【Python】GoogleアナリティクスAPI(Analytics Reporting API v4)でデータを取得する方法
投稿日 2019年10月19日 >> 更新日 2023年12月14日
注意
Googleアナリティクス4(GA4)の「Google Analytics Data API v1」に関する設定はこちらの「【Googleアナリティクス4(GA4)】Google Analytics Data API v1の各種設定と実装」をご覧ください。
今回はGoogleアナリティクスのデータをAnalytics Reporting API v4を使って取得していきたいと思います。
取得したデータをPythonのグラフ描画ライブラリである「matplotlib」を使って可視化もしてみたいと思います。
もちろんGoogleアナリティクスから直接CSVファイルを取得することもできますが、静的となっているためどうしても手動になってしまいます。
APIを使うことによって他のアプリと連携し自動化できるので非常に便利です。
例えば、よく閲覧されているページを取得しWebサイトのサイドバーに表示させるといったことなどを実現することができます。
なのでここではGoogleアナリティクスAPIの基礎的な部分を中心に実装していきます。
GoogleアナリティクスAPI(Analytics Reporting API v4)の初期設定についてはこちらをご覧ください。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.8 |
| pip 9.0.1 |
| 使用ライブラリ | ライセンス |
|---|---|
| Django==2.2.6 | BSD |
| japanize-matplotlib==1.0.5 | MIT |
| matplotlib==3.1.1 | PSF |
| seaborn==0.9.0 | BSD |
必要なライブラリ¶
基本的にPythonだけで実装できますが、グラフを描画させたい方などは別途インストールが必要になります。
「matplotlib」はインストールするだけでハマってしまう可能性があるので、あまり無理をせずAPIだけに集中するのも有りです。
「japanize-matplotlib」は日本語化にする為のモジュールです。
「seaborn」はpandasやmatplotlibと親和性があり、グラフを綺麗に描画してくれます。
japanize-matplotlib==1.0.5
matplotlib==3.1.1
seaborn==0.9.0
先ほども言いましたが、GoogleアナリティクスAPIを使う為には初期設定とAPIモジュールが必要になるので、お済みでない方は先に設定しましょう。
APIを操作するポイント¶
APIで取得するデータを「report」といって、その中身はjson形式になっています。
json形式のデータをAPIがPythonでも扱えるよう辞書型(dict:{})リスト型(list[])に出力してくれています。
公式のAnalytics Reporting APIドキュメントも参考にして実装しましょう。
まずは初期設定で取得してきたスクリプトファイルの「HelloAnalytics.py」の全体です。
# HelloAnalytics.py
from apiclient.discovery import build
from oauth2client.service_account import ServiceAccountCredentials
SCOPES = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = 'client_secrets.json'
VIEW_ID = '各々のviewコード'
def initialize_analyticsreporting():
credentials = ServiceAccountCredentials.from_json_keyfile_name(
KEY_FILE_LOCATION, SCOPES
)
analytics = build('analyticsreporting', 'v4', credentials=credentials)
return analytics
def get_report(analytics):
return analytics.reports().batchGet(
body={
'reportRequests': [{
'viewId': VIEW_ID,
'dateRanges': [{"startDate": "7daysAgo", "endDate": "today"}],
'metrics': [{'expression': 'ga:sessions'}],
'dimensions': [{'name': 'ga:country'}]
}]
}
).execute()
def print_response(response):
for report in response.get('reports', []):
columnHeader = report.get('columnHeader', {})
dimensionHeaders = columnHeader.get('dimensions', [])
metricHeaders = columnHeader.get('metricHeader', {}).get('metricHeaderEntries', [])
for row in report.get('data', {}).get('rows', []):
dimensions = row.get('dimensions', [])
dateRangeValues = row.get('metrics', [])
