--------------------')
for row in response.rows:
print(
row.dimension_values[0].value,
':',
row.metric_values[0].value
)
# 実行
run_sample()
pageTitle : activeUsers
--------------------
【Webサーバー】Nginxが正常に起動されているか確認する : 110
ページタイトルに対して、正確に当てはまった文字列からデータを取得しました。
StringFilterクラスの「match_type」引数のデフォルトでは、「match_type=Filter.StringFilter.MatchType(0 or 1)」により操作が「未指定」もしくは「正確」となっていたので、「value」で指定された通りの要素のみ取得されましたが、MatchTypeクラスに特定の整数を与える事で「value」引数の振る舞いを操作することができます。
以下はMatchTypeクラスの操作表です。
| match type | 日本語 | 割り当て数字 |
|---|---|---|
| MATCH TYPE UNSPECIFIED | 一致タイプが指定されていません | 0 |
| EXACT | 正確 | 1 |
| BEGINS WITH | で始まる | 2 |
| ENDS WITH | で終わる | 3 |
| CONTAINS | 含む | 4 |
| FULL REGEXP | 完全な正規表現 | 5 |
| PARTIAL REGEXP | 部分的な正規表現 | 6 |
以下はディメンション値の「ページタイトル(pageTitle)」に対して、「【w」で始まるデータをフィルタリングしている例です。
...
def run_report(property_id):
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="pageTitle")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="7daysAgo", end_date="yesterday")],
# MatchType(2)で「【w」から始まるデータを抽出
dimension_filter=FilterExpression(
filter=Filter(
field_name="pageTitle",
string_filter=Filter.StringFilter(
match_type=Filter.StringFilter.MatchType(2),
value='【w',
),
)
),
)
response = client.run_report(request)
print(
response.dimension_headers[0].name,
':',
response.metric_headers[0].name
)
print('--------------------')
for row in response.rows:
print(
row.dimension_values[0].value,
':',
row.metric_values[0].value
)
# 実行
run_sample()
pageTitle : activeUsers
--------------------
【Webサーバー】Nginxが正常に起動されているか確認する : 110
【Windows10 Home】WSL1からWSL2に切り替える : 22
【Webサイト・サーバー】運用時に使うLinuxコマンド集 : 7
【Webサイト】413 Request Entity Too Large スマホからファイルアップロード時のエラー対策 : 5
【WSL1】pyenvの導入と使用例 : 1
【WSL】Django2.2からmysqlclientを導入した際のエラー&成功例 : 1
MatchType(2)の「~で始まる」に設定した通り、「【w」から始まるデータを取得しています。
次の例は、ディメンション値の「ページタイトル(pageTitle)」に対して、文字列と部分的な正規表現でフィルタリングしている例です。
...
def run_report(property_id):
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="pageTitle")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="7daysAgo", end_date="yesterday")],
# MatchType(6)で「【w」と(|)「【p」から始まるデータを部分的な正規表現で抽出
dimension_filter=FilterExpression(
filter=Filter(
field_name="pageTitle",
string_filter=Filter.StringFilter(
match_type=Filter.StringFilter.MatchType(6),
value='^【w|^【p',
),
)
),
)
response = client.run_report(request)
print(
response.dimension_headers[0].name,
':',
response.metric_headers[0].name
)
print('--------------------')
for row in response.rows:
print(
row.dimension_values[0].value,
':',
row.metric_values[0].value
)
# 実行
run_sample()
pageTitle : activeUsers
--------------------
【Python】文字コードを把握してEncode(エンコード)・Decode(デコード)エラーを回避する : 177
【Python】CSVファイル読み込み時のヘッダー(列名)有り無し処理について : 148
【Webサーバー】Nginxが正常に起動されているか確認する : 113
【Python】coverageモジュールを使ってテストのカバー率を上げる : 79
【Python】音声認識ライブラリのSpeechRecognitionでサクッと文字起こし : 79
【Python】Matplotlibで画像を読み込んでプロットする : 61
...
