【Python-Markdown】目次拡張機能を使ったカスタマイズ
投稿日 2022年1月14日 >> 更新日 2023年3月1日
概要
ここではPython-Markdownモジュールの拡張機能である「toc(Table of Contents)」について実装する。
以下のような方の記事
-
目次をドキュメント内ではなく他の部分に挿入したい。
-
拡張機能の構成を設定するextension_configsについて
-
目次にタイトルを付けたい。
-
設定項目のslugifyで独自のスラッグを当てはめる
-
などなど...
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
| Jupyter Notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| Markdown==3.1.1 | BSD |
目次のデータだけ取得する¶
目次拡張機能を追加することによってドキュメント内に「[TOC]」と打てば以下の図の左側のようにHTMLの<h>...</h>タグをリストとした目次に変換してくれます。
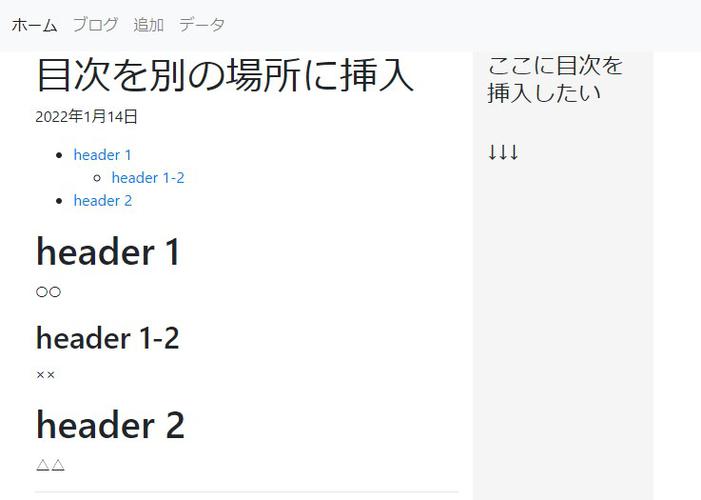
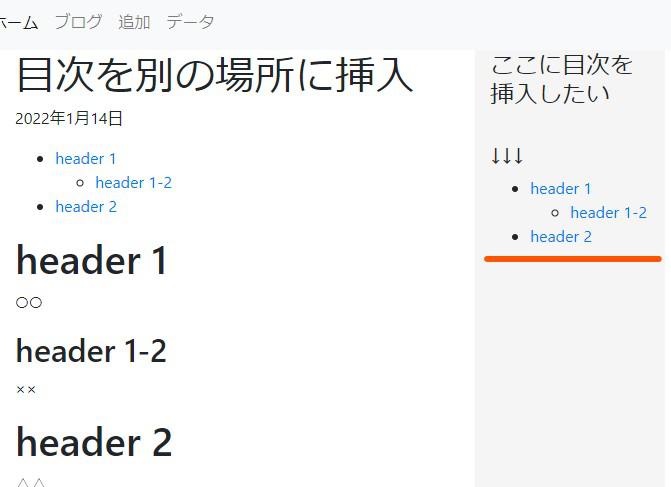
今回は以下のようにドキュメント内だけではなくサイドバーや他の場所に目次を配置させたいといった実装になります。
通常マークダウンされた文字列のテキストをHTMLに変換する際は以下のようにする。
import markdown
# from markdown.extensions.toc import TocExtension
text = """
[TOC]
# header 1
○○
## header 1-2
××
# header 2
"""
# tocは目次拡張機能
html = markdown.markdown(text, extensions=['toc'])
# or
# html = markdown.markdown(text, extensions=[TocExtension()])
print(html)
"""
<div class="toc">
<ul>
<li><a href="#header-1">header 1</a><ul>
<li><a href="#header-1-2">header 1-2</a></li>
</ul>
</li>
<li><a href="#header-2">header 2</a></li>
</ul>
</div>
<h1 id="header-1">header 1</h1>
<p>○○</p>
<h2 id="header-1-2">header 1-2</h2>
<p>××</p>
<h1 id="header-2">header 2</h1>
"""
上記のようにmarkdown関数にアクセスすることによりマークダウンをHTMLに変換することができました。
今回のように目次の部分だけ取り出すような細かい操作を行いたい場合はMarkdownクラスを使います。
import markdown
# オブジェクトを作成
md = markdown.Markdown(extensions=['toc'])
# インスタンスを生成
html = md.convert(text)
print('目次の部分')
print(md.toc)
print('ドキュメント')
print(html)
"""
目次の部分
<div class="toc">
<ul>
<li><a href="#header-1">header 1</a><ul>
<li><a href="#header-1-2">header 1-2</a></li>
</ul>
</li>
<li><a href="#header-2">header 2</a></li>
</ul>
</div>
ドキュメント
<div class="toc">
<ul>
<li><a href="#header-1">header 1</a><ul>
<li><a href="#header-1-2">header 1-2</a></li>
</ul>
</li>
<li><a href="#header-2">header 2</a></li>
</ul>
</div>
<h1 id="header-1">header 1</h1>
<p>○○</p>
<h2 id="header-1-2">header 1-2</h2>
<p>××</p>
<h1 id="header-2">header 2</h1>
"""
オブジェクトにテキストが渡された際に、値がmd.toc属性にアタッチされ目次の部分を取得できるようになります。
