【実践】scikit-learnでDeep Learning(深層学習)の実装 分類編
投稿日 2019年9月13日 >> 更新日 2024年7月9日
今回はいよいよscikit-learnでDeepLearningの実装をしていきたいと思います。
と言いたいところですが、厳密にはMLP(Multi Layer Perceptron)の実装になります。
しかしscikit-learnのドキュメントを見る限り、隠れ層があり、バックプロパゲーション(誤差逆伝播法)が使われていたり、訓練を高速にする最適化アルゴリズムが使われていたりと、もはやDeepLearningと言っても過言ではないでしょう。
scikit-learnでは簡単に訓練させることができるので非常に便利です。
簡単に概要を説明しますと
- MNISTデータセットを使用した分類問題で、1回目はデフォルの設定でMLPモデルを訓練させます。
- 結果を吟味し、正規化やランダムサーチを使った交差検証などを行いハイパーパラメータを設定します。
- 最後に最高のモデルを保存します。
ということで、今回使うデータセットはオリジナルのMNISTデータセット(28×28ピクセル)です。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.8 |
| pip 9.0.1 |
| jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| matplotlib==3.1.1 | PSF |
| numpy==1.17.0 | OSI Approved (new BSD) |
| scikit-learn==0.21.3 | OSI Approved (new BSD) |
ライブラリのインストール¶
これから作業をするディレクトリにて、それぞれのパッケージを一括インストールするためのrequirements.txtというテキストファイルを作成して以下の内容をコピペしてください。(jupyterは使いたい人だけ)
今回はこのバージョンでの作業となります。
# requierments.txt
jupyter==1.0.0
matplotlib==3.1.1
numpy==1.17.0
scikit-learn==0.21.3
pipで一括インストール(ディレクトリ内にrequierments.txtがあること)
$ pip3 install -r requierments.txt
# 確認
$ pip3 freeze
jupyter==1.0.0
matplotlib==3.1.1
numpy==1.17.0
scikit-learn==0.21.3
MNISTデータセットの準備¶
今回使用するMNISTは、70,000個の画像と画像1個に784個の特徴量を持つ28×28ピクセルのデータを使います。(前回は64個の特徴量を持つ8×8ピクセルを使用)
まず必要なライブラリをインポートし、MNISTを読み込みます。
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
# MNISTデータ
from sklearn.datasets import fetch_openml
まずfetch_openmlからオブジェクトを取得し、説明変数用にdata、目的変数用にtargetを指定して各変数に格納します。
# オブジェクトを取得
mnist = fetch_openml('mnist_784')
# 説明変数
mnist_X = mnist.data
# 目的変数(np.int8は整数型に変換)
mnist_y = mnist.target.astype(np.int8)
中身を確認してみます。
# 実行
mnist_X
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
# 実行
mnist_y
array([5, 0, 4, ..., 4, 5, 6], dtype=int8)
mnist_yの0番目の要素が5となっているので、果たして本当か、matplotlibを使ってmnist_Xの0番の要素をプロットしてみます。
# 実行
some_num = mnist_X[0].reshape(28, 28)
plt.imshow(some_num, cmap=matplotlib.cm.binary, interpolation='nearest')
plt.axis('off')
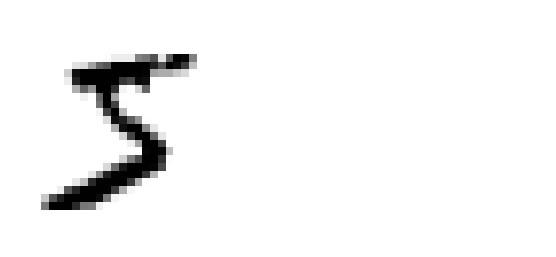
ちゃんと取得できてるみたいです。
それではDeepLearning(MLP)の実装を始めていきましょう。
多層パーセプトロン(MLP)¶
ここで必要なライブラリをインポートします。
# 訓練セットとテストセットに分割する機能
from sklearn.model_selection import train_test_split
# 多層パーセプトロン
from sklearn.neural_network import MLPClassifier
訓練用、テスト用を8対2の割合で分割し、random_stateでサンプリングを一定に保つ
# 実行
X_train, X_test, y_train, y_test = train_test_split(mnist_X, mnist_y, test_size=0.2, random_state=42
print(X_train.shape, X_test.shape)
(56000, 784) (14000, 784)
ではモデルを訓練していきますが、1回目はデフォルト値のまま実力を試してみましょう。
mlp_clf = MLPClassifier()
mlp_clf.fit(X_train, y_train)
ちなみにMLPClassifierのデフォルト値はこのようになっています。
activation='relu'は隠れ層に使われている関数で、batch_size='auto'はデフォルトで200が設定されていて、hidden_layer_sizes=(100,)は1層からなる100ニューロンの隠れ層です。
出力層ではソフトマックス関数が使われているみたいなので、多クラス分類にはピッタリです。(詳細はscikit-learnドキュメントへ)
MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_iter=200, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=None, shuffle=True, solver='adam', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False)
では結果を見てみます。
# 実行
mlp_clf.score(X_train, y_train)
0.9904285714285714
訓練セットで99%。かなり優秀なモデルです。
ただ、データに対して複雑過ぎるモデルは過学習している恐れがあります。
なので、次はデータのスケーリングを行い、ランダムサーチを使ってモデルを比較し検証して最適なパラメータ値を探し、テストセットでも高い正解率を目指しましょう。
特徴量のスケーリング、ランダムサーチでモデルの比較¶
まずはデータのスケーリングを行っていきますが、モデルなどによってデータのスケーリングが異なります。
たとえばデータに外れ値が含まれていてそれがモデルに大きく影響を受けてしまうなら標準化を使う。
もう一つは、値を0から1に収まる範囲にスケーリングする最小最大スケーリングを使う。
今回使っているモデルであるニューラルネットワークは、入力値が0から1までの範囲に収まっていることを前提とすることが多いので、最小最大スケーリングを使って、特徴量をスケーリングしていこうと思います。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train_scaler = scaler.fit_transform(X_train)
# テストセットもスケーリング
X_test_scaler = scaler.fit_transform(X_test)