for header, dimension in zip(dimensionHeaders, dimensions):
print(header + ': ' + dimension)
for i, values in enumerate(dateRangeValues):
print('Date range: ' + str(i))
for metricHeader, value in zip(metricHeaders, values.get('values')):
print(metricHeader.get('name') + ': ' + value)
def main():
analytics = initialize_analyticsreporting()
response = get_report(analytics)
print_response(response)
if __name__ == '__main__':
main()
今回特に扱う部分は、「def get_report(analytics):」関数内と「def print_response(response):」関数内です。
# HelloAnalytics.py
""" データを取得"""
def get_report(analytics):
return analytics.reports().batchGet(
body={
'reportRequests': [{
'viewId': VIEW_ID,
'dateRanges': [{"startDate": "7daysAgo", "endDate": "today"}],
'metrics': [{'expression': 'ga:sessions'}],
'dimensions': [{'name': 'ga:country'}]
}]
}
).execute()
""" 取得したデータを出力"""
def print_response(response):
for report in response.get('reports', []):
columnHeader = report.get('columnHeader', {})
dimensionHeaders = columnHeader.get('dimensions', [])
metricHeaders = columnHeader.get('metricHeader', {}).get('metricHeaderEntries', [])
for row in report.get('data', {}).get('rows', []):
dimensions = row.get('dimensions', [])
dateRangeValues = row.get('metrics', [])
for header, dimension in zip(dimensionHeaders, dimensions):
print(header + ': ' + dimension)
for i, values in enumerate(dateRangeValues):
print('Date range: ' + str(i))
for metricHeader, value in zip(metricHeaders, values.get('values')):
print(metricHeader.get('name') + ': ' + value)
def get_report(analytics)関数内を見てみると、「'dateRanges'」で今日から過去7日間となっていて、「'metrics'」ではセッション数、「'dimensions'」では国が指定されています。
これは過去7日間において訪れた国別のセッション数を表します。
操作すべきポイントはdef get_report(analytics)関数内の「'reportRequests'」キー内ということになります。
'reportRequests': [{
'viewId': VIEW_ID,
'dateRanges': [{"startDate": "2019-10-01", "endDate": "2019-10-16"}],
'metrics': [{'expression': 'ネーム'}],
'dimensions': [{'name': 'ネーム'}]
}]
公式ドキュメントでも必須と言われているのが、以下の3つのフィールドです。
'viewId': VIEW_ID,
'dateRanges': [{"startDate": "2019-10-01", "endDate": "2019-10-16"}],
'metrics': [{'expression': 'ネーム'}],
では最低限必要なフィールドを例に、10月1日から10月16日の間でユーザーがアクセスしてきた総数を取得したいと思います。
出力のdef print_response(response)関数内も変更します。
# HelloAnalytics.py
def get_report(analytics):
return analytics.reports().batchGet(
body={
'reportRequests': [{
'viewId': VIEW_ID,
""" 変更"""
'dateRanges': [{"startDate": "2019-10-01", "endDate": "2019-10-16"}],
'metrics': [{'expression': 'ga:users'}],
}]
}
).execute()
""" シンプルな出力"""
def print_response(response):
for report in response['reports'][0]['data']['rows']:
value = report['metrics'][0]
print(value)
※シンプルな出力に関してはPythonファイル実行後に説明します。
# 実行
$ python3 HelloAnalytics.py
{'values': ['213']}
私の場合は10月1日から16日までは213アクセスがあったことになります。
「def print_response(response)」関数内ですが、「response」データは辞書型になっているので順番にキーとスライス(オフセット)を利用して取り出しています。
実際にdef get_report(analytics)関数が渡されたresponseの中身はこのようになっています。
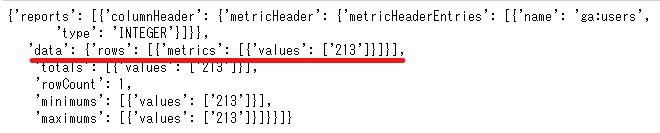
辞書型(dict{})の取り出し方はいくつか方法があって、get()もしくわ['key']を使って行います。
# get()
response.get('reports')[0].get('data').get('rows')[0].get('metrics')[0]
# keyを指定
response['reports'][0]['data']['rows'][0]['metrics'][0]
ここでは後者を使うことにして、「reports」の次に取り出したい要素はリスト型(list[])になっているのでスライス(オフセット)「0」を指定し、その中の辞書型「data」を取り出しています。
1日ごとのユーザー数と日付を取得¶
次は10月1日から16日までの1日ごとにアクセスされたデータを取得してみたいと思います。
# HelloAnalytics.py
def get_report(analytics):
return analytics.reports().batchGet(
body={
'reportRequests': [{
'viewId': VIEW_ID,
""" 変更"""
'dateRanges': [{"startDate": "2019-10-01", "endDate": "2019-10-16"}],
'dimensions': [{'name': 'ga:date'}], \# 追加
'metrics': [{'expression': 'ga:users'}],
}]
}
).execute()
""" シンプルな出力"""
def print_response(response):
for report in response['reports'][0]['data']['rows']:
value = report \# dimensionsとmetricsの手前までを取得
print(value)
実行すると

「dimensions」キーを与えることで、「dateRanges」キーの期間内の「metrics」キーのユーザーアクセス数を日付ごとに取り出してくれます。
def get_report(analytics)関数内の「reportRequests」→「dateRanges」「metrics」「dimensions」をポイントとして押さえておけば直感的に操作を行えるようになると思います。
データを可視化¶
ではここからはmatplotlibを使用してデータを可視化してみたいと思います。
HelloAnalytics.pyファイル内ですべて行うので、モジュールをインポートします。
# HelloAnalytics.py
from apiclient.discovery import build
from oauth2client.service_account import ServiceAccountCredentials
""" 追加"""
import datetime
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set_style('whitegrid')
次に描画させるために必要な要素を準備するため、ユーザー数を格納するための「user_value」空リスト、日付を格納する為の「days」空リストを用意し、for文で格納していきます。
# HelloAnalytics.py
user_value = []
days = []
def print_response(response):
for report in response['reports'][0]['data']['rows']:
value = report['metrics'][0]['values'][0]
user_value.append(int(value)) # valueタイプを整数型(int())に変更
""" 日付用"""
for i in range(len(user_value)):
day = datetime.date(2019, 10, 1) + datetime.timedelta(days=i)
days.append(day)
日付用では「user_value」リスト内の要素は16個あるので、それをrangeメソッドで「0, 1, 2, ...., 15」として「days=i」に渡しています。
すると順番に10月1日から16日までの日付を取得でき「days」に格納されます。
そして新しく描画用の関数を定義して終わりです。
# HelloAnalytics.py
""" 描画用に定義"""
def api_plot(x, y):
plt.figure(figsize=(15, 5))
plt.plot(x, y, label='User Value')
plt.legend()
plt.show()
def main():
analytics = initialize_analyticsreporting()
