データ分析・機械学習の初心者からプロが集まるプラットフォームKaggle(カグル)の概要
投稿日 2020年2月11日 >> 更新日 2023年3月2日
今回は世界中のデータサイエンティストが集うと言われているKaggle(カグル)について解説していこうと思います。
「Kaggleを触ったことはあるけど実はよく知らない人」や「データ分析や機械学習をこれからやるつもりの人」に向けてKaggleの概要、特徴、魅力などを簡単に紹介していきたいと思います。
そして実際にKaggleアカウントを取得してデータセットをダウンロードするまでの内容を解説していきたいと思います。
Kaggleの簡単な概要¶
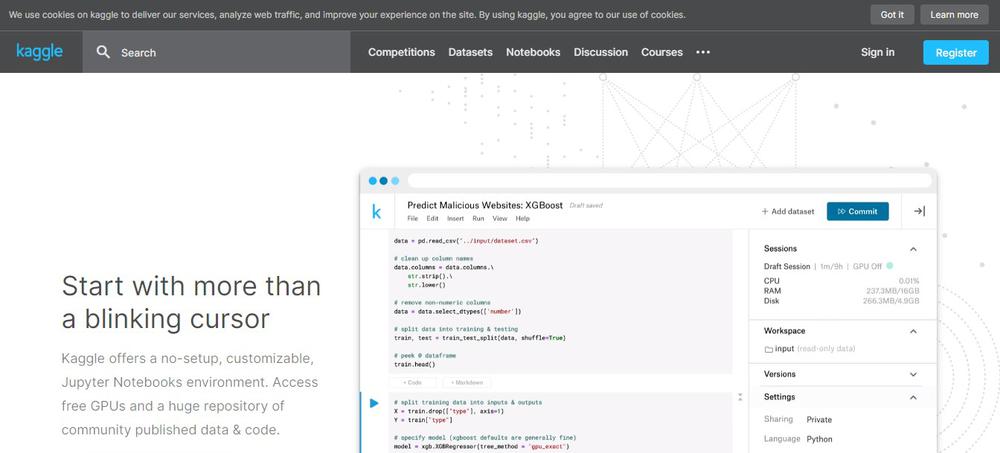
Kaggleは2017年にGoogleと統合し、Googleの子会社となりました。
なぜKaggleにデータサイエンティストの卵やプロフェッショナルな方々が集まるのか?
それはKaggleがデータサイエンティストの為のSNSとして活用することができ、データ分析や機械学習についての最新情報が飛び交っているからと言われています。
Kaggleアカウントを取得することによって、「データセット」をダウンロードできたり、「コンペ(大会)」に参加でたり、世界各地のデータサイエンティストと「討論や情報交換」が行えたりと、初心者やプロフェッショナルな人にとっても素晴らしい環境であること。
中でもKaagle内において各ユーザーは「Competitions(競争)」「Datasets(データセット)」「Notebooks(ノートブック)」「Discussions(ディスカッション)」の各カテゴリーの専門分野で、優れた提出物を公開した場合にはメダルが授与されます。
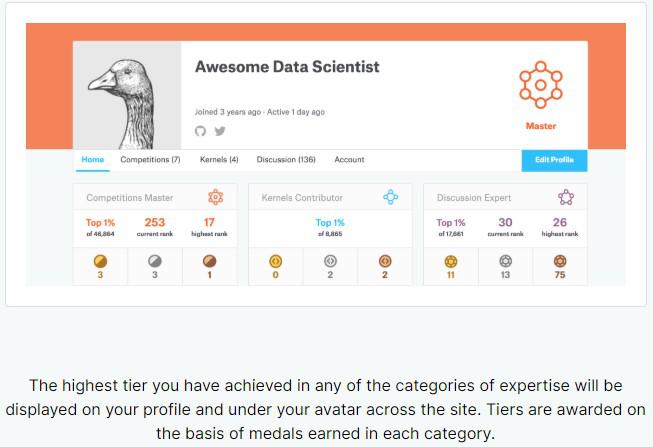
メダルは金・銀・銅、そしてポイントが付与されます。
メダルやポイントに応じて各ユーザーは次のようなパフォーマンス層に分かれます。
- Novice(初心者)→コミュニティに参加
- Contributor(寄稿者)→プロフィールを完成させ、Kaggleプラットフォームを探索
- Expert(専門家)→複数のカテゴリーでKaggleに関する重要な作業を完了など
- Master(主人)→1つ以上のカテゴリーで卓越性を実証