MatchType(6)の「部分的な正規表現」に設定した通り、「【w」から始まる文字列と「【p」から始まる文字列のデータを取得しています。
次の例は、ディメンション値の「ページパス(pagePath)」に対して、完全な正規表現でフィルタリングしている例です。
...
def run_report(property_id):
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="pagePath")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="7daysAgo", end_date="yesterday")],
# MatchType(5)で「/文字列/文字列/整数/」のデータを正規表現で抽出
dimension_filter=FilterExpression(
filter=Filter(
field_name="pagePath",
string_filter=Filter.StringFilter(
match_type=Filter.StringFilter.MatchType(6),
value='/\w*/\w*/\d*/'
),
)
),
)
response = client.run_report(request)
print(
response.dimension_headers[0].name,
':',
response.metric_headers[0].name
)
print('--------------------')
for row in response.rows:
print(
row.dimension_values[0].value,
':',
row.metric_values[0].value
)
# 実行
run_sample()
pagePath : activeUsers
--------------------
/blogs/detail/89/ : 177
/blogs/detail/77/ : 148
/blogs/detail/5/ : 113
/blogs/detail/128/ : 79
/blogs/detail/137/ : 79
/blogs/detail/107/ : 71
/blogs/detail/116/ : 61
/blogs/detail/98/ : 61
...
MatchType(5)の「/文字列/文字列/整数/」に設定した通り、「/blogs/detail/番号/」のデータを取得しています。
複数のフィールドをグループ化してフィルタリングする¶
複数のフィールドが存在する場合、例えばディメンションに「ページパス(pagePath)」と「ページタイトル(pageTitle)」があり、それぞれにフィルターをかけたい場合がある。
そんな時には「グループ化」してフィルタリングことができます。
FilterExpressionクラスの引数「and_group」と「or_group」を定義することができ、その引数にはFilterExpressionListクラスのインスタンスオブジェクトを渡します。
FilterExpressionList(expressions)引数にはフィルタークラスのインスタンスオブジェクトが渡されたFilterExpressionオブジェクトのインスタンオブジェクトをリストで渡します。
以下はディメンション値の「ページパス(pagePath)」と「ページタイトル(pageTitle)」の両方に対してフィルタリングしている例です。
from google.analytics.data_v1beta.types import (
DateRange,
Dimension,
Filter,
FilterExpression,
FilterExpressionList, # 追加
Metric,
RunReportRequest,
)
...
def run_report(property_id):
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[Dimension(name="pagePath"), Dimension(name="pageTitle")],
metrics=[Metric(name="activeUsers")],
date_ranges=[DateRange(start_date="7daysAgo", end_date="yesterday")],
# ディメンション値にフィルターをかける
# 文字列フィルターの部分的な正規表現でデータを抽出
dimension_filter=FilterExpression(
and_group=FilterExpressionList(
expressions=[
# ページパスに対してのフィルター
FilterExpression(
filter=Filter(
field_name="pagePath",
string_filter=Filter.StringFilter(
match_type=Filter.StringFilter.MatchType(6),
value="/blogs/detail/\d{2}/" # \d{2}=2桁
),
)
),
# ページタイトルに対してのフィルター
FilterExpression(
filter=Filter(
field_name="pageTitle",
string_filter=Filter.StringFilter(
match_type=Filter.StringFilter.MatchType(6),
value="^【Python" # 【Pythonから始まるデータ
),
)
),
]
),
),
)
response = client.run_report(request)
print(
response.dimension_headers[0].name,
':',
response.dimension_headers[1].name,
':',
response.metric_headers[0].name
)
print('--------------------')
for row in response.rows:
print(
row.dimension_values[0].value,
':',
row.dimension_values[1].value,
':',
row.metric_values[0].value
)
# 実行
run_sample()
pagePath : pageTitle : activeUsers
--------------------
/blogs/detail/89/ : 【Python】文字コードを把握してEncode(エンコード)・Decode(デコード)エラーを回避する : 177
/blogs/detail/77/ : 【Python】CSVファイル読み込み時のヘッダー(列名)有り無し処理について : 148
/blogs/detail/98/ : 【Python】Matplotlibで画像を読み込んでプロットする : 61
/blogs/detail/97/ : 【Python】Matplotlibで図中に複数のグラフを描画する : 52
/blogs/detail/56/ : 【Python】MeCab(形態素解析器)を使用して文章をカテゴリー分類する : 38
/blogs/detail/53/ : 【Python】簡単なコードで人工無能(チャットボット)の実装 : 37
/blogs/detail/99/ : 【Python】Matplotlibでグラフのリアルタイム(アニメーション)描画を実装する : 29
/blogs/detail/91/ : 【Python】チャットボットフレームワーク、ChatterBotの実装 : 28
/blogs/detail/55/ : 【Python】形態素解析器のMeCabを使って自然言語処理の実装 : 13
...