次に、モデルパラメータの最適な値を探すために、ランダムサーチ(RandomizedSearchCV)を使用します。
他にもグリッドサーチ(GridSearchCV)と呼ばれる最適な値を探す機能がありますが、ニューラルネットワークのような操作すべきハイパーパラメータが多数あり、かつ大規模なデータセットを訓練する場合は、合理的な時間内に探れるランダムサーチ(RandomizedSearchCV)がはるかに良いとの事です。
MLPClassifierのドキュメントを参考に、好きな引数を指定して検証してみてください。
ちなみに以下の設定で40分検証にかかりました。(第7世代CPU)
from sklearn.model_selection import RandomizedSearchCV
"""ランダムサーチに渡すためのパラメータ値の設定
辞書型のキーはMLPClassifierの引数を参考に
キーを選んだら、試したい数値を決めていく
ここでは13通り検証する
"""
random_search = {'batch_size': [300, 350, 400, 450],
'hidden_layer_sizes': [(150, 150), (100, 100, 50), (150, 100, 50)],
'max_iter': [400, 500, 600, 700, 800],
'random_state': [0]}
"""cv=3は交差検証を3分割
n_jobs=-1はすべてのプロセッサを使用
scornigは精度を指定など
"""
mlp_random_search = RandomizedSearchCV(mlp_clf, random_search, cv=3,
n_jobs=-1, scoring='accuracy', random_state=0)
# スケーリングしたデータで実行します
mlp_random_search.fit(X_train_norm, y_train)
1番良い精度を出したパラメータ値は
# 実行
mlp_random_search.best_params_
0.9758571428571429 {'random_state': 0, 'max_iter': 600, 'hidden_layer_sizes': (150, 150), 'batch_size': 300}
全体の評価も見てみます。
# 実行
cvres = mlp_random_search.cv_results_
for score, params in zip(cvres['mean_test_score'], cvres['params']):
print(score, params)
0.9737142857142858 {'random_state': 0, 'max_iter': 500, 'hidden_layer_sizes': (100, 100, 50), 'batch_size': 350}
0.9753392857142857 {'random_state': 0, 'max_iter': 400, 'hidden_layer_sizes': (150, 100, 50), 'batch_size': 400}
0.9734285714285714 {'random_state': 0, 'max_iter': 800, 'hidden_layer_sizes': (100, 100, 50), 'batch_size': 450}
0.9737142857142858 {'random_state': 0, 'max_iter': 700, 'hidden_layer_sizes': (100, 100, 50), 'batch_size': 350}
0.974375 {'random_state': 0, 'max_iter': 500, 'hidden_layer_sizes': (100, 100, 50), 'batch_size': 300}
0.9758571428571429 {'random_state': 0, 'max_iter': 600, 'hidden_layer_sizes': (150, 150), 'batch_size': 300}
0.9754464285714286 {'random_state': 0, 'max_iter': 800, 'hidden_layer_sizes': (150, 150), 'batch_size': 400}
0.9734285714285714 {'random_state': 0, 'max_iter': 700, 'hidden_layer_sizes': (100, 100, 50), 'batch_size': 450}
0.9737678571428572 {'random_state': 0, 'max_iter': 400, 'hidden_layer_sizes': (100, 100, 50), 'batch_size': 400}
0.97575 {'random_state': 0, 'max_iter': 600, 'hidden_layer_sizes': (150, 100, 50), 'batch_size': 350}
では、最良の分類器を新たな変数に格納しましょう。
# 実行
best_mlp = mlp_random_search.best_estimator_
best_mlp
MLPClassifier(activation='relu', alpha=0.0001, batch_size=300, beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(150, 150), learning_rate='constant',
learning_rate_init=0.001, max_iter=600, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=0, shuffle=True, solver='adam', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False)
この分類器を使い、テストを行います。スケーリングした訓練セットでモデルを学習させているので、スケーリングしたテストセットを使って精度を確認しましょう。
# 実行
best_mlp.score(X_test_scaler, y_test)
0.9805
98%という結果がでました。なかなか最良なモデルを選べたのではないかと思われます。
そしてこのモデルをまた使えるように保存していきたいと思います。
最適化MLPモデルを保存¶
では最後に、長い時間を掛けて探し当てた最良のモデルを保存していきます。
といっても、Python組み込みモジュールであるpickleを使ってです。
バイナリデータ用に書き込みそして読み込みまで行って締めくくりたいと思います。
import pickle
"""
ファイル名を指定
wbはバイナリモード
dumpで最良モデルを保存
"""
f = open('mlp_model', 'wb')
pickle.dump(best_mlp, f)
f.close
"""
ファイルを指定
バイナリモードで開く
"""
f = open('mlp_model', 'rb')
# 実行
pickle.load(f)
MLPClassifier(activation='relu', alpha=0.0001, batch_size=300, beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(150, 150), learning_rate='constant',
learning_rate_init=0.001, max_iter=600, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=0, shuffle=True, solver='adam', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False)
それでは以上となります。
最後までご覧いただきありがとうございました。
