【データ分析】Pythonのdatetimeとjpholidayを使って祝日・第何何曜日(週数・週番)のデータセットを作成
投稿日 2020年2月17日 >> 更新日 2023年3月2日
今回はPython標準ライブラリのdatetimeモジュールとPython外部ライブラリのjpholidayを使用して、国民の祝日や月の第何何曜日(週数・週番)という日時表記をデータセットとして作成していきたいと思います。
日時表記のデータセットをどのように活用していくのか?
私の場合ですと、Webサイトのアクセス数を機械学習で予測する際に必要だったからです。
Googleアナリティクスなどで時系列のアクセスデータを眺めていると、明らかなに週ごとで似た動きをしていること、例えば平日と休日ではほぼアクセス数の数に差が大きく現れる、といったことなどです。
実際は機械学習を行わなくてもだいたいの予測(アクセス数)は当たってしまいますけど、自分よりはるかに予測精度の良いモデルを作れたら、自分が起こすべきアクションも明確になると思うので、予測の自動化を図ろうと思いました。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
| Jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| numpy==1.16.4 | OSI Approved (new BSD) |
| jpholiday==0.1.1 | MIT |
| pandas==0.25.0 | BSD |
| matplotlib==3.1.1 | PSF |
| seaborn==0.9.0 | BSD |
それでは実際に行っていきましょう。
ターゲット用の疑似データを生成¶
まずはPython外部ライブラリのnumpyを使ってターゲット用の疑似データを生成していきたいと思います。
機械学習の教師あり学習をさせる際にも、ラベル(答え)となるデータが必要です。
ラベルであるターゲットのデータと、それに伴う日時データがあれば、そこから派生させてサンプルデータを作ることができます。
今回はアクセス数のつもりで疑似データを作るので、各々でデータを持っている方はそちらをお使いください。
numpyをインポートしたら、1から150までの値をランダムに365個生成します。
365個というのは、これから1年間の日付を取得するために必要な数です。
# 実行
import numpy as np
#引数の数字は乱数を固定させるため
np.random.seed(1)
ran_number = np.random.randint(1, 150, 365)
ran_number
# 結果
array([ 38, 141, 73, 138, 134, 80, 145, 130, 72, 135, 26, 21, 102,
147, 140, 143, 51, 69, 97, 87, 142, 138, 8, 64, 62, 23,
58, 2, 129, 61, 9, 142, 116, 122, 31, 72, 132, 50, 58,
4, 25, 44, 77, 27, 53, 81, 110, 116, 42, 16, 65, 26,
112, 136, 27, 105, 23, 10, 127, 24, 126, 101, 58, 84, 137,
33, 11, 24, 144, 88, 26, 93, 75, 47, 66, 114, 78, 4,
129, 7, 53, 3, 77, 8, 78, 76, 77, 44, 21, 31, 37,
104, 8, 46, 58, 97, 14, 11, 24, 125, 82, 136, 122, 149,
141, 95, 61, 83, 116, 98, 131, 104, 99, 11, 97, 83, 72,
55, 16, 134, 146, 21, 119, 23, 142, 115, 98, 85, 11, 97,
62, 57, 97, 26, 143, 142, 117, 44, 135, 144, 25, 138, 54,
70, 102, 22, 41, 78, 114, 48, 46, 88, 145, 46, 117, 67,
47, 129, 64, 76, 36, 34, 131, 84, 49, 55, 33, 56, 32,
29, 75, 137, 110, 100, 33, 9, 85, 51, 80, 65, 109, 25,
114, 21, 45, 16, 143, 20, 87, 136, 54, 111, 35, 101, 33,
148, 25, 95, 134, 80, 64, 114, 88, 43, 146, 69, 65, 146,
39, 71, 49, 45, 106, 1, 87, 17, 20, 10, 113, 52, 112,
139, 124, 69, 15, 22, 125, 132, 89, 55, 72, 15, 144, 54,
115, 45, 38, 77, 13, 121, 60, 126, 44, 115, 39, 92, 113,
70, 74, 53, 90, 28, 44, 2, 83, 128, 95, 85, 31, 104,
65, 99, 53, 132, 71, 141, 40, 84, 62, 14, 24, 123, 96,