md.to_tokensとすると辞書型に生成された目次のデータも取得できます。
print(md.toc_tokens[0])
"""
{'level': 1, 'id': 'header-1', 'name': 'header 1', 'children': [{'level': 2, 'id': 'header-1-2', 'name': 'header 1-2', 'children': []}]}
"""
Markdownクラスに目次拡張機能が追加されていれば、ドキュメントに「[TOC]」と打たなくともクラスオブジェクトのtocもしくわtoc_tokens属性にアクセスすることで目次の部分のみ取得できます。
text_2 = """
# header 1
○○
## header 1-2
××
# header 2
"""
# オブジェクトを作成
md = markdown.Markdown(extensions=['toc'])
# インスタンスを生成
html_2 = md.convert(text_2)
print('目次の部分')
print(md.toc)
print('ドキュメント')
print(html_2)
"""
目次の部分
<div class="toc">
<ul>
<li><a href="#header-1">header 1</a><ul>
<li><a href="#header-1-2">header 1-2</a></li>
</ul>
</li>
<li><a href="#header-2">header 2</a></li>
</ul>
</div>
ドキュメント
<h1 id="header-1">header 1</h1>
<p>○○</p>
<h2 id="header-1-2">header 1-2</h2>
<p>××</p>
<h1 id="header-2">header 2</h1>
"""
ブログでよく見かけるイメージとしては以下のような感じになります。

右側にある目次を追随させることで、記事を読み返すのに便利そうです。
目次拡張機能の構成を変更する¶
拡張機能の構成を変更するには、Markdownクラスのextension_configsパラメータに要素を渡すか、extensionsパラメータにTocExtensionクラスを渡してTocExtensionパラメータから構成設定を変えるかです。
例えば目次拡張機能にタイトルを持たせるとするならば以下のように設定します。
extension_configsパラメータの場合
# 特定のキーに構成を設定した辞書を入れる
extension_configs = {
'toc': {
'title': 'Table of Contents'
}
}
md = markdown.Markdown(
extensions=['toc'],
extension_configs=extension_configs # 要素を渡す
)
TocExtensionパラメータの場合
from markdown.extensions.toc import TocExtension
md = markdown.Markdown(extensions=[
TocExtension(
title='table of contents', # タイトル デフォルトは「None」
)
])
いずれかの方法を使って構成設定を変えると、目次に「table of contents」とタイトルを持たせることができます。
text = """
# header1
## header1-2
# header2
"""
html = md.convert(text)
print('目次の部分')
print(md.toc)
"""
目次の部分
<div class="toc"><span class="toctitle">Table of Contents</span><ul>
<li><a href="#header1">header1</a><ul>
<li><a href="#header1-2">header1-2</a></li>
</ul>
</li>
<li><a href="#header2">header2</a></li>
</ul>
</div>
"""
目次拡張機能の構成設定の種類¶
| Key | Value |
|---|---|
| marker | デフォルト=[TOC]、マークダウンの記法を変更できる(例:[toc]など) |
| title | デフォルト=None、目次にタイトルを付けられる |
| anchorlink | デフォルト=False、各項目にアンカーリンクを設定 |
| anchorlink_class | アンカーリンクのCSSクラス名を変更できるがエラーとなってしまう。 |
