【Python】構文解析器(係り受け解析)CaboChaの導入(エラー回避&成功例)
投稿日 2019年12月12日 >> 更新日 2023年3月2日

今回は、Python3で構文解析器(係り受け解析)のCaboChaの導入に関して書いていこうと思います。
ですので、ここでは簡単な実装に留めPythonで構文解析された要素を細かく抽出することに関しては、こちら「係り受け解析器のCaboChaを使って文章の関係性をNetworkXで描画する」をご参照ください。
では構文解析とは何か?
簡単に説明すると、文節に係ってくる関係性をコンピュータで解析し処理できる自然言語処理分野の1つと捉えています。
構文解析は係り受け解析とも言われ、解析結果を元にプログラムを加えることで、その文章では一体「何を伝えたいのか」などを見える化することができます。

例えばコメント欄などに構文解析器のフィルターを設けることで、概要をピンポイントでキャッチできるようなシステムが作るれるようになるかもしれません。
構文解析について分かりやすく説明されているサイトがあるので、理解を深めたい方はこちら「【第2回】自然言語処理の基礎技術“構文解析”とは?」をご参照ください。
その構文解析器のCaboChaでは、バックエンドで形態素解析器の「MeCab」と機械学習モデルの「SVM:サポートベクターマシン」が使われています。
詳しくはCaboCha公式ドキュメントへ
私自身CaboChaを導入していく過程で様々な壁にぶち当たったので、それらの壁を回避する方法と一緒にCaboChaを実装できるようになるまでを簡単にですが説明していこうと思います。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
| 使用ライブラリ | ライセンス |
|---|---|
| cabocha==0.1.4 | ? |
| cabocha-python==0.69 | BSD License, GNU Library or Lesser General Public License (LGPL) (BSD or LGPL) |
| mecab-python3==0.996.2 | BSD |
CaboChaに必要なソフトを順番にインストール¶
CaboChaを使えるようにするには、形態素解析器の「MeCabとMeCabの辞書」と言語処理に使われる「CRF++」、そして本体の「CaboCha」を導入する必要があります。
MeCabの実装が気になるという方は、過去記事にありますので宜しれければこちら「【Python】形態素解析器のMeCabを使って自然言語処理の実装」をご参照ください。
CRF++についてはこちらのサイトが参考になりました。
では必要なソフトから順番にシステムに導入していきたいと思います。
MeCabのインストール¶
まずMeCabを使えるようにするには以下のモジュールを導入します。
$ sudo apt install swig libmecab-dev
そして本体と辞書を導入します。
$ sudo apt install mecab mecab-ipadic-utf8
起動されれば成功です。
# 実行
$ mecab
形態素解析の次は構文解析に挑戦!
形態素 名詞,一般,*,*,*,*,形態素,ケイタイソ,ケイタイソ
解析 名詞,サ変接続,*,*,*,*,解析,カイセキ,カイセキ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
次 名詞,一般,*,*,*,*,次,ツギ,ツギ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
構文 名詞,一般,*,*,*,*,構文,コウブン,コーブン
解析 名詞,サ変接続,*,*,*,*,解析,カイセキ,カイセキ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
挑戦 名詞,サ変接続,*,*,*,*,挑戦,チョウセン,チョーセン
! 記号,一般,*,*,*,*,!,!,!
他にも様々なオプションが用意されているので、詳細はMeCabの公式ドキュメントをご参照ください。
Pythonで使えるようにするには、pipから導入します。
$ pip3 install mecab-python3
MeCabをPythonから実装する方法に関しては「【Python】MeCab(形態素解析器)を使用して文章をカテゴリー分類する」をご参照ください。
CRF++のインスール¶
CRF++をシステムに導入するには、ファイルが納められている開発者のGoogleDriveへ飛び、必要なファイルを一度ダウンロードします。
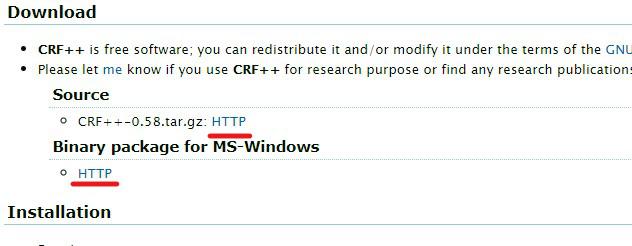
開発者のGoogleDriveへ飛ぶとファイルが納められているのが分かると思います。
※記事投稿時点の最新は「CRF++-0.58」
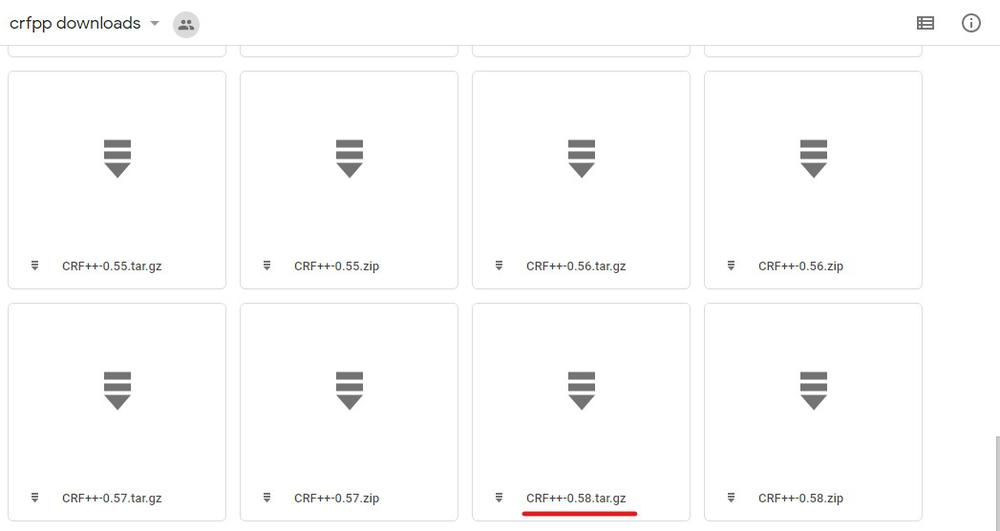
Linuxのwgetコマンドでファイルをダウンロードする方法もありますが、私の場合はダウンロード中にファイルが壊れてしまうという不具合に遭遇したので、サイトのインターフェイスから自身のPCにダウンロードしました。
※右上のダウンロードマークをクリック
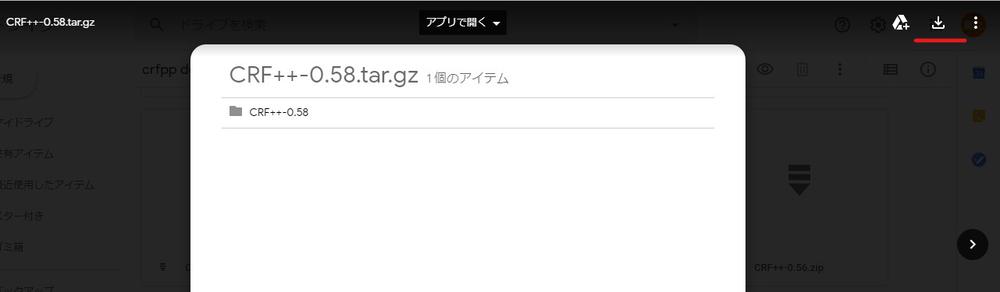
ダウンロードできたら作業ディレクトリへファイルを置き、tarコマンドでファイルを解凍します。
$ ls
CRF++-0.58.tar.gz
# 解凍
$ tar zxfv CRF++-0.58.tar.gz
$ ls
CRF++-0.58 CRF++-0.58.tar.gz
CRF++-0.58のディレクトリが作成されたら、cdコマンドで移動しそのディレクトリ上でインスールをしていきます。
$ cd CRF++-0.58
# インストールに必要な設定で、makefileが作成される
/CRF++-0.58$ ./configure
# ビルド(コンパイル)
/CRF++-0.58$ make
# チェック
/CRF++-0.58$ make check
# ビルドされたCRF++をインストール
/CRF++-0.58$ sudo make install
# システムのキャッシュに反映
/CRF++-0.58$ sudo ldconfig
これでCRF++を導入できたかと思います。
「cd ..」コマンドで元の作業ディレクトリに戻りましょう。
CaboChaのインストール¶
続いてCaboChaのインストールです。
導入工程はCRF++の流れと殆ど変わりません。
CaboChaファイルは公式ドキュメントからリンクを辿ってGoogleDriveのサイトへ飛ぶことができますが、一応添えておきます。「GoogleDrive:CaboChaファイル」
wgetコマンドもしくわサイトへ飛びファイルをダウンロードします。
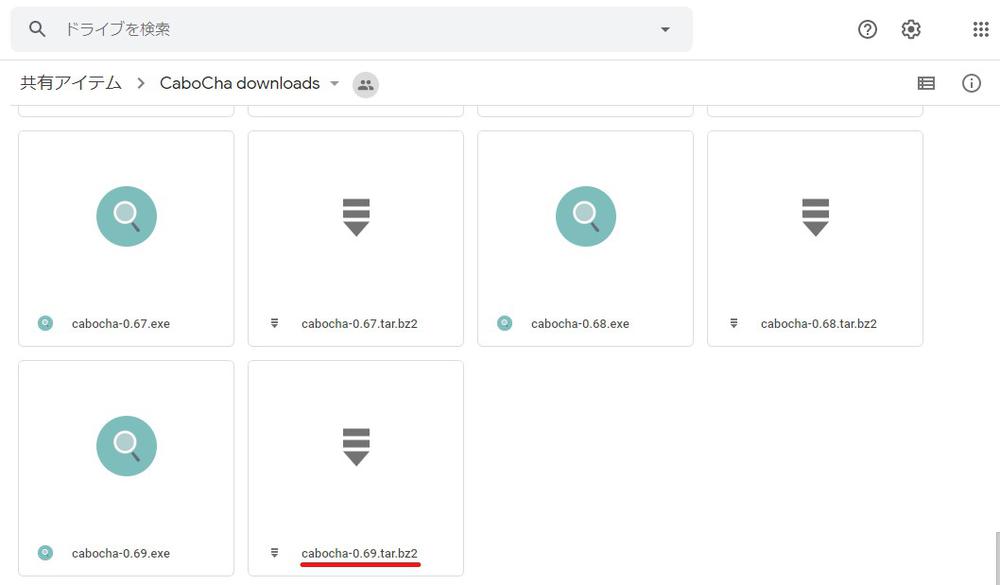
※記事投稿時点ではCaboCha-0.69が最新です。
ダウンロードしてきたファイルを作業ディレクトリに置き、解凍します。
$ ls
CRF++-0.58 CRF++-0.58.tar.gz cabocha-0.69.tar.bz2
# 解凍
$ bzip2 -dc cabocha-0.69.tar.bz2 | tar xvf -
$ ls
cabocha-0.69 CRF++-0.58 CRF++-0.58.tar.gz cabocha-0.69.tar.bz2
cabocha-0.69のディレクトリが作成されたら、cdコマンドで移動しそのディレクトリ上でインスールをしていきます。
$ cd cabocha-0.69
# インストールに必要な設定で、makefileが作成される
# オプションでMeCabの文字セットと合わせる
/cabocha-0.69$ ./configure --with-mecab-config=`which mecab-config` --with-charset=UTF8
# ビルド(コンパイル)
/cabocha-0.69$ make
# チェック
/cabocha-0.69$ make check
# ビルドされたCRF++をインストール
/cabocha-0.69$ sudo make install
# システムのキャッシュに反映
/cabocha-0.69$ sudo ldconfig
これで自身のシステム上でCaboChaが使えるようになったかと思います。
※エラー対策は下の方で説明
起動してみましょう。
# 実行
$ cabocha
形態素解析の次は構文解析に挑戦!
形態素解析の-D
次は---D
構文解析に-D
挑戦!
EOS
他にも様々なオプションが用意されているので、詳細はCaboChaの公式ドキュメントをご参照ください。
Pythonバインディングのインストール¶
ここからはCaboChaをPythonで実行できるように結び付けていきます。
CaboCha公式ドキュメントでも説明されていますが、GitHubに置かれているリポジトリ(ファイル類)を自身のPCにコピーし、その上で環境構築を行います。
CaboChaのリポジトリを入手しpipでインストールします。
# GitHubからリポジトリをコピー
$ git clone https://github.com/taku910/cabocha
# 移動
$ cd cabocha
# pythonを指定しpipでインストール
/cabocha$ pip3 install python/
この時点で、pipのパッケージ内では以下のようになっているかと思います。
/cabocha$ pip3 freeze
cabocha==0.1.4
mecab-python3==0.996.2
すでにPythonでCaboChaを使えるかと思いますが、別のアプローチからCaboChaを使用できるライブラリがあるので、そちらもインストールします。
/cabocha$ pip3 install git+https://github.com/kenkov/cabocha@0.1.4
/cabocha$ pip3 freeze
cabocha==0.1.4
cabocha-python==0.69
mecab-python3==0.996.2
さっそくPythonからCaboChaを実行していきますが、公式ドキュメントとは異なるアプローチで実装していきたいと思います。
※以下の実装は世間でよく伺える例です。
# test.py
import CaboCha
cabocha = CaboCha.Parser()
sentence = '形態素解析の次は構文解析に挑戦!'
print(sentence)
print('----------')
print(cabocha.parseToString(sentence))
tree = cabocha.parse(sentence)
print('----------')
print(tree.toString(CaboCha.FORMAT_LATTICE))
出力
形態素解析の次は構文解析に挑戦!
----------
形態素解析の-D
次は---D
構文解析に-D
挑戦!
EOS
----------
* 0 1D 1/2 1.538844
形態素 名詞,一般,*,*,*,*,形態素,ケイタイソ,ケイタイソ
解析 名詞,サ変接続,*,*,*,*,解析,カイセキ,カイセキ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
* 1 3D 0/1 -1.383327
次 名詞,一般,*,*,*,*,次,ツギ,ツギ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
* 2 3D 1/2 -1.383327
構文 名詞,一般,*,*,*,*,構文,コウブン,コーブン
解析 名詞,サ変接続,*,*,*,*,解析,カイセキ,カイセキ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
* 3 -1D 0/0 0.000000
挑戦 名詞,サ変接続,*,*,*,*,挑戦,チョウセン,チョーセン
! 記号,一般,*,*,*,*,!,!,!
EOS
要素を細かく抽出するプログラムに関しては、こちら「係り受け解析器のCaboChaを使って文章の関係性をNetworkXで描画する」をご参照ください。
エラー対策¶
エラーに関してですが、私が遭遇した事に限ります。
なので期待通りにいかなかったり解消されない場合もあるかと思うのでご了承願います。
せめてヒントになってくだされば幸いです。
CaboCha導入時のエラー¶
mekeコマンド等で失敗してしまう場合は、CRF++を導入していないか、もしくわそもそもファイル自体が古いかが考えられると思います。
私は最新版を使った事によりクリアできました。
- 最新版を導入するよう心掛ける
CaboChaが起動しない¶
一通りインストールが終わり、cabochaコマンドを打っても「error while loading shared libraries: libcrfpp.so.0: cannot open shared object file: No such file or directory」などが返ってしまう場合は、CaboChaソフトがキャッシュに反映されていない可能性があります。
私の環境下ですが、CaboChaがインストールされたら「/etc/ld.so.conf.d」ディレクトリ内の「libc.conf」ファイルでは以下のようになっています。
# vimエディターで開く
$ sudo vi /etc/ld.so.conf.d/libc.conf
※vimエディターを終了する場合は、キーボード左上「Esc」を押し、コロン「:」と「w」「q」で上書き保存。
# libc.conf
/usr/local/lib
上記のようになっていたら「/etc/ld.so.cache」に反映させます。
キャッシュを反映させるには、CRF++やCaboChaを導入した工程の「sudo make instlle」をした後に、「sudo ldconfig」コマンドを打ちます。
# システムのキャッシュに反映
$ sudo ldconfig
これでシステムに反映され「error while loading shared libraries: libcrfpp.so.0: cannot open shared object file: No such file or directory」は解消されるかと思います。
CaboCha起動時エラー¶
一通りインストールが終わり、CaboChaを起動したところ以下のようなエラーが起こる場合。
「morph.cpp(187) [charset() == decode_charset(dinfo->charset)] Incompatible charset: MeCab charset is euc-jp, Your charset is UTF8」
# 実行
$ cabocha
morph.cpp(187) [charset() == decode_charset(dinfo->charset)] Incompatible charset: MeCab charset is euc-jp, Your charset is UTF8
考えられるのは、CaboChaのインストール時で「MakeFile」を作成する「./configure」コマンドの時にオプションで「--with-charset=UTF8」を設定していなかったか、もしくわ形態素解析器側のMeCab辞書の文字セットがUTF8になっていないか。
前者の方法で、もし「./configure」にオプション設定していなかったら、ファイルの解凍からやりなおしてインストールすることをお勧めします。
# 解凍
$ bzip2 -dc cabocha-0.69.tar.bz2 | tar xvf -
$ ls
cabocha-0.69 CRF++-0.58 CRF++-0.58.tar.gz cabocha-0.69.tar.bz2
$ cd cabocha-0.69
# インストールに必要な設定で、makefileが作成される
# オプションでMeCabのエンコードと合わせる
/cabocha-0.69$ ./configure --with-mecab-config=`which mecab-config` --with-charset=UTF8
# ビルド(コンパイル)
/cabocha-0.69$ make
# チェック
/cabocha-0.69$ make check
# ビルドされたCRF++をインストール
/cabocha-0.69$ sudo make install
# システムのキャッシュに反映
/cabocha-0.69$ sudo ldconfig
後者の方法では、MeCabの設定ファイルを編集します。
私の環境では、「/etc/mecabrc」という階層でファイルが置かれているので、そのファイル内を編集します。
※必要であれば「mecabrc」をコピーしておく。
# vimエディターで編集
$ sudo vi /etc/mecabrc
※vimエディターを終了する場合は、キーボード左上「Esc」を押し、コロン「:」と「w」「q」で上書き保存。
# mecabrc
# mecabの辞書をutf8に変更
dicdir = /var/lib/mecab/dic/ipadic-utf8
「.cabocharc」を「mecabrc」と同じ階層に作成して、mecabrcを読み込みよう設定する。
$ sudo vi /etc/.cabocharc
※vimエディターを終了する場合は、キーボード左上「Esc」を押し、コロン「:」と「w」「q」で上書き保存。
# .cabocharc
mecabrc = /etc/mecabrc
ここまでが私の躓いたポイントとなります。
参考になったかは不明ですが、ストレスなく導入し快適な自然言語処理を実装していきましょう。
それでは以上となります。
最後までご覧いただきありがとうございました。