54, 138, 89, 110, 83, 107, 140, 106, 37, 113, 145, 116, 107,
36, 82, 3, 94, 110, 47, 81, 28, 73, 29, 131, 142, 122,
37, 19, 64, 47, 105, 113, 102, 3, 99, 29, 27, 59, 128,
145, 38, 12, 7, 97, 143, 101, 88, 124, 33, 111, 92, 123,
129, 98, 147, 28, 53, 103, 122, 51, 47, 8, 17, 140, 15,
105, 31, 137, 141, 146, 11, 29, 134, 82, 134, 122, 43, 87,
58, 57, 79, 88, 118, 139, 49, 20, 141, 78, 17, 5, 119,
69])
lenを使って要素の数を確認
# 実行
len(ran_number)
# 結果
365
次にPython標準ライブラリのdatetimeモジュールを使って日付を取得していきます。
今回は2020年の1月1日から12月31日まで生成していきます。
先ほど生成したran_numberの要素数365個をrangeメソッドを使い0から365回イテレーションします。
すると2020年1月1日から365日分の日付を取得することができます。
# 実行
import datetime
one_year = []
for i in range(len(ran_number)):
one_year.append(datetime.date(2020, 1, 1) + datetime.timedelta(days=i))
one_year
# 結果
[datetime.date(2020, 1, 1),
datetime.date(2020, 1, 2),
datetime.date(2020, 1, 3),
datetime.date(2020, 1, 4),
datetime.date(2020, 1, 5),
datetime.date(2020, 1, 6),
datetime.date(2020, 1, 7),
datetime.date(2020, 1, 8),
datetime.date(2020, 1, 9),
datetime.date(2020, 1, 10),
datetime.date(2020, 1, 11),
...
...
2つのリスト型のデータが作成できたので、Python外部ライブラリのpandasを使ってデータフレームに格納します。
日付用のデータは、データセットのインデックスとして格納します。
# 実行
import pandas as pd
df = pd.DataFrame(ran_number, index=one_year, columns=['Target'])
df.head()
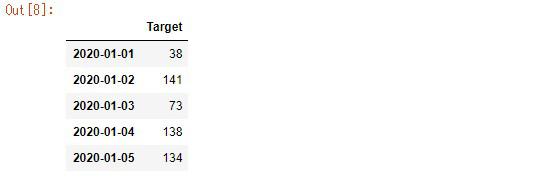
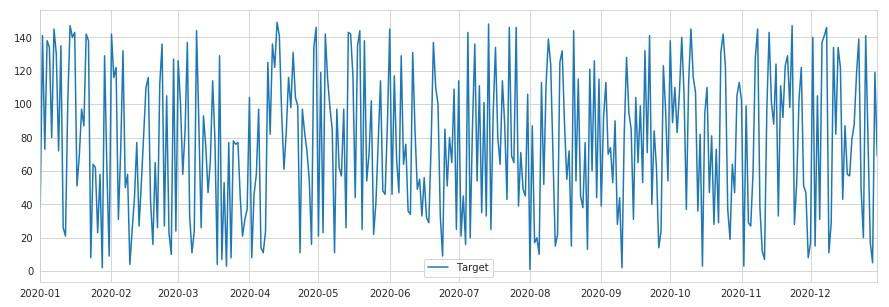
データは全く意味を成さない乱数ですが、グラフを可視化してみます。
外部ライブラリのmatplotlib、そしてグラフを綺麗に描画するseabornを使います。
# 実行
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
df.plot(figsize=(15, 5))
それではpandasの機能を使ってデータフレームを一旦CSVファイルに格納します。
df.to_csv('sample.csv')
各月のサンプルデータを生成¶
月のサンプルデータは、1(月)から12(月)までをカラム名Monthとして作成します。
先ほどCSVファイルに収めたインデックスの日付を利用してデータを生成していきたいと思います。
ではsample.csvを読み込みます。
import pandas as pd
df = pd.read_csv('sample.csv', index_col=0)
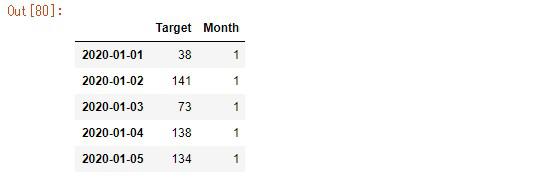
データフレームのインデックスを元にlambda関数を使って、2020-01-01の1番目の要素である01をsplitメソッドで取得します。
取得した月は、データフレームに新しく「Month」としたカラム名に格納していきます。
df['Month'] = df.index.map(lambda x: int(x.split('-')[1]))
格納する際に「AttributeError: 'datetime.date' object has no attribute 'split'」のようなエラーが起こった場合は、splitメソッドが適用できる文字列の要素にする必要があります。
CSVファイルに収める前のインデックスでは、datetimeオブジェクトとなっているのでsplitが適用されません。
# 実行
#CSVファイルに格納する前のデータフレーム
df.index
# 結果
Index([2020-01-01, 2020-01-02, 2020-01-03, 2020-01-04, 2020-01-05, 2020-01-06,
2020-01-07, 2020-01-08, 2020-01-09, 2020-01-10,
...
