【実践】データの取得から機械学習モデル(線形回帰とSVM:サポートベクトルマシン)に学習させて予測をしてみよう!
投稿日 2019年9月9日 >> 更新日 2024年7月9日
今回は、データサイエンティストが行っているような、データを取得して機械学習に予測させ結果を可視化させるといった内容を書いこう思います。
第1回目の実践型ということで、よりシンプルな流れとなっています。
データのクリーンアップや機械学習のパラメータ値などの設定は行わず、一連の流れだけに特化しています。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.8 |
| pip 9.0.1 |
| Jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| matplotlib==3.1.1 | PSF |
| numpy==1.17.0 | OSI Approved (new BSD) |
| pandas==0.25.0 | BSD |
| scikit-learn==0.21.3 | OSI Approved (new BSD) |
| seaborn==0.9.0 | BSD |
データの準備¶
ではすべてインポートしてしまいます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# ↓これを読み込むことによって、綺麗な軸線が入る
sns.set_style('whitegrid')
# ↓データセットが格納されている
from sklearn.datasets import fetch_california_housing
機械学習ライブラリのscikit-leaarnにはいくつかデータセットが格納されており簡単に読み込んで練習することができるので非常に便利です。
その中の1つである、カリフォルニアの住宅価格のデータセット(fetch_california_housing)を使って予測をしていきます。
変数にオブジェクトを入れる。
# 実行
housing = fetch_california_housing()
housing
housingと呼び出すとその中身の情報が見れます。


dataが予測に必要な説明変数でtargetがラベルである目的変数となります。
この分かれたデータを一度pandasを使って見やすくしてみましょう。
それぞれのデータを取得するには、housing.data(説明変数)とhousing.targetとして呼び出します。
pandasのデータフレームに格納して変数に渡します。
# ↓引数のcolumnsは列名にそれぞれ名前を与える
housing_data = pd.DataFrame(housing.data, columns=housing.feature_names)
housing_target = pd.DataFrame(housing.target, columns=['housing_price'])
最初のインデックス2行を取得
# 実行
housing_data.head(2)

# 実行
housing_target.head(2)

これらのデータフレームを結合して、全体の情報を細かく見ていきます。
# 実行
housing = housing_data.join(housing_target)
housing.head(2)

housing情報を取得
# 実行
housing.info()