ページパスの番号部分を2桁、ページタイトルの先頭が「【Python」から始まる文字列の両方でフィルタリングしてデータを取得しました。
「or_group」に関しては、FilterExpressionList(expressions)引数のリスト内において、どちらかが当てはまればフィルタリングが実行される仕組みです。
pandasを使って取得したデータをデータフレームに変換する¶
pandasは外部パッケージとなるので、使用する場合はインストールしておきます。
以下の例は、ディメンション値に「日付(date)」、メトリック値に「アクティブユーザー(activeUsers)」「新規ユーザー(NewUsers)」「広告クリック数(publisherAdClicks)」「広告インプレッション数(publisherAdImpressions)」を設定して取得されたデータをpandasのデータフレームに変換しています。
import pandas as pd
from google.analytics.data_v1beta import BetaAnalyticsDataClient
from google.analytics.data_v1beta.types import (
DateRange,
Dimension,
Metric,
RunReportRequest,
)
def run_sample():
property_id = "ご自身のGoogleアナリティクス4のプロパティID"
df = run_report(property_id)
return df
def run_report(property_id):
client = BetaAnalyticsDataClient()
request = RunReportRequest(
property=f"properties/{property_id}",
dimensions=[
Dimension(name="date"),
],
metrics=[
Metric(name="activeUsers"),
Metric(name="NewUsers"),
Metric(name="publisherAdClicks"),
Metric(name="publisherAdImpressions")
],
date_ranges=[DateRange(start_date="2024-2-1", end_date="2024-2-9")],
)
response = client.run_report(request)
res_dict = {}
# ディメンション値のキーバリューを作成
# {'dimension_header':['dimension_value', 'dimension_value', ...]}
for i, row in enumerate(response.dimension_headers):
res_dict[row.name] = [row.dimension_values[i].value for row in response.rows]
# メトリック値のキーバリューを作成
# {'metric_header':['metric_value', 'metric_value', ...]}
for i, row in enumerate(response.metric_headers):
res_dict[row.name] = [row.metric_values[i].value for row in response.rows]
# データフレームの作成
df = pd.DataFrame(res_dict)
return df
run_sample関数とrun_report関数にreturn文を追記して、run_report関数内で作成しているデータフレームが戻り値として格納されるようにします。
変数にデータフレームを代入します。
df = run_sample()
df.head()
date activeUsers NewUsers publisherAdClicks publisherAdImpressions
0 20240202 426 353 3 2207
1 20240201 424 342 3 2062
2 20240207 421 346 8 2209
3 20240209 416 343 4 1955
4 20240206 400 329 1 1987
「date」列の順番がバラバラなので下に向かって小さい順に並べ替えます。
df_date_sort = df.sort_values('date').reset_index(drop=True)
df.head()
date activeUsers NewUsers publisherAdClicks publisherAdImpressions
0 20240201 424 342 3 2062
1 20240202 426 353 3 2207
2 20240203 152 124 2 718
3 20240204 162 133 0 835
4 20240205 394 335 4 2157
最後にcsvファイルとして保存します。
df_date_sort.to_csv('ga4_20240201_20240209.csv')
終わりに¶
今回はGoogleアナリティクス4のAPIを使用してデータの取得に必要な機能などを実装しました。
機能としてはフィルター以外に、データの長さを操作する機能や期間を比較するための複数期間を同時に取得できる機能があります。
それでは以上となります。
最後までご覧いただきありがとうございました。