2020-12-21, 2020-12-22, 2020-12-23, 2020-12-24, 2020-12-25, 2020-12-26,
2020-12-27, 2020-12-28, 2020-12-29, 2020-12-30],
dtype='object', length=365)
一度CSVファイルに格納されたデータのインデックスは文字列として読み込まれます。
# 実行
#CSVファイルを読み込んだ後のデータフレーム
df.index
# 結果
Index(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04', '2020-01-05',
'2020-01-06', '2020-01-07', '2020-01-08', '2020-01-09', '2020-01-10',
...
'2020-12-21', '2020-12-22', '2020-12-23', '2020-12-24', '2020-12-25',
'2020-12-26', '2020-12-27', '2020-12-28', '2020-12-29', '2020-12-30'],
dtype='object', length=365)
では中身を確認してみます。
# 実行
df.head()
後ろから5行。
# 実行
df.tail()
各曜日のサンプルデータを生成¶
曜日のサンプルデータは、Sun(日)、Mon(月)、Tue(火)、Wed(水)、Thu(木)、Fri(金)、Sat(土)として作成します。
datetimeモジュールのstrftimeメソッドを使って、日付データを元に各曜日を生成します。
# 実行
month = []
for i in range(len(df)):
month.append(datetime.date(2020, 1, 1) + datetime.timedelta(days=i))
days = []
for i in month:
days.append(i.strftime('%a'))
days
# 結果
['Wed',
'Thu',
'Fri',
'Sat',
'Sun',
'Mon',
'Tue',
'Wed',
'Thu',
'Fri',
'Sat',
...
...
リストに格納した各曜日のデータをDayというカラム名としてデータフレームに追加します。
# 実行
df['Day'] = days
df.head()
jpholidayを使って祝日のサンプルデータを生成¶
祝日のデータを生成するために便利なツールが、Python外部ライブラリのjpholidayです。
このようなツールがあったおかげで、手作業で1ヵ所ずつデータを挿入する手間が省けたので、非常に有難い機能です(もちろん他のツールも優れものですが)。
公式ドキュメントに従って、一部実装してみたいと思います。
datetimeモジュールと合わせて使うと便利なのでインポートします。
まずは2020年の祝日を取得。
# 実行
import jpholiday
import datetime
jpholiday.year_holidays(2020)
# 結果
[(datetime.date(2020, 1, 1), '元日'),
(datetime.date(2020, 1, 13), '成人の日'),
(datetime.date(2020, 2, 11), '建国記念の日'),
(datetime.date(2020, 2, 23), '天皇誕生日'),
(datetime.date(2020, 2, 24), '天皇誕生日 振替休日'),
(datetime.date(2020, 3, 20), '春分の日'),
(datetime.date(2020, 4, 29), '昭和の日'),
(datetime.date(2020, 5, 3), '憲法記念日'),
(datetime.date(2020, 5, 4), 'みどりの日'),
(datetime.date(2020, 5, 5), 'こどもの日'),
(datetime.date(2020, 5, 6), '憲法記念日 振替休日'),
(datetime.date(2020, 7, 23), '海の日'),
(datetime.date(2020, 7, 24), 'スポーツの日'),
(datetime.date(2020, 8, 10), '山の日'),
(datetime.date(2020, 9, 21), '敬老の日'),
(datetime.date(2020, 9, 22), '秋分の日'),
(datetime.date(2020, 11, 3), '文化の日'),
(datetime.date(2020, 11, 23), '勤労感謝の日')]
独自の休日も追加できるとのことです。
# 実行
class TestHoliday(jpholiday.OriginalHoliday):
def _is_holiday(self, date):
if date == datetime.date(2020, 4, 2):
return True
return False
def _is_holiday_name(self, date):
return 'ZerofromLight運用開始記念日'
jpholiday.year_holidays(2020)
# 結果
[(datetime.date(2020, 1, 1), '元日'),
(datetime.date(2020, 1, 13), '成人の日'),
