【第3回ゼロからブログのデータマイニング】ワンホットエンコーディングとラグ特徴量の生成
投稿日 2019年10月5日 >> 更新日 2024年7月9日
今回は前回の記事、【第2回ゼロからブログのデータマイニング】日付から特徴量を生成し、機械学習に流してみる とは別の特徴量を生成して機械学習の予測を行って行こうと思います。
題名にもある通り、ワンホットエンコーディングとラグ特徴量という手法を使います。
ワンホットエンコーディングは前回の記事でもやりましたが、あるカテゴリを0か1のバイナリー属性にして特徴量として加えます。
ラグ特徴量というのは、過去のデータを特徴量として加える。時系列データでよく見られる手法で1日前や2日前のデータがその日の結果に対する指標になっている場合もあります。
手元にデータが揃っていない場合は、こういった手法を使ってデータを無理矢理増やしてくことも結果はどうであれ技術的に磨かれると思います。
ここではDjangoフレームワークを使用した私のWebサイトから1部データを取得するので、各々で目的に応じたデータを取得しましょう。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| windows Subsystem for Linux |
| Python 3.6.8 |
| pip 9.0.1 |
| Jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| Django | BSD |
| Pandas | BSD |
| numpy | OSI Approved (new BSD) |
| matplotlib | PSF |
| Seaborn | BSD |
| scikit-learn | OSI Approved (new BSD) |
データを取得¶
まずDjangoAPIを使ってデータを取得します。
ローカル環境での操作と一緒ですが私の場合はTera Termを起動しDjangoのshell環境に入ります。※管理者権限(sudo)でないと操作が限られます。
$ sudo python3.6 manage.py shell
ではpandasも活用してデータを取得しCSVファイルに納めます。
今回取得するデータは、日付順に投稿されている記事のカテゴリー属性だけです。
その日付に投稿された記事の各カテゴリーを取得できれば、そのカテゴリー属性での特徴量として扱えます。
>>> import pandas as pd
>>> from blogs.models import Blog
>>>
# リスト内包表記でカテゴリ属性を取り出す
>>> blog_data = [i.category for i in Blog.objects.all()]
>>> blog_data
[Category: プロフィール>, Category: サーバーサイド>, ............
>>>
# 投稿されている記事の日付を取得
>>> day_data = [i.created_at for i in Blog.objects.all()]
>>> day_data
[datetime.date(2019, 5, 19), datetime.date(2019, 5, 23), ............
>>>
# 一旦データフレームに納めてCSVファイルに格納する
>>> df = pd.DataFrame(blog_data, day_data)
>>> df.head(10)
0
2019-05-19 プロフィール
2019-05-23 サーバーサイド
2019-05-23 サーバーサイド
2019-05-29 Python
2019-05-29 サーバーサイド
2019-05-30 Django
2019-05-30 Django
2019-06-01 Django
2019-06-02 Python
2019-06-03 Python
>>>
>>> df.to_csv('category.csv')
>>>
>>> quit()
Tera Term内で作られたCSVファイルを作業ディレクトリへ移動します。
まず先ほど作成したCSVファイルのcategory.csvの絶対パスを取得します。
$ find / -name category.csv
/path/path/category.csv
絶対パスをコピーし、ターミナル左上のファイル(F)をクリックします。「SSH SCP...」という項目をクリックすると、下図のようになるので、先ほどコピーした絶対パスをFrom:に、移動させたいフォルダTo:を指定し、Receiveをクリックします。
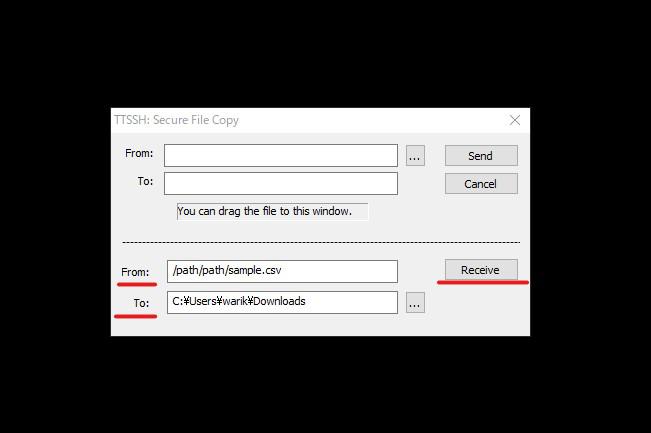
移動させたいフォルダを見ながら実行すると確実です。
ワンホットエンコーディング¶
取得したCSVファイルをさっそくワンホットにしていきます。
必要なモジュールをインポートします。
# 実行
import pandas as pd
import numpy as np
from sklearn.preprocessing import OneHotEncoder
# ついでにデータをロード
df = pd.read_csv('category.csv', index_col=0)