| permalink | ドフォルト=False、各項目のパーマリンクを設定 |
| permalink_class | パーマリンクのCSSクラス名を変更できるがエラーとなってしまう。 |
| slugify | デフォルト=markdown.extensions.headerid.slugify(項目名にASCII以外の文字列は番号と記号に置き換えられる)、function(value, separator):の引数を持つ関数を定義して渡すことによって、アンカーリンクの名前を変更することできる。 |
| separator | デフォルト=「-」、区切り文字 |
| toc_depth | デフォルト=6、目次リストの階層を表示する深さ(子要素のリスト) |
スラッグ(Slug)の設定¶
スラッグとはURLの語尾(https://example.com/detail/100#slug)に当たる名前の事で、目次に割り当てられているアンカーリンク(<a href="#slug">)のことです。
注意
スラッグはSEO対策の一環として英単語にするのが望ましい。
〇:https://example.com/detail/100#slug
✕:https://example.com/detail/100#スラッグ
Markdownのデフォルトでは項目名がそのままスラッグとして割り当てられています。

日本語のような文字コードがASCII以外の項目名を付けると、その文字列は除外されるか、記号と番号によって割り振られます。

スラッグを設定するには、構成設定にある「slugify」に「value」と「separator」の引数を持つ関数を渡す必要があります。
text = """
[TOC]
# header1
## header1-2
# header2
"""
# slugifyキーに渡すための関数
# value=項目名、separator=記号
def my_slugify(value, separator):
return 'slug'
html = markdown.markdown(
text=text,
extensions=['toc'],
extension_configs={
'toc':{
'slugify': my_slugify # スラッグの設定
}
}
)
print(html)
"""
<div class="toc">
<ul>
<li><a href="#slug">header1</a><ul>
<li><a href="#slug_1">header1-2</a></li>
</ul>
</li>
<li><a href="#slug_2">header2</a></li>
</ul>
</div>
<h1 id="slug">header1</h1>
<h2 id="slug_1">header1-2</h2>
<h1 id="slug_2">header2</h1>
"""
アンカータグのhref属性が「#slug」に置き換わりました。
slugify用の関数を使っているので、ついでに「separator」の設定もしてみます。
text = """
[TOC]
# header1
## header1-2
# header2
"""
# valueおよびseparatorも合わせて戻す
def my_slugify(value, separator):
slug = value + separator + 'slug'
return slug
html = markdown.markdown(
text=text,
extensions=['toc'],
extension_configs={
'toc':{
'slugify': my_slugify,
'separator': '/' # 記号を変更
}
}
)
print(html)
"""
<div class="toc">
<ul>
<li><a href="#header1/slug">header1</a><ul>
<li><a href="#header1-2/slug">header1-2</a></li>
</ul>
</li>
<li><a href="#header2/slug">header2</a></li>
</ul>
</div>
<h1 id="header1/slug">header1</h1>
<h2 id="header1-2/slug">header1-2</h2>
<h1 id="header2/slug">header2</h1>
"""
他にもアンカーリンクやパーマリンクも各項目に付与することができまるので非常に便利な設定です。
以上です。
最後までご覧いただきありがとうございました。