(datetime.date(2020, 2, 11), '建国記念の日'),
(datetime.date(2020, 2, 23), '天皇誕生日'),
(datetime.date(2020, 2, 24), '天皇誕生日 振替休日'),
(datetime.date(2020, 3, 20), '春分の日'),
(datetime.date(2020, 4, 2), 'ZerofromLight運用開始記念日'), ←ここ
(datetime.date(2020, 4, 29), '昭和の日'),
(datetime.date(2020, 5, 3), '憲法記念日'),
(datetime.date(2020, 5, 4), 'みどりの日'),
(datetime.date(2020, 5, 5), 'こどもの日'),
(datetime.date(2020, 5, 6), '憲法記念日 振替休日'),
(datetime.date(2020, 7, 23), '海の日'),
(datetime.date(2020, 7, 24), 'スポーツの日'),
(datetime.date(2020, 8, 10), '山の日'),
(datetime.date(2020, 9, 21), '敬老の日'),
(datetime.date(2020, 9, 22), '秋分の日'),
(datetime.date(2020, 11, 3), '文化の日'),
(datetime.date(2020, 11, 23), '勤労感謝の日')]
追加した休日を削除します。
# 実行
jpholiday.OriginalHoliday.unregister(TestHoliday)
jpholiday.year_holidays(2020)
# 結果
[(datetime.date(2020, 1, 1), '元日'),
(datetime.date(2020, 1, 13), '成人の日'),
(datetime.date(2020, 2, 11), '建国記念の日'),
(datetime.date(2020, 2, 23), '天皇誕生日'),
(datetime.date(2020, 2, 24), '天皇誕生日 振替休日'),
(datetime.date(2020, 3, 20), '春分の日'),
(datetime.date(2020, 4, 29), '昭和の日'),
(datetime.date(2020, 5, 3), '憲法記念日'),
(datetime.date(2020, 5, 4), 'みどりの日'),
(datetime.date(2020, 5, 5), 'こどもの日'),
(datetime.date(2020, 5, 6), '憲法記念日 振替休日'),
(datetime.date(2020, 7, 23), '海の日'),
(datetime.date(2020, 7, 24), 'スポーツの日'),
(datetime.date(2020, 8, 10), '山の日'),
(datetime.date(2020, 9, 21), '敬老の日'),
(datetime.date(2020, 9, 22), '秋分の日'),
(datetime.date(2020, 11, 3), '文化の日'),
(datetime.date(2020, 11, 23), '勤労感謝の日')]
それでは祝日のデータをイテレーションでリストに格納していきます。
実際データとしては、祝日か祝日でないか?の2通りでいいかと思うので真偽値として格納します。
# 実行
holiday_list = []
for i in range(len(df)):
holiday_list.append(jpholiday.is_holiday(datetime.date(2020, 1, 1)+ datetime.timedelta(days=i)))
holiday_list
# 結果
[True,
False,
False,
False,
False,
False,
False,
False,
False,
False,
False,
False,
True,
...
...
2020年1月1日から祝日か祝日でないかの真偽値が取れているかと思います。
新しくHolidayとしてデータフレームに格納します。
# 実行
df['Holiday'] = holiday_list
df.head()
pandasのreplaceメソッドを使ってサンプルデータのTrueとFalseの名前を別の文字列に置き換えます。
# 実行
df['Holiday'] = df['Holiday'].replace(True, 'public_holiday')
df['Holiday'] = df['Holiday'].replace(False, 'week_days')
df.head()
第何何曜日(週数・週番)のサンプルデータを生成¶
第何何曜日を生成する処理は少し複雑になるので順番に見ていきます。
まずデータフレームからMonth(月)のサンプルデータをリスト型に置き換えます。
# 実行
months = list(df['Month'])
months
# 結果
[1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
この重複したデータを一意にするためにsetメソッドを使います。
今回は1月から12月までなので、小さい値から大きい値に並べられて出力されます。
# 実行
set(months)
# 結果
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}
もしもMonthのサンプルデータが5月から始まっている場合は、sortedメソッドにkeyを指定して並びが崩れないように出力させます。
# 実行
sample_data = [5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12, 12, 1, 1, 2, 2, 3, 3, 4, 4]
#普通に処理を行うと
print(set(sample_data))
#sortedを組み合わせると
print(sorted(set(sample_data), key=sample_data.index))
# 結果
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}
[5, 6, 7, 8, 9, 10, 11, 12, 1, 2, 3, 4]
一意にした要素を変数に格納します。
months_list = set(months)
次に第何何曜日のサンプルデータ用に空リストを準備します。
number_list = []
そして2層構造のイテレーションを実装していきますが、まずは1層目の処理を見てみます。
for month in months_list:
ser_days = df['Day'][df['Month'] == month]
str_day = list(ser_days)[:1]
number = 0
一意のMonth(月)の集合が格納されたmonths_listを最初の要素ずつ渡していきます。
最初の要素である1が渡され(df['Day'][df['Month'] == 1])、ser_daysに1月の曜日データだけがpandasのシリーズとして格納されます。
そのシリーズをリストにして、スライスを使い0番目の要素であるWed(水)をstr_dayに格納します。
numberは第何何曜日であるのかをカウントするための変数です。
上記の処理を1回まわすとごとに、2層目イテレーションが実装されます。
for month in months_list:
ser_days = df['Day'][df['Month'] == month]
str_day = list(ser_days)[:1]
number = 0
#続き(2層目)
for day in ser_days:
if day == ''.join(str_day):
number += 1
number_list.append(number)
print(day, number)
ser_daysであるその月の曜日を1つずつ条件分岐にかけ、その月の最初に来る曜日(''.join(str_day)、ここでは1月の最初の曜日Wed(水)を軸に第1週目~2周目とカウントします。
''.join()は文字列として出力されるので、1周目の最初に引っかかった曜日だけnumberがカウントされ、2周目の同じ曜日が表れるまで数は保持されnumber_listに格納されます。
これを1月分の曜日数(1~31)イテレーションしたら、次の月の2月分が始まります。
number_listをNo./Dayというカラム名にしてデータフレームに追加します。
# 実行
df['No./Day'] = number_list
df.head()
# 実行
df.tail()
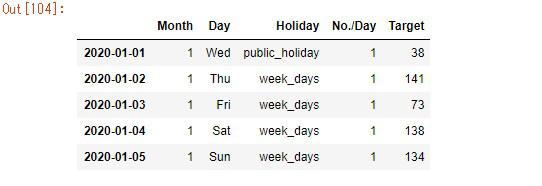
最後にターゲットであるカラムを右側に入れ替えて完成となります。
df = pd.DataFrame(df, columns=['Month', 'Day', 'Holiday', 'No./Day', 'Target'])
各曜日のターゲット合計値を可視化¶
最後に簡単ではありますが、各曜日に絞ったターゲットの合計値をPython外部ライブラリのmatplotlibとseabornで可視化してみたいと思います。
可視化ライブラリをインポートし各曜日の合計値をイテレーションで取り出して表示します。
# 実行
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
x = ['Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat']
y = []
colors = ['b', 'r', 'g', 'm', 'y', 'c', 'black']
for i in x:
y.append(df['Target'][df['Day'] == i].sum())
plt.figure(figsize=(15, 5))
plt.bar(x, y, color=colors, alpha=0.4)
plt.title('Number of accesses for each day of the weeek')
※下図の合計値はnumpyの乱数による疑似データです
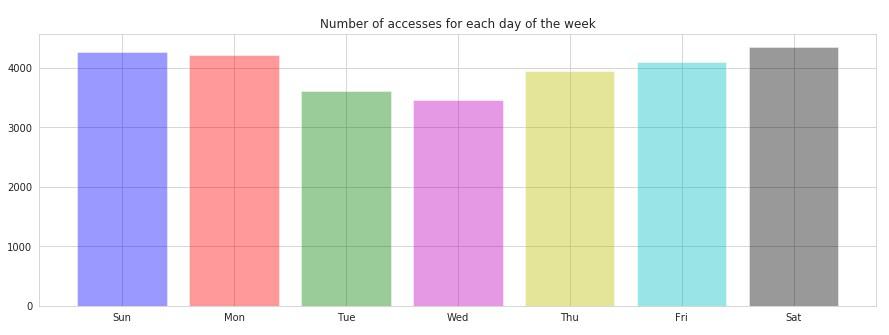
このように、どの曜日にアクセス数が集中しているかなどを分析し、ターゲットに対して必要なデータなのかを確かめることができます。
ここで作成したデータセットはあくまで素材なので、ここから分析などをし、クレンジングやクリーニングを行って機械学習に訓練させていきましょう!
それでは以上となります。
最後までご覧いただきありがとうございました。