housingの統計的な情報
# 実行
housing.describe()
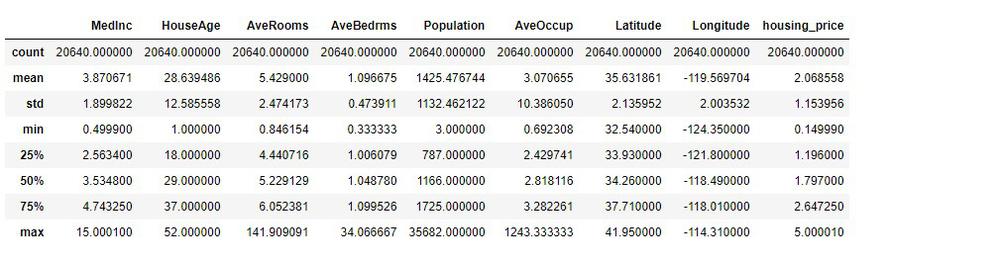
データの数は属性ごときっちり揃えられていますが、統計的な情報を見てみると外れ値や関係の無さそうな値があるように見えます。
これらを可視化してみたり、取り除いたり、他の値に置き換えたりしてクリーンアップさせることが重要ですが、今回はこのまま機械学習に流します。
さっそく機械学習に読み込ませますが、その前に、訓練セット用のデータとテストセット用のデータに分けます。
データを機械学習に読み込む準備¶
結合したhousingデータを説明変数と目的変数に分けておきます。
# 説明変数
housing_X = housing.drop(['housing_price'], axis=1)
# 目的変数
housing_y = housing['housing_price']
通常、機械学習にデータを与えるときには、訓練セット用とテストセット用にデータを分割します。
テストセットは機械学習を本番稼働させる前に行う最後の測定用として残しておき、訓練セットを使って機械学習モデルを構築します。(今回はハイパーパラメータなどのチューニングはせずにテストします)
1回限りの測定用データセットとして残しておくので、全体の20%くらいに分割するのがよろしいかと思います。
scikit-learnではデータセットを分割してくれる機能があり、引数を与えることによって分割する割合などを設定することができます。
from sklearn.model_selections import train_test_split
# ↓デフォルトでは全体の20%がテストセット
X_train, X_test, y_train, y_test = train_test_split(housing_X, housing_y)
分割されたデータセットを使ってさっそく機械学習モデルで予測してみましょう。
LinearRegression(線形回帰)¶
まず単純なモデルである線形回帰モデルで予測します。
from sklearn.linear_model import LinearRegression
# 線形回帰モデルのオブジェクトを格納
lin_reg = LinearRegression()
# 訓練開始
lin_reg.fit(X_train, y_train)
lin_regの中にさまざまな情報が格納されました。
訓練データを再度利用して、予測結果をプロットしてみましょう。
predict()メソッドを使って予測できます。(lin_reg.predict(X))
見やすくするために、0から14行までの要素を取り出して表示します。
# 実行
# 0から14行をnumpy配列で取得
x = np.arange(len(y_train))[:15]
plt.figure(figsize=(12, 5))
plt.plot(x, y_train[:15], 'b-', label='Train')
plt.plot(x, lin_reg.predict(X_train)[:15], 'r--', label='Linear')
plt.legend()
plt.show()
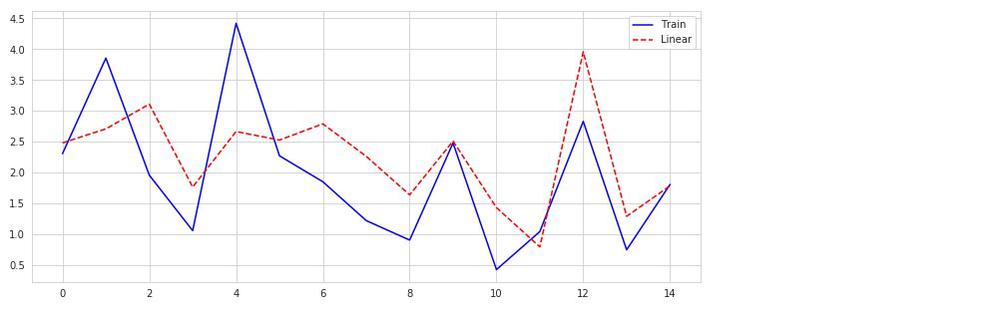
どれくらい予測できたかを見てみます。
# 実行
lin_reg.score(X_train, y_train)
0.6039007159059524
約60%の予測率でした。
ではテストセットで試してみましょう。
# 実行
x = np.arange(len(y_test))[:15]
plt.figure(figsize=(12, 5))
plt.plot(x, y_test[:15], 'b-', label='Test')
plt.plot(x, lin_reg.predict(X_test)[:15], 'r--', label='Linear')