df.head()
0
2019-05-19 プロフィール
2019-05-23 サーバーサイド
2019-05-23 サーバーサイド
2019-05-29 Python
2019-05-29 サーバーサイド
私の場合ですが、データの答えである閲覧数の目的変数側では、2019年7月1日から取られているので、開始日を合わせるために説明変数であるこのデータ2019年5月19日から6月30日までを取り除きます。
# 実行
df = df[18:]
df.head()
0
2019-07-01 Django
2019-07-01 データ分析&機械学習
2019-07-03 Django
2019-07-05 プロフィール
2019-07-09 Django
7月1日が重複しているのでpandasのduplicated()メソッドを使って一意にします。
# 実行
"""
デフォルトではtake_last=False
Trueにすることによって重複した最後の値を残す
"""
df = df[~df.index.duplicated()]
df.head()
Django データ分析&機械学習 プロフィール サーバーサイド Python
2019-07-01 1.0 0.0 0.0 0.0 0.0
2019-07-03 1.0 0.0 0.0 0.0 0.0
2019-07-05 0.0 0.0 1.0 0.0 0.0
2019-07-09 1.0 0.0 0.0 0.0 0.0
2019-08-13 0.0 1.0 0.0 0.0 0.0
#CSVファイルに保存
df.to_csv('category.csv')
これでワンホットエンコーディングされたデータができあがった。
日付がまばらになっていますが後にラグ特徴量を生成した際に結合し欠損値の置換などを行います。
ラグ特徴量¶
時系列データの特徴量でよく見られるラグ特徴量を生成していきたいと思います。
扱うデータは、第1回目、第2回目でも使用した閲覧数が7月1日から10月3日(増えました)まで記録されたデータです。
これを目的変数と起きますが、データが無い場合は、【第1回ゼロからブログのデータマイニング】日付と目的データを取得内で説明しているので、そちらを参考にお願いします。
では必要なモジュールをインポートし目的変数の格納されたデータをロードします。
# 実行
import pandas as pd
df_target = pd.read_csv('sample.csv', index_col=0)
df_target.head()
count
2019-07-01 14
2019-07-02 9
2019-07-03 15
2019-07-04 6
2019-07-05 5
# データフレームになっていない場合はデータフレームにします
df_target = pd.DataFrame(df_target)
pandasのshift()を使って過去6日間のラグ特徴量を生成します。
6回繰り返すのは面倒なのでfor文で格納していきます。
# 実行
# 1から6の値を格納
a = range(1, 7)
# count_1からcount_6までの列名が追加されていく
for i in a:
df_target = pd.concat([df_target, df_target['count'].shift(i).rename('count_'+str(i))], axis=1)
df_target.head(7)
count count_1 count_2 count_3 count_4 count_5 count_6
2019-07-01 14 NaN NaN NaN NaN NaN NaN
2019-07-02 9 14.0 NaN NaN NaN NaN NaN
2019-07-03 15 9.0 14.0 NaN NaN NaN NaN
2019-07-04 6 15.0 9.0 14.0 NaN NaN NaN
2019-07-05 5 6.0 15.0 9.0 14.0 NaN NaN
2019-07-06 7 5.0 6.0 15.0 9.0 14.0 NaN
2019-07-07 5 7.0 5.0 6.0 15.0 9.0 14.0
shift(-i)にすることで逆の動作をします。
ここでNull値を取り除きたいところですが、先ほど作成したcategoryデータと結合して欠損値などを置き換えなければいけないので後に回したいと思います。
それではcategory.csvをロードしてdf_targetデータと結合して行きます。
# 実行
df_category = pd.read_csv('category.csv', index_col=0)
df_category.head()
Django データ分析&機械学習 プロフィール サーバーサイド Python
2019-07-01 1.0 0.0 0.0 0.0 0.0
2019-07-03 1.0 0.0 0.0 0.0 0.0
2019-07-05 0.0 0.0 1.0 0.0 0.0
2019-07-09 1.0 0.0 0.0 0.0 0.0
2019-08-13 0.0 1.0 0.0 0.0 0.0
結合!
※列名がずれてしまうのでimage画像を貼ります。
# 実行
df = concat([df_category, df_target], axis=1)
df.head(7)
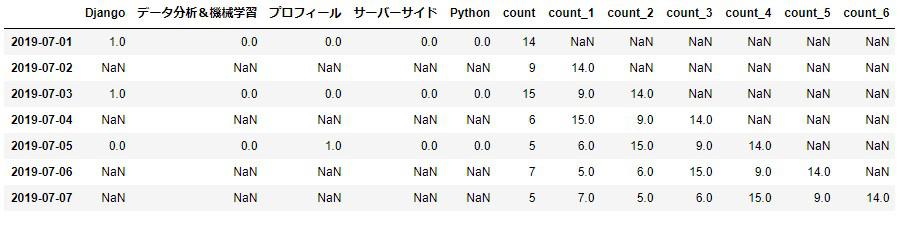
カテゴリデータの方は投稿された日付しか取得されていないので、新しく加わった日付にはNull値となってしまいます。
要するにカテゴリ側のNull値は記事の投稿が0と言うことなので0に置き換えします。
※列名がずれてしまうのでimage画像を貼ります。
# 実行
df = df.fillna(0)
df.head(7)
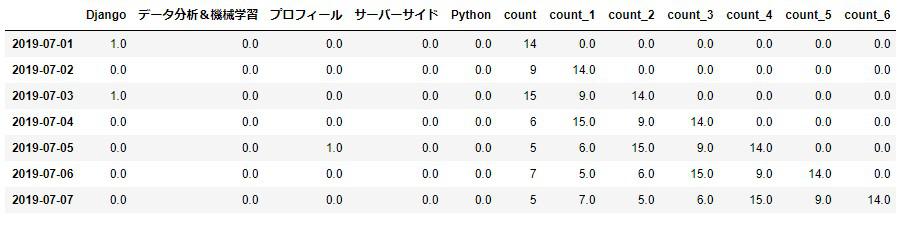
そしてラグ特徴量側は最初の6行がNull値だったのでデータ全体の上6行以外を新たな変数に格納します。
※列名がずれてしまうのでimage画像を貼ります。
# 実行
df_new = df[6:]
df_new.head()

ただでさえ少ないデータを削るのは勿体ないですが、機械学習の訓練を行ってみて様子を伺いましょう。
機械学習で予測¶
今回使うモデルは、お馴染みの線形回帰とランダムフォレストです。
訓練を行う前に入力データXとラベルデータyに分け、入力データXを標準化させます。
そして訓練用とテスト用にデータを分割して学習させます。
# 標準化用
from sklearn.preprocessing import StandardScaler
X = df_new.drop(['count'], axis=1)
y = df_new['count']
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 訓練セットには後ろから10日間以外を格納
# テストセットには後ろから10日間を格納
X_train = X[:-10]
X_test = X[-10:]
y_train = y[:-10]
y_test = y[-10:]
では線形回帰から訓練を行います。
# 実行
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)
print(lin_reg.score(X_train, y_train))
print(lin_reg.score(X_test, y_test))
0.6086146829862202
-0.2152012032688959
テストセットではだいぶ下回ってます。
様子をプロットしてみます。
# 実行
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
lin_pred = lin_reg.predict(X_test)
x = range(len(y_test))
plt.figure(figsize=(15, 5))