response = get_report(analytics)
print_response(response)
api_plot(days, user_value) \# 描画用の関数に準備した変数を渡す
実行すると
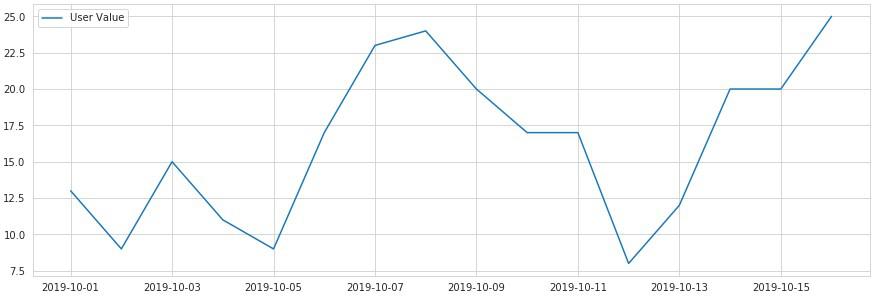
ページビューを取得して可視化¶
次にページビューのデータを取得していこうと思います。
ページビューを取得するには、ユーザー数と同じく「metrics」内で追加するだけです。
これまでと同じ条件でページビューも追加でデータを可視化していきます。
# HelloAnalytics.py
def get_report(analytics):
return analytics.reports().batchGet(
body={
'reportRequests': [{
'viewId': VIEW_ID,
'dateRanges': [{"startDate": "2019-10-01", "endDate": "2019-10-16"}],
'dimensions': [{'name': 'ga:date'}],
'metrics': [{'expression': 'ga:users'}, {'expression': 'ga:pageviews'}], \# 追加
}]
}
).execute()
ページビュー用の空リストを用意し、格納します。
# HelloAnalytics.py
user_value = []
page_view = [] \# 追加
days = []
def print_response(response):
for report in response['reports'][0]['data']['rows']:
value = report['metrics'][0]['values'][0]
view = report['metrics'][0]['values'][1] # 追加
user_value.append(int(value))
page_view.append(int(view)) # 追加
for i in range(len(user_value)):
day = datetime.date(2019, 10, 1) + datetime.timedelta(days=i)
days.append(day)
「values」内の要素はリスト型になっているので、スライス(オフセット)で指定し取り出しています。

描画用の関数を編集します。
# HelloAnalytics.py
def api_plot(x, y, y1): # 引数にy1を追加
plt.figure(figsize=(15, 5))
plt.plot(x, y, label='User Value')
plt.plot(x, y1, label='Page View') # 追加
plt.legend()
plt.show()
def main():
analytics = initialize_analyticsreporting()
response = get_report(analytics)
print_response(response)
api_plot(days, user_value, page_view) \# 引数にpage_viewを追加
実行します。
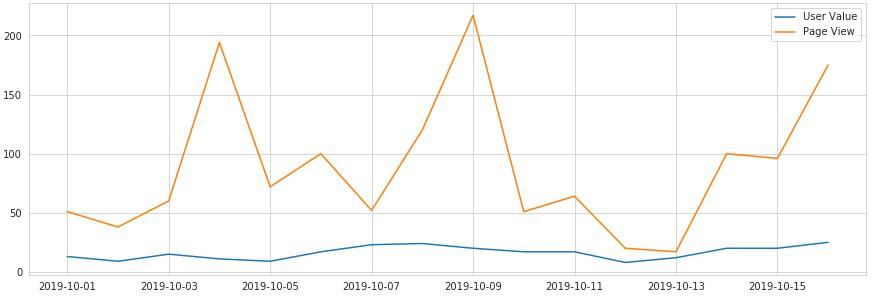
ページパス(URL)とページタイトルを取得しページビューが多い順に出力¶
ここからはこれまでとは違った出力をしてみます。
これまでは日付を指定し、その期間内の要素を取り出していましたが、次はどのページがもっとも開かれているか(閲覧されているか)を多い順に10件取得します。
ページビューを取り出すことによって、Webサイト内のトレンドを知ることができます。
まずは定義済みのコードを見てみましょう。
# HelloAnalytics.py
def get_report(analytics):
return analytics.reports().batchGet(
body={
'reportRequests': [{
'viewId': VIEW_ID,
'pageSize': 10, \# 追加
'dateRanges': [{"startDate": "7daysAgo", "endDate": "yesterday"}], \# 変更
'dimensions': [{'name': 'ga:pagePath'}, {'name': 'ga:pageTitle'}], \# 変更
'metrics': [{'expression': 'ga:pageviews'}], \# 変更
'orderBys': [{'fieldName': 'ga:pageviews', 'sortOrder': 'DESCENDING'}], \# 追加
}]
}
).execute()
「pageSize」は上位10件分のデータを取り出します。設定しなければ全て取得することになります。
「dateRanges」では、前日から過去7日間という設定です。
「dimensions」はページのURLと各ページのタイトルです。
「metrics」はページビューです。ここでの設定ではページビューに絞って実行します。
「orderBys」は並び順です。「fieldName」で要素を指定し「sortOrder」を降順としています。
ではdef print_response(response)関数を編集し実行してみます。
# HelloAnalytics.py
def print_response(response):
for row in response['reports'][0]['data']['rows']:
row_path = row['dimensions'][0]
row_title = row['dimensions'][1]
row_view = row['metrics'][0]['values'][0]
print(row_path, row_title,)
print(row_view)
def main():
analytics = initialize_analyticsreporting()
response = get_report(analytics)
print_response(response)
# api_plot(days, user_value, page_view)
実行します。

結果を見てみると、ページビューの多い順に出力されているのがわかります。
しかし私のWebサイト上ではブログサイトのホームである「Blog Learning」とサイト全体のホームである「ZerofromLight」のページビューまで取得されています。
できればブログ記事に絞ってページビューを取り出したい。
そんな時は「dimensionFilterClauses」を使って記事だけを取得するように設定します。
まずは編集後のコードから見ていきましょう。
# HelloAnalytics.py
def get_report(analytics):
return analytics.reports().batchGet(
body={
'reportRequests': [{
'viewId': VIEW_ID,
'pageSize': 10,
'dateRanges': [{"startDate": "7daysAgo", "endDate": "yesterday"}],
'dimensions': [{'name': 'ga:pagePath'}, {'name': 'ga:pageTitle'}],
'dimensionFilterClauses': [{'filters': [{'dimensionName': 'ga:pagePath', \# 追加
'expressions': ['/blogs/detail/']}]
}],
'metrics': [{'expression': 'ga:pageviews'}],
'orderBys': [{'fieldName': 'ga:pageviews', 'sortOrder': 'DESCENDING'}],
}]
}
).execute()
「dimensions」でページパス(ga:pagePath)を設定したのはフィルターを使って制御することが目的です。
「dimensionFilterClauses」ではdimensionNameで制御したい名前を与え、expressionsで内容を与えます。
私の場合は「/blogs/detail/」内に記事が納められていますので、detail内だけを取得するように設定しています。
そして先ほどと同じように実行してみると

過去7日間分の各記事のページビューだけを取得することができました。
最後にデータを可視化させてみたいと思います。
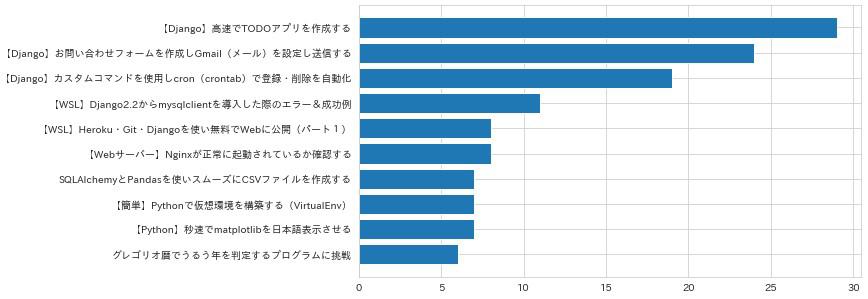
各記事のページビューを可視化¶
先ほどでもデータを可視化したとおりに、要素を格納するための空リストを用意しfor文で順番に格納していきます。
描画用の関数を折れ線グラフから棒グラフに変更しています。
# HelloAnalytics.py
# 空リスト
x_title = []
y_view = []
def print_response(response):
for row in response['reports'][0]['data']['rows']:
row_path = row['dimensions'][0]
row_title = row['dimensions'][1]
row_view = row['metrics'][0]['values'][0]
x_title.append(row_title) \# 追加
y_view.append(int(row_view)) \# 追加
print(row_path, row_title)
print(row_view)
""" 棒グラフに変更"""
def api_plot(x, y):
plt.figure(figsize=(9, 5))
plt.barh(x, y)
plt.show()
def main():
analytics = initialize_analyticsreporting()
response = get_report(analytics)
print_response(response)
api_plot(x_title, y_view)
実行してみます。
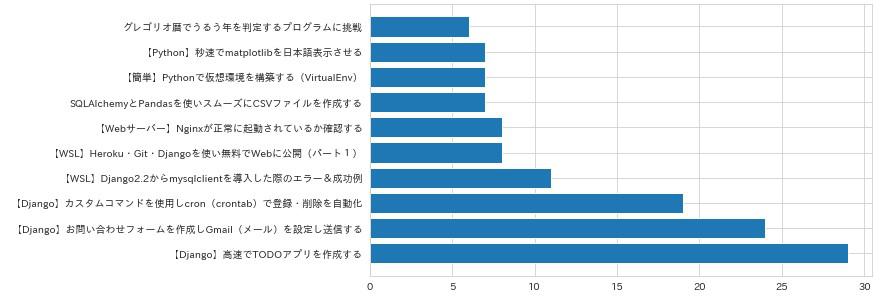
グラフは先に要素が読み込まれた順に表示されるので、降順に表示させるにはxとyをスライス(オフセット)で後ろの値から読み込ませるようにします。
# HelloAnalytics.py
# 棒グラフに変更
def api_plot(x, y):
plt.figure(figsize=(9, 5))
plt.barh(x[: :-1], y[: :-1]) # 変更
plt.show()
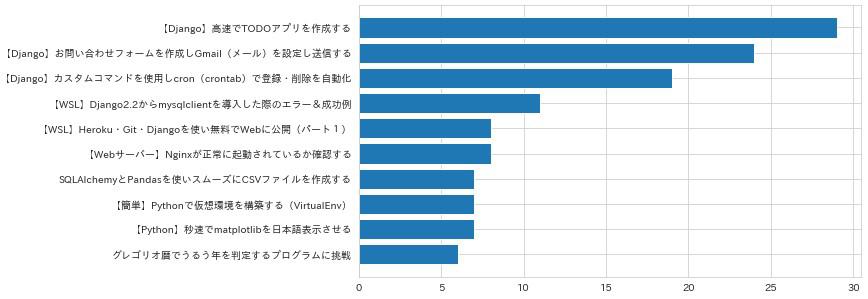
うまく表示されたでしょうか?
まだまだ深堀したい方は公式ドキュメント(レポートの作成)などを見て強化していってください。
他にもpandasなどの外部ライブラリを使用すればテーブル形式でデータを操作できたり簡単にCSVファイルにすることができます。
そしてDjangoフレームワークなどのアプリにも組み込むことができます。
あまり深堀しませんでしたがこれで以上となります。
最後までご覧いただきありがとうございました。