plt.legend()
plt.show()
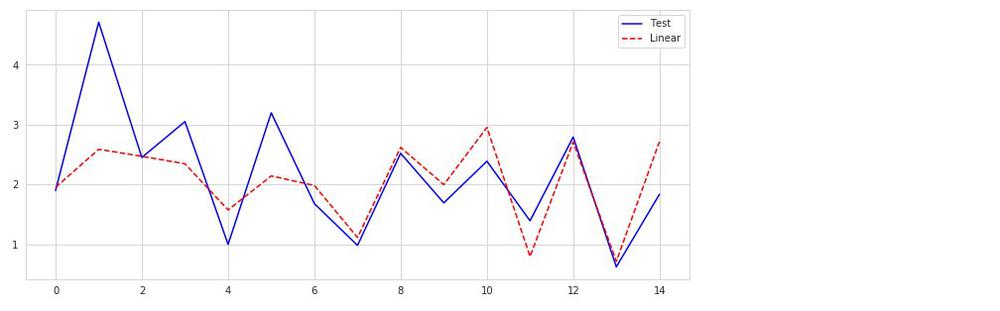
どれくらい予測できたかを見ます。
# 実行
lin_reg.score(X_test, y_test)
0.6113211306159207
61%。
未知のデータ(テスト用)に対して、訓練データよりも良くなっています。
今度は、複雑な機械学習モデルであるSVM(サポートベクトルマシン)を試して行きます。
SVM(サポートベクトルマシン)¶
SVMは人気があるらしく、色々な種類のモデルを構築することができます。
今回はSVMのSVRという予測器を使用して、先ほどの線形回帰モデルを比較してみたいと思います。
from sklearn.svm import SVR
svm_reg = SVR()
svm_reg.fit(X_train, y_train)
予測結果をプロットしてみます。(線形回帰のプロット時のコードとほぼ同じです)
# 実行
x = np.arange(len(y_train))[:15]
plt.figure(figsize=(12, 5))
plt.plot(x, y_train[:15], 'b-', label='Train')
plt.plot(x, svm_reg.predict(X_train)[:15], 'g--', label='SVR')
plt.legend()
plt.show()
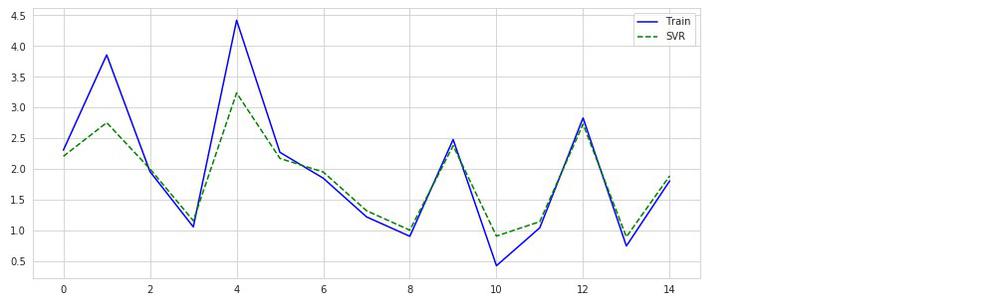
複雑なモデルと言われているだけに性能は良さそうです。
予測精度の割合を見ましょう。
# 実行
svm_reg.score(X_train, y_train)
0.7479874363727064
74%の予測率です。
では本当にこのモデルは同じようにテストセットにも性能を発揮してくれるのか、見ていきましょう。
# 実行
x = np.arange(len(y_test))[:15]
plt.figure(figsize=(12, 5))
plt.plot(x, y_test[:15], 'b-', label='Test')
plt.plot(x, svm_reg.predict(X_test)[:15], 'g--', label='SVR')
plt.legend()
plt.show()
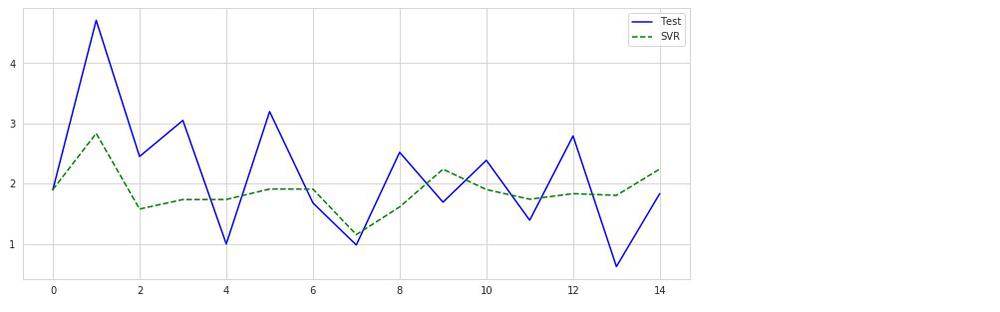
あまり良くなさげな結果です。
予測率を見ます。
# 実行
svm_reg.score(X_test, y_test)
0.09014841153062503
0.09%??
なんと性能が落ちています。
これを俗に言う「過学習」という奴ですね。
訓練データに対しては良い性能を発揮するが、未知のテストデータに対してはまったく性能が発揮されない。
過学習を起こす原因として考えられるのが、「データに対して複雑過ぎる機械学習モデル」、「そのモデルに対してデータの数が少なすぎる」、「データがしっかりクリーンアップされていない」などが考えられます。
対処法としては、「もう少し単純な機械学習モデルで試す」、「データの数を増やす」、「データをクリーンアップする」などです。
先ほども言いましたが、テストセットは1回限りとして封印しておき、別個で検証セットなどを作り、ハイパーパラメータのチューニングなどを行い最良の機械学習モデルを探すことが必要となります。
それらの方法は別の記事でご紹介したいと思います。
今回はデータサイエンティストの裏側といえるデータの取得から可視化までのプロセスをご紹介してみました。
私もまだまだ能力を付けて行かなければいけないのですが、実践的にやることが一番理解しやすく的を得た疑問も浮かびやすいと思います。
楽しく機械学習を扱えるように頑張っていきましょう!
それでは以上となります。
最後までご覧いただきありがとうございました。