【実践】手書き数字画像のデータセット(MNIST)を機械学習で多クラス分類してみよう!
投稿日 2019年9月10日 >> 更新日 2024年7月9日
今回は有名な手書き数字画像のデータセットであるMNISTデータセット(オリジナルではありません)を使って、多クラス分類をしてみようと思います。
今回使用する機械学習モデルは、ロジスティック回帰という分類器です。
専門用語などの難しい話はここでは抜きにして、機械学習ライブラリであるscikit-learnの実装工程だけに集中して取り組みたいと思います。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.8 |
| pip 9.0.1 |
| Jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| matplotlib==3.1.1 | PSF |
| numpy==1.17.0 | OSI Approved (new BSD) |
| scikit-learn==0.21.3 | OSI Approved (new BSD) |
MNISTデータセットの準備¶
まず使用するライブラリのインポートをします。
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
# ロジスティック回帰モデル
from sklearn.linear_model import LogisticRegression
# MNISTデータセット
from sklearn.datasets import load_digits
# 訓練用とテスト用に分割する機能
from sklearn.model_selection import train_test_split
ではMNISTデータセットを取得しましょう。
scikit-learnのdatasetsの中に格納されているので、読み込みます。
# 実行
mnist = load_digits()
mnist

dataやtargetなどと別れているので、Xに説明変数であるdata、yに目的変数であるtargetを変数に格納します。
# 実行
X, y = mnist.data, mnist.target
print(X.shape, y.shape)
(1797, 64) (1797,)
このデータセットは1,797個の画像があり、個々の画像の特徴量は64個です。0(白)から255(黒)までの特徴量があり、8×8ピクセルとなります。Matplotlibを使って実際の画像をプロットしてみましょう。
# 実行
# 正解ラベルの方は
y[100]
4
# 実行
# 100番目の要素である行列を8×8に変換
some_num = X[100].reshape(8, 8)
plt.imshow(some_num, cmap=matplotlib.cm.binary, interpolation='nearest')
plt.axis('off')
plt.show()
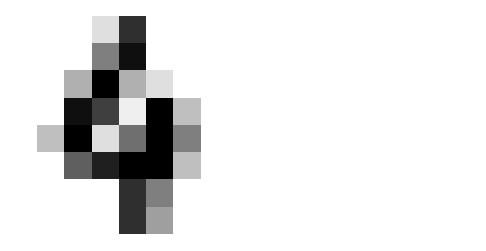
少し見難いですが4ぽいですね。
なおオリジナルのMNISTデータセットは70,000個の画像があり、784個の特徴量で28×28ピクセルとなっているので、今から使うデータセットの違いに注意してください。
データを訓練用とテスト用に分割します。
# テスト用を20%取り出し、random_stateでサンプリングを固定
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
ロジスティック回帰の実装¶
ではさっそくロジスティック回帰の実装を行っていきましょう。
# 実行
# オブジェクトを格納
lg_reg = LogisticRegression()
# 訓練開始
lg_reg.fit(X_train, y_train)
# テストセットを使って評価
lg_reg.score(X_test, y_test)
0.9611111111111111
96%の正解率でした!
predict()メソッドを使えば、予測された数字と正解ラベルを比較することができます。
# 実行
# 予測
lg_pred = lg_reg.predict(X_test)
# 最初の30番までを取得
print('予測:', lg_pred[:30])
print('正解:', y_test[:30])
予測: [6 9 3 7 2 1 5 2 5 2 1 8 4 0 4 2 3 7 8 8 4 3 9 7 5 6 3 5 6 3]
正解: [6 9 3 7 2 1 5 2 5 2 1 9 4 0 4 2 3 7 8 8 4 3 9 7 5 6 3 5 6 3]
かなりよいモデルを選択できました。
ただデータの量が少なめで、特徴量もオリジナルのMNISTと比べて単純な構造だったため、過学習の恐れもあります。
今回テストセットまでストレートに行ってしまいましたが、本来モデルを再度検証するための交差検証などを使って、モデルを比較したり再評価を行ったりします。
非常に簡単ではありましたが、より詳しい機械学習モデルのチューニングは別の記事で挙げたいと思います。
最後までご覧いただきありがとうございました。