- Grandmaster(グランドマスター)→1つ以上のカテゴリーで傑出したパフォーマンスを実証
詳しくはKaggleのランキング詳細へ
そして全てが英語でのやり取りとなっているので、積極的に参加していくことで「英語力」も身に付くかと思います。
他にも、様々な企業が主催するCompetitions(コンペティション)という大会に参加する事で、上位者には賞金が与えられます。
そしてKaggle内で活発に活動している人のことをKaggler(カグラー)と呼び、殆どのコンテンツが無料で受けられるので、初心者にとっては魅力しかありません。
個人的に有難いと思ったサービスは、無料でデータサイエンティストとしての教育が受けられる「Courses(コース)」という項目です。
もちろん内容は全て英語ですが、最初は必要な部分だけ翻訳機能を使い、あとはコードを見ながらデータ分析で重要な流れを体系的に慣らして行けばよいかと思います。
そしてプロフェッショナルな先陣データサイエンティストから学ぶ環境がほぼ整っているので、最速でスキル向上ができると言われています。
Kaggleの各サービス詳細¶
Kaggleの代表的なサービスでは
- Competitions(コンペティション)
- Datasets(データセット)
- Notebooks/Kernels(ノートブック/カーネル)
- Discussions(ディスカッション)
- Courses(コース)
- ・・・(その他色々)
があります。
他にもデータ分析者の「求人雇用」だったり、「ユーザーランキング」という最も評価が与えられているユーザーアカウントの順位も確認することができます。
それでは代表的なサービスの内容を順番に見ていきましょう。
Competitions(コンペティション)¶
コンペティション(競争・大会)では、あらゆる企業や団体が課題を出し、その課題に対してコンペ参加者が自ら構築した分析モデルの精度を競うサービスです。
「競う」ということから、出題された課題であるデータセットを個人やチームが分析し、その結果を決められたファイル形式やフォーマットで提出し、Kaggleのスコアトップを目指します。
トップ5内に入ることで、賞金を受け取ることができるのも人気の1つと言えるでしょう。
Datasets(データセット)¶
データセットでは、さまざまなデータが公開されています。
データ分析初心者の登竜門として有名なデータセット「タイタニック号」はもちろんのこと、YouTube動画の分析だったり、不動産価格、労働統計データなどありとあらゆるデータが集まっています。
ただし、Kaggleの利用規約をしっかり読んだうえで、各データセットの扱いには注意が必要です。
Notebooks/Kernels(ノートブック/カーネル)¶
ノートブックもしくわカーネルでは、Kaggler(カグラー)の方々が分析し構築した一連のコードを公開しているサービスです。
初心者である間は、とにかく先陣カグラーのコードを参考にして学んで行くのも有りかと思います。
Jupyterノートブック形式で公開されているため、扱った事がある人にとっては馴染みやすいし読みやすいです。
アカウントを取得することによって、自分のアイディアや技術を発信し共有することもできます。
Discussions(ディスカッション)¶
ディスカッション(討論)では、カグラーのための掲示板となっています。
データ分析や機械学習に関わる色々な意見交換や最新情報などのコミュニケーションを取ることができる場となっています。
データサイエンス力と合わせて英語力を鍛えるためにも、興味のあるテーマがあったら積極的に参加する事も方法の1つですね。
Courses(コース)¶
コースでは、データサイエンティストになるために最速で学べる無料のマイクロコース(教育コンテンツ)が揃っています。
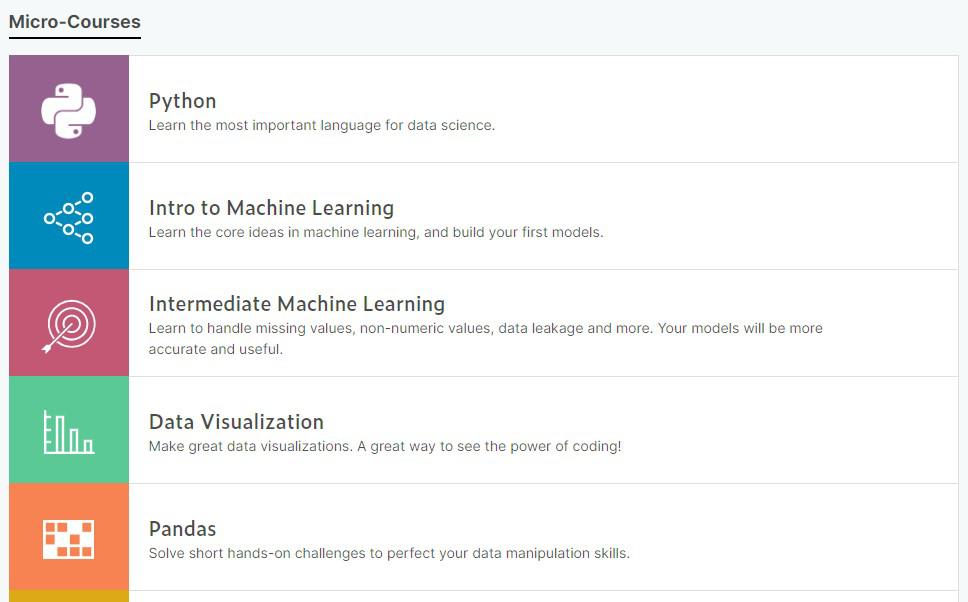
マイクロコースは以下のようなスキルを学ぶことができます。
- Python
- 機械学習の紹介
- 中級機械学習
- データの可視化
- Pandas
- 特徴エンジニアリング
- 深層学習(ディープラーニング)
- SQLの概要
- 高度なSQL
- 地理空間分析
- マイクロチャレンジ
- 機械学習の説明可能性
- 自然言語処理
内容は全て英語となっているので、英語が得意な方は羨ましい限りです。
「・・・」(その他)¶
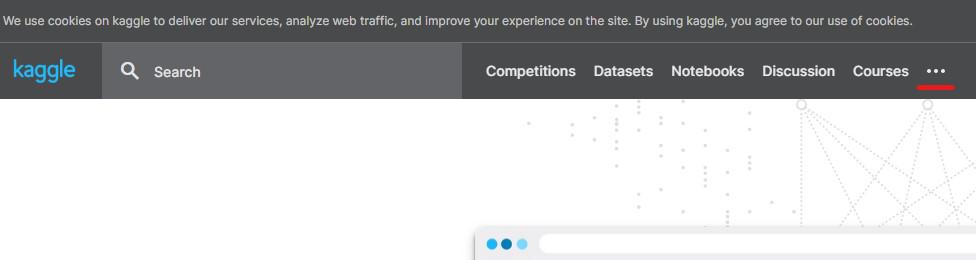
「・・・」にカーソルを合わせると、以下のような情報がボップアップされます。
- Jobs(仕事)
- User Rankings(ユーザーランキング)
- Tags(タグ)
- Blog(ブログ)
- Documentation(ドキュメンテーション)
- Progression(進行)
- Host a Competition(コンテストを開催する)
- Support/Contact(サポート/お問い合わせ)
- Team・Terms・Privacy(チーム・利用規約・プライバシー)
ドキュメンテーションを開いてみると、先ほど説明しきれなかった各サービスのより細かい内容や注意事項などを調べることができます。
サービスを利用するに当たって、Kaggle内で利用できるコンテンツまたはデータに関する権利などの違反をうっかり犯してしまわないように、利用規約も逐次確認しておきましょう。
Kaggleを始める¶
Kaggleの概要を簡単に理解したところで、Kaggleアカウントを取得しデータセットをダウンロードしていきましょう。
アカウントを取得していない場合、データセットの取得やコンペに参加する事ができないので、利用規約に同意できる方のみサービスを受けられます。
なお、13歳~17歳の方は、保護者の検証可能な同意が必要との事です(プライバシーポリシー)。
アカウントを取得¶
まずはナビゲーションバー右端の「Register(登録)」をクリックします。
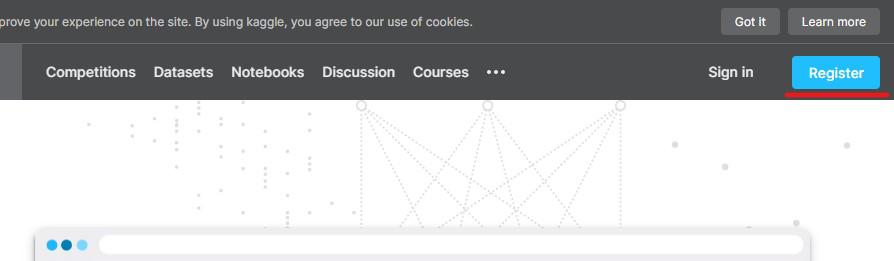
すると登録画面が表示されるので、どちらか選択をして必要事項を記入します。
恐らく確認メールなどの通知が届くので、不備や漏れ、利用規約に同意できれば登録が完了となります。
そして登録が完了し、Kaggleのホームページにて「Sign in」をすると、他ユーザーのニュースフィードがアップされるページに遷移されます。
データセットをダウンロードしPythonで出力¶
データセットは探せば幾らでもありますが、最初はKaggleでも推奨されている「タイタニックコンペティション」のデータセットからダウンロードしていきましょう。
お求めのデータセットが分かっていれば、内部検索エンジンを使用して見つけることもできます。
「titanic」と打ち込むと、幾つかヒットします。

「titanic」と打ち込んだままエンターを押すと、結果に関連するコンテンツが表示されます。
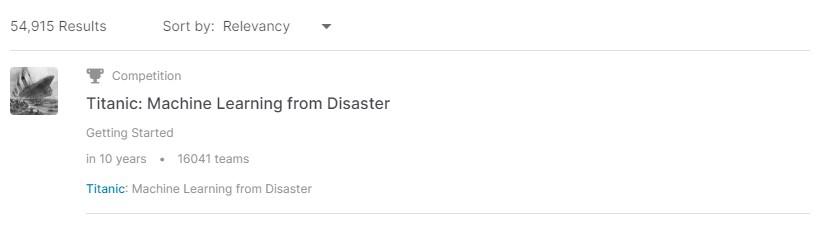
「titanic」のコンテンツをクリックしたら、コンテンツのナビゲーションメニューがあるので、そのナビ内の「Data」をクリックします。
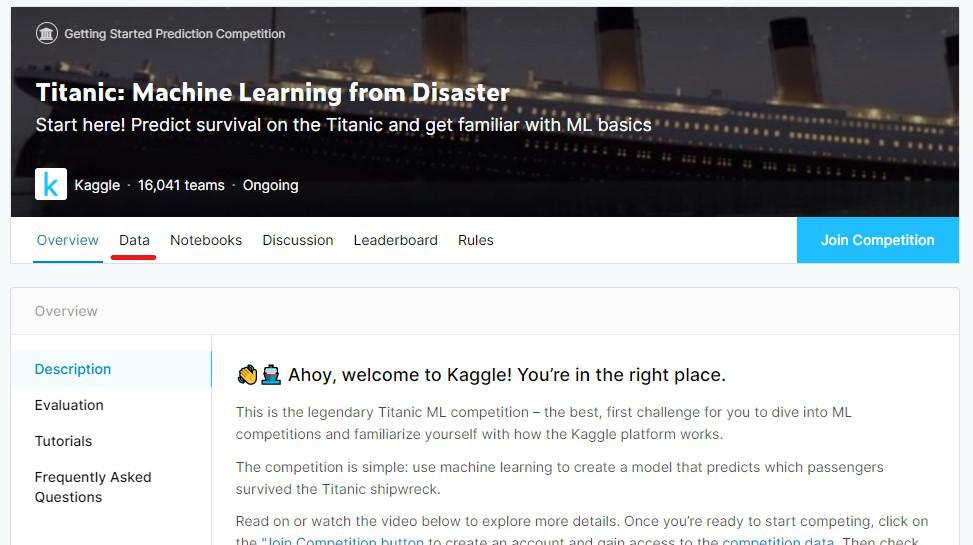
「Data」を開いたら、下図の画像右下の「Download All」をクリックすることで、ZIPファイルとしてデータセットをPCにダウンロードできます。
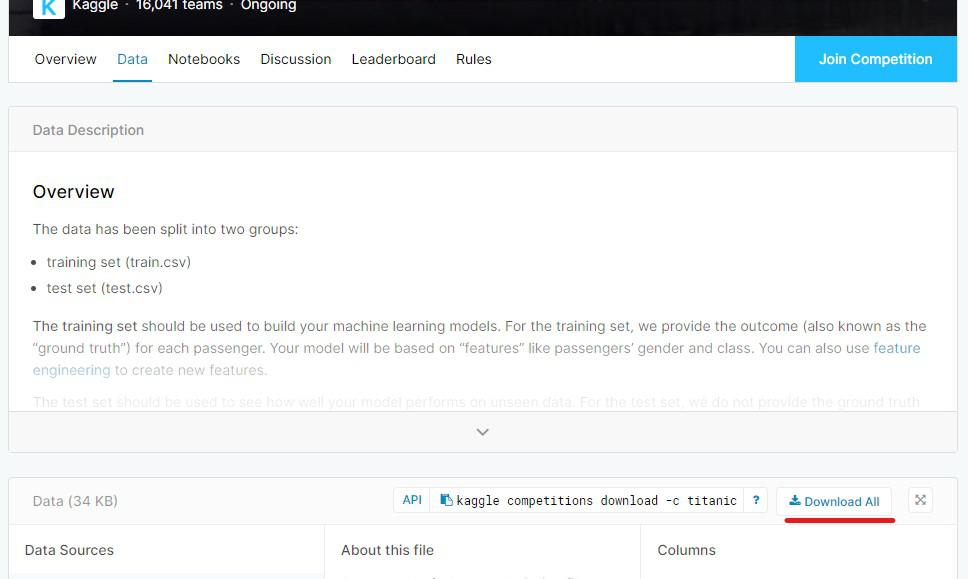
それではさっそく、Pythonを使って中身を確認してみましょう。
Pythonの外部ライブラリであるPandasというツールを使うことによって、CSVファイルやJSONファイルを表形式のデータフレームとして出力することができます。
pipでインストールできます。
$ pip3 install pandas
先ほどダウンロードしたZIPファイルを作業ディレクトリへ配置し解凍します。
解答されると、以下のようなファイルが現れます。
- gender_submission.csv
- test.csv
- train.csv
ファイルはテスト用と訓練用に分けられていますが、訓練用の「train.csv」をPandasで読み込んで表を出力しみましょう。
# 実行
import pandas as pd
titanic_df = pd.read_csv('train.csv')
titanic_df.head()
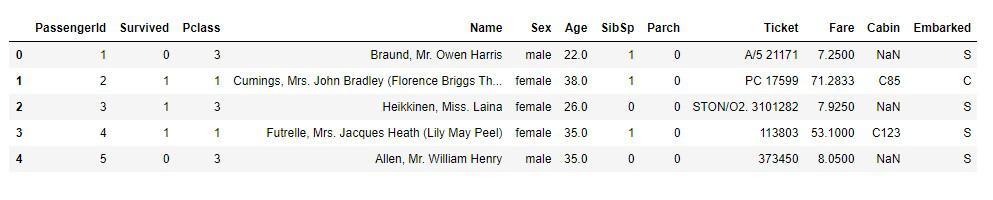
ひとまずデータの中身を確認することができました。
分析をするに当たっては、下図のタイタニックコンペティション内の「Tutorials」で流れを確認するか、「NotebooksもしくわKernels」で先陣データサイエンティストのコードを学ばせてもらいながら進むか、人それぞれ自由です。
「タイタニック」は非常に有名な素材なので、調べると様々な方が説明してくれているサイトも見つかるはずです。
Kaggleでは個人でも仲間でも黙々と学ぶ事ができ、スキルアップできる場として非常に有難い環境です。
コンペやユーザーランキングといったモチベーションに繋がるようなイベントもあるので、楽しい分析・研究ライフを送れるかと思います。
Kaggleグランドマスターを目指して頑張りましょう!
それでは以上となります。
最後までご覧いただきありがとうございました。