plt.plot(x, y_test, 'b', label='Test')
plt.plot(x, lin_pred, 'r', label='Linear')
plt.legend()
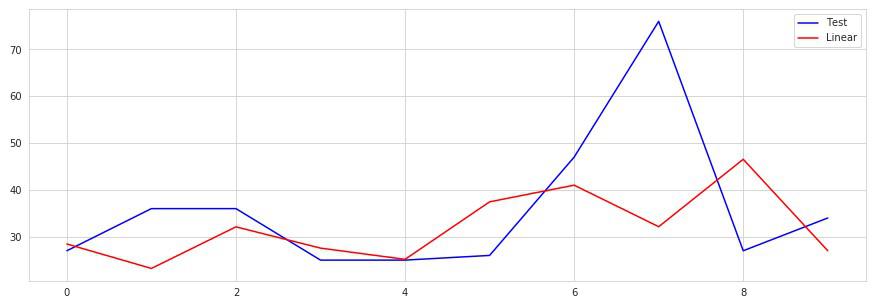
ラベル付けされたテストデータの凸部分での差でだいぶ精度が悪いように見えます。
この部分の因果関係を見つけ出して特徴量として追加すれば結果は良くなると思われます。
既に落胆モードに入っていますがランダムフォレストを試します。
ランダムフォレストはハイパーパラメータ値をいじれるので、グリッドサーチを使って交差検証を行ってモデルを訓練させたいと思います。
# 実行
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
# ハイパーパラメータ値を適当に設定
param_grid = [
{'n_estimators': list(range(30, 50)), 'max_features': list(range(3, 7))},
]
forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
# 交差検証を行った際の最高パラメータ値
print(grid_search.best_params_)
# 最高のパラメータ値を使って訓練
forest_reg = grid_search.best_estimator_
forest_reg.fit(X_train, y_train)
print(forest_reg.score(X_train, y_train))
print(forest_reg.score(X_test, y_test))
# 結果
{'max_features': 6, 'n_estimators': 30}
0.9141393962366391
-0.020757124839856367
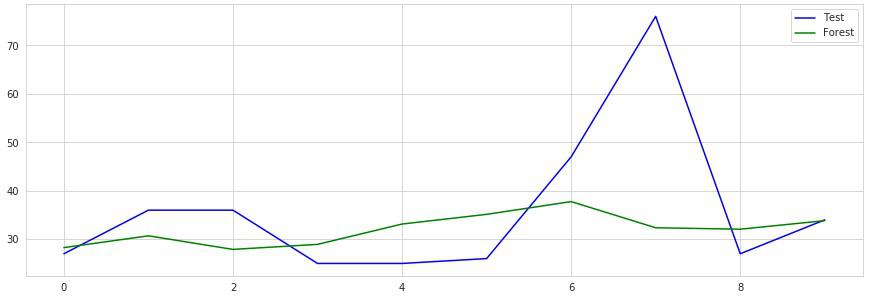
線形回帰と比べてこちらはやや滑らかな動きが見受けられます。
ラグ特徴量を増やしたり減らしたりして再度訓練を行うのも練習としては良いと思います。
今回はだいぶ限られた資源の中から特徴量を生成してきましたが、外部ツール(SNSやGoogleアナリティクス)を使っている方はそれらからデータを収集して訓練させれば、より賢い予測モデルが出来上がるかと思います。
どんどん課題を見つけて挑戦していきましょう。
今回はシリーズ第3回までやってきましたがいかがだったでしょうか?
データを取得して生成して整理をし、機械学習で予測を行うといった一連の流れをやってきました。
私自身だいぶ勉強不足なところがありますが、AI時代を生きるものとして何か少しでも参考になってくだされば幸いです。
またシリーズ化させていくので楽しみにしていてください。
最後までご覧いただきありがとうございました。