係り受け解析器のCaboChaを使って文章の関係性をNetworkXで描画する
投稿日 2019年12月14日 >> 更新日 2023年3月2日
今回は構文解析の基礎技術である係り受け解析器CaboChaを使って、解析された文章の関係性をNetworkXという描画ライブラリで実装していきたいと思います。
CaboChaの導入に関してはこちら「【Python】構文解析器(係り受け解析)CaboChaの導入(エラー回避&成功例)」で紹介しているので必要であればご参照ください。
Pythonの外部パッケージであるNetworkXは、複雑なネットワーク構造をもったデータの分析などを目的に開発されており、Pythonのグラフ描画ライブラりのMatplotlibを使用してネットワーク構造を可視化することができます。
上図にあるのがまさにそうで、関係先のノード(丸)だったり重要度の高いノードを強調表示させたりといったことを実装出来ます。
最初に簡単ではありますがNetworkXの実装をしてから、係り受け解析器のCaboChaを使ってネットワーク図の描画をしたいと思います。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
| 使用ライブラリ | ライセンス |
|---|---|
| cabocha==0.1.4 | ? |
| cabocha-python==0.69 | BSD License, GNU Library or Lesser General Public License (LGPL) (BSD or LGPL) |
| japanize-matplotlib==1.0.5 | MIT |
| matplotlib==3.1.2 | PSF |
| mecab-python3==0.996.2 | BSD |
| networkx==2.4 | BSD |
NetworkX¶
それでは導入から始めていきたいと思います。
一緒にネットワーク図の描画もするので、「matplotlib」と日本語のテキストを適用できる「japanize_matplotlib」をそれぞれインストールしていきます。
※Linuxの場合グラフの可視化でGUIの設定が必要になるかもしれません。
$ pip3 install networkx
$ pip3 install matplotlib japanize_matplotlib
インストールが完了したらさっそくノードを描画してみましょう。
公式ドキュメントのチュートリアルに従いながら実装していきます。
# test.py
import matplotlib.pyplot as plt
import japanize_matplotlib
import networkx as nx
# 空のグラフを作成
G = nx.Graph()
# ノードを追加
G.add_node(1)
# グラフを描画
nx.draw(G)
plt.show()
1つのノードが作成されたので、以下のようにイメージされます。

ではノードを9個追加し、10個表示させてみます。
# test.py
import matplotlib.pyplot as plt
import japanize_matplotlib
import networkx as nx
# 空のグラフを作成
G = nx.Graph()
# ノードを追加
G.add_node(1)
# リストで追加
G.add_nodes_from([2, 3, 4, 5, 6, 7, 8, 9, 10])
# グラフを描画
nx.draw(G)
plt.show()
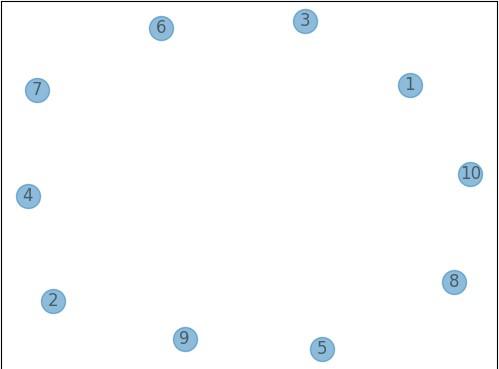
「add_nodes_from」にリストを渡すことでノードを追加することができます。

ノードにラベル付けさせる場合は、「nx.draw_networkx()」メソッドを使用します。
# test.py
import matplotlib.pyplot as plt
import japanize_matplotlib
import networkx as nx
# 空のグラフを作成
G = nx.Graph()
# ノードを追加
G.add_node(1)
# リストで追加
G.add_nodes_from([2, 3, 4, 5, 6, 7, 8, 9, 10])
# グラフを描画
# 引数のwith_labels=True(デフォルト)
nx.draw_networkx(G, with_labels=True, alpha=0.5)
plt.show()
次に関係性のあるノードとノードに線で紐づけて描画します。
# test.py
import matplotlib.pyplot as plt
import japanize_matplotlib
import networkx as nx
G = nx.Graph()
G.add_node(1)
G.add_nodes_from([2, 3, 4, 5, 6, 7, 8, 9, 10])
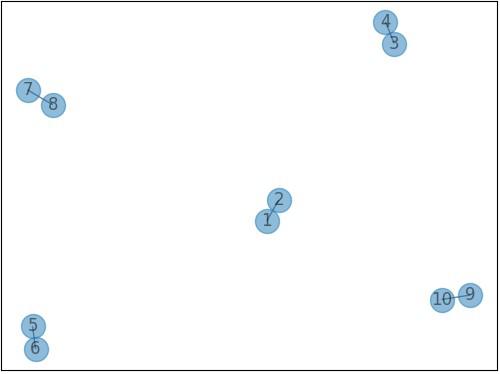
# 5つのエッジを追加
G.add_edge(1, 2)
G.add_edge(3, 4)
G.add_edge(5, 6)
G.add_edge(7, 8)
G.add_edge(9, 10)
nx.draw_networkx(G, with_labels=True, alpha=0.5)
plt.show()
「add_edge()」に結びたいノードを与えるとそれぞれがまとまって以下のようになります。
「add_edges_from()」にリストを与えて紐づけることもできます。
# test.py
import matplotlib.pyplot as plt
import japanize_matplotlib
import networkx as nx
G = nx.Graph()
G.add_node(1)
G.add_nodes_from([2, 3, 4, 5, 6, 7, 8, 9, 10])
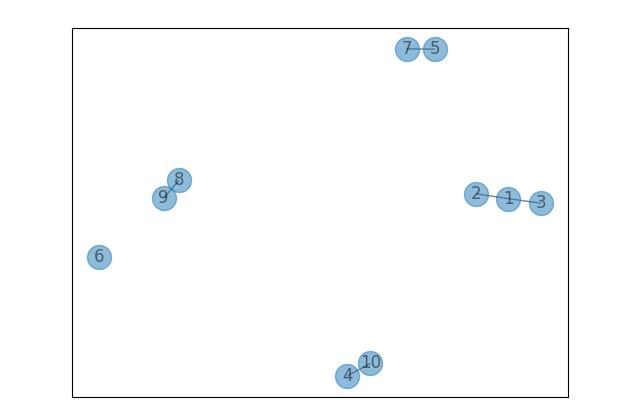
# 6以外それぞれに紐づけ
G.add_edge(8, 9)
G.add_edges_from([(1, 2), (1, 3), (5, 7), (4, 10)])
nx.draw_networkx(G, with_labels=True, alpha=0.5)
plt.show()
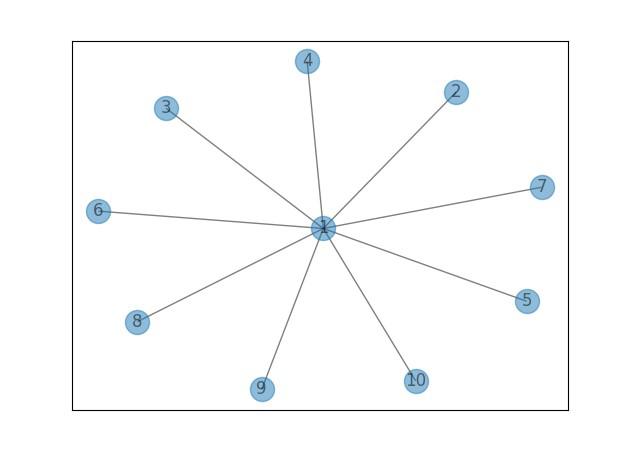
各ノードは一意なので、1ヵ所のノードに集中すると1対多の関係性で表現されます。
# test.py
import matplotlib.pyplot as plt
import japanize_matplotlib
import networkx as nx
G = nx.Graph()
G.add_node(1)
G.add_nodes_from([2, 3, 4, 5, 6, 7, 8, 9, 10])
# ノード1に集中
G.add_edges_from([(1, 2), (1, 3), (1, 4), (1, 5), (1, 6),
(1, 7), (1, 8), (1, 9), (1, 10)])
nx.draw_networkx(G, with_labels=True, alpha=0.5)
plt.show()
テキストファイルからノードを追加し描画することもできます。
「edge_list.txt」
# test.py
import matplotlib.pyplot as plt
import japanize_matplotlib
import networkx as nx
# 同じ階層にあるテキストファイル
G = nx.read_edgelist('edge_list.txt')
nx.draw_networkx(G, with_labels=True, alpha=0.5)
plt.show()

ここでは簡単な説明に留めているので、詳しい内容については公式のチュートリアルをご参照ください。
CaboChaの解析結果をネットワーク図で描画¶
では本題の係り受け解析結果をNetworkXを使って描画していきたいと思います。
冒頭でも言いましたが、CaboChaが既に導入されている前提で進めて行きますので、お済みでない方はこちら「【Python】構文解析器(係り受け解析)CaboChaの導入(エラー回避&成功例)」をご参照ください。
まずはCaboCha単体での出力結果から実装していきたいと思います。
文章の解析結果を出力¶
解析結果の出力に関してはこちら「CaboCha & Python3で文節ごとの係り受けデータ取得」を参考にさせて頂きました。
文章を与えて結果を出力
# test_2.py
import CaboCha
cabocha = CaboCha.Parser()
sentence = '形態素解析の次は構文解析に挑戦しているが、苦戦を強いられている。'
tree = cabocha.parse(sentence)
print(sentence)
print('----------')
for i in range(tree.size()):
token = tree.token(i)
if token.chunk:
print(token.chunk.link,
token.chunk.head_pos,
token.chunk.func_pos,
token.chunk.score)
print(token.surface,
token.feature)
出力に関する詳細
- token.chunk.link(係り先ID)
- token.chunk.head_pos(主辞)
- token.chunk.func_pos(機能語)
- token.chunk.score(スコア)
- token.surface(単語)
- token.feature(品詞・カナ)
出力結果
形態素解析の次は構文解析に挑戦しているが、苦戦を強いられている。
----------
1 1 2 1.5388439893722534
形態素 名詞,一般,*,*,*,*,形態素,ケイタイソ,ケイタイソ
解析 名詞,サ変接続,*,*,*,*,解析,カイセキ,カイセキ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
3 0 1 1.3173139095306396
次 名詞,一般,*,*,*,*,次,ツギ,ツギ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
3 1 2 2.7969000339508057
構文 名詞,一般,*,*,*,*,構文,コウブン,コーブン
解析 名詞,サ変接続,*,*,*,*,解析,カイセキ,カイセキ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
5 1 4 -3.3632218837738037
挑戦 名詞,サ変接続,*,*,*,*,挑戦,チョウセン,チョーセン
し 動詞,自立,*,*,サ変・スル,連用形,する,シ,シ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
いる 動詞,非自立,*,*,一段,基本形,いる,イル,イル
が 助詞,接続助詞,*,*,*,*,が,ガ,ガ
、 記号,読点,*,*,*,*,、,、,、
5 0 1 -3.3632218837738037
苦戦 名詞,サ変接続,*,*,*,*,苦戦,クセン,クセン
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
-1 0 3 0.0
強い 動詞,自立,*,*,一段,未然形,強いる,シイ,シイ
られ 動詞,接尾,*,*,一段,連用形,られる,ラレ,ラレ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
いる 動詞,非自立,*,*,一段,基本形,いる,イル,イル
。 記号,句点,*,*,*,*,。,。,。
他の要素を省いて出力する
# test_2.py
import CaboCha
cabocha = CaboCha.Parser()
sentence = '形態素解析の次は構文解析に挑戦しているが、苦戦を強いられている。'
tree = cabocha.parse(sentence)
print(sentence)
print('----------')
""" チャンク内のブロックごとに格納する変数 """
text = ''
for i in range(tree.size()):
token = tree.token(i)
""" チャンク内のブロックごとで繰り返す """
if token.chunk:
print(token.chunk.link)
text = token.surface
else:
text += token.surface
""" 次のチャンクが流れてくるタイミングで出力 """
if i == tree.size() - 1 or tree.token(i+1).chunk:
print(text)
※chunk(チャンク)のブロック要素取り出しは、直感的な作業になるので色々な方法を見つけて試して行きましょう。
出力
形態素解析の次は構文解析に挑戦しているが、苦戦を強いられている。
----------
1
形態素解析の
3
次は
3
構文解析に
5
挑戦しているが、
5
苦戦を
-1
強いられている。
係り受け解析された要素を係り先IDを使って関係先を出力する。
# test_2.py
import CaboCha
cabocha = CaboCha.Parser()
sentence = '形態素解析の次は構文解析に挑戦しているが、苦戦を強いられている。'
tree = cabocha.parse(sentence)
print(sentence)
print('----------')
chunks = [] # 解析結果格納用
text = ""
for i in range(tree.size()):
token = tree.token(i)
if token.chunk:
chunk_id = token.chunk.link # 係り先ID
text = token.surface
else:
text += token.surface
""" ID内の最後の要素のタイミングで解析結果とIDを辞書に格納 """
if i == tree.size() - 1 or tree.token(i+1).chunk:
chunks.append({'c': text, 'to': chunk_id})
""" IDが0以上だった場合係り元と係り先を出力 """
for chunk in chunks:
if chunk['to'] >= 0:
print(chunk['c'] + " → " + chunks[chunk['to']]['c'])
出力
形態素解析の次は構文解析に挑戦しているが、苦戦を強いられている。
----------
形態素解析の → 次は
次は → 挑戦しているが、
構文解析に → 挑戦しているが、
挑戦しているが、 → 強いられている。
苦戦を → 強いられている。
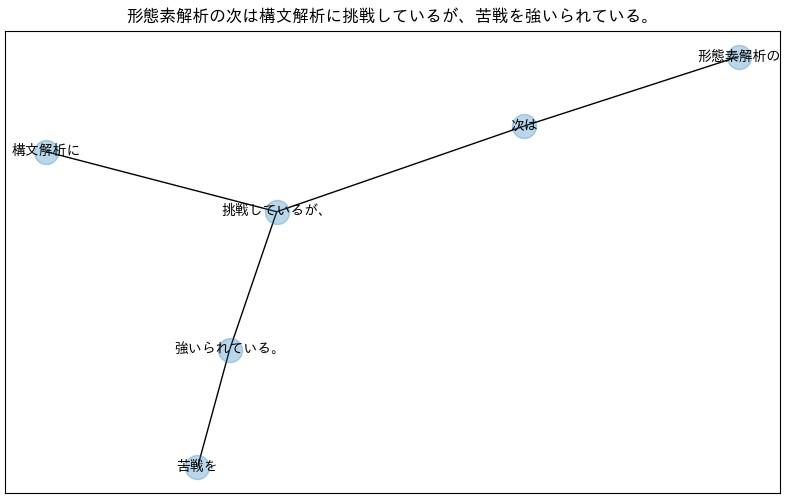
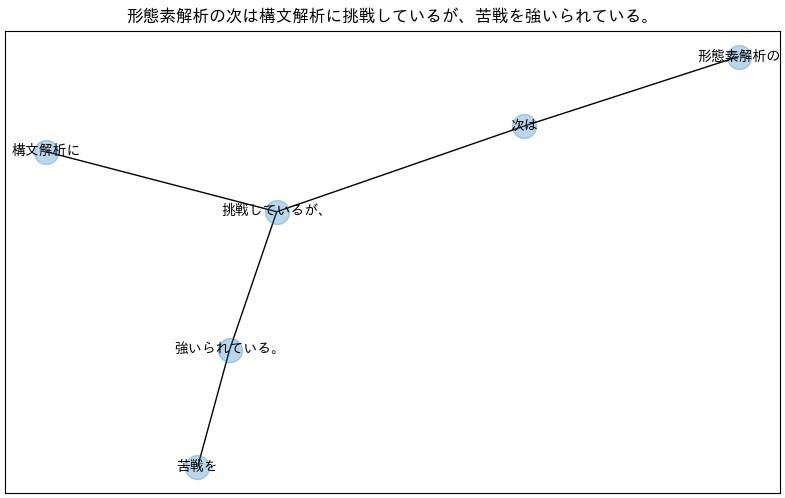
この出力結果を元にNetworkXを使ってネットワーク図を描画していきたいと思います。
関係性のある文章をネットワーク図で描画¶
流れとしては、先ほど出力された結果をNetworkXのノードが読み込められるような行間でテキストファイルに保存し、保存されたテキストファイルを読み込んでネットワーク図を描画させます。
追加されるコードは、これまでの実装に加えテキストファイル関連の操作のみになるので、合わせ技のような形になります。
イメージとしては、以下のようなテキストファイルが自動で作成され、NetworkXがノードやエッジの位置関係を読み込めるように行間を空けて保存しています。
「chunks.txt」

# test_3.py
import matplotlib.pyplot as plt
import japanize_matplotlib
import networkx as nx
import CaboCha
cabocha = CaboCha.Parser()
sentence = '形態素解析の次は構文解析に挑戦しているが、苦戦を強いられている。'
tree = cabocha.parse(sentence)
chunks = []
text = ""
for i in range(tree.size()):
token = tree.token(i)
if token.chunk:
chunk_id = token.chunk.link
text = token.surface
else:
text += token.surface
if i == tree.size() - 1 or tree.token(i+1).chunk:
chunks.append({'c': text, 'to': chunk_id})
""" テキストファイルに格納用の空文字変数 """
chunk_text = ''
for chunk in chunks:
if chunk['to'] >= 0:
""" 文字列&スペース&改行でエッジの並びにする """
chunk_text += str(chunk['c'])
chunk_text += ' '
chunk_text += str(chunks[chunk['to']]['c'])+'\n'
# print(chunk_text)
""" テキスト書き込み """
with open('chunks.txt', 'w') as f:
f.write(chunk_text)
""" テキストの読み込み """
G = nx.read_edgelist('chunks.txt')
""" 図のサイズ """
plt.figure(figsize=(10, 6))
""" 日本語設定など """
nx.draw_networkx(G, font_size=10, font_family='IPAexGothic', alpha=0.5)
plt.title(sentence)
plt.show()
出力できれば成功です。
今回は非常に高機能なCaboChaとNetworkXを使った係り受け解析の描画を実装しました。
高機能さ故に操作も難しいかと思いますが、すばらしいライブラリの機能を物にできるようどんどん開発をしていきましょう。
以上となります。
最後までご覧いただきありがとうございました。
