【第5回カリフォルニア住宅価格の予測】Webアプリケーションの作成
投稿日 2020年4月30日 >> 更新日 2024年7月9日
今回は第5回カリフォルニア住宅価格の予測最終回ということで、これまで行ってきたデータの前処理や最良の機械学習モデルを使って、住宅価格の予測システムを作成していきたいと思います。
第3~4回の記事を見て頂ければ、第5回の処理コードはほぼコピペで進めるはずです。
こちらが過去記事です。
- 【第1回カリフォルニア住宅価格の予測】前処理無しで精度を確認
- 【第2回カリフォルニア住宅価格の予測】特徴量エンジニアリング&データクリーニング(データクレンジング)
- 【第3回カリフォルニア住宅価格の予測】最良の機械学習モデルを選び評価を行う
- 【第4回カリフォルニア住宅価格の予測】学習曲線を利用して各モデルの汎化性能を検証
過去記事ではJupyter Notebookを想定して一連の処理を行ってきましたが、この記事からはCUI(cmd・ターミナル)やテキストファイルを使用したアプリケーションの開発環境として進めて行きます。
環境構築の内容は各PC(OS)によって多少異なると思いますが、予測システムの構築はPythonなのでOS関係無く処理を進めることができるかと思います。
ちなみに私の開発環境はWindows Subsystem for Linuxなので、Unix系であれば直感的に真似できると思います。
そして今回の予測システムはWebアプリケーションとして開発を進めて行くので、フレームワークはDjangoを採用します。
こちらが完成予定イメージです
軽量なフレームワークのFlaskというものもありますが、Djangoでは豊富な機能とデータベースの構築が簡単ということもありDjangoフレームワークを使います。
実行環境¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
環境構築¶
まずCUIを開き、開発環境用のディレクトリ(フォルダ)を作成します。
ここではpy_systemというディレクトリとして作成しておきます。
# ディレクトリの作成
User@$ mkdir py_system
# ディレクトリ内の確認
User@$ ls
py_system ... ... ...
cdコマンドでpy_systemのディレクトリに移動したら、その階層でWebアプリケーションを開発するための仮想環境を構築します。
ここでは簡単な説明に留めておくので、宜しければ「【簡単】Python3で仮想環境を構築する(venv)」をご覧ください。
仮想環境の構築には、Python3の標準パッケージとして推奨されているvenvを使用します。
他の仮想環境をやられている方はそちらをご使用ください。
ではcdコマンドで移動したのち、仮想環境下のディレクトリ名をml_systemとして作成します。
User@$ cd py_system
# 仮想環境の作成
User@/py_system$ python3 -m venv ml_system
仮想環境として扱うには、作成されたディレクトリ内のbin/activateファイルを実行し、有効にする必要があります。
User@/py_system$ cd ml_system
# 仮想環境を有効にする
# .コマンドもしくわsourceコマンドを使う
User@/py_system/ml_system$ . bin/activate
# 有効状態
(ml_system)User@/py_system/ml_system$
仮想環境が有効になっている場合は、左側に仮想環境元のディレクトリ名が表示されます。
仮想環境から抜ける場合は、deactivateコマンドを実行します。
# 仮想環境を抜ける場合
(ml_system)User@/py_system/ml_system$ deactivate
User@/py_system/ml_system$
ではもう一度仮想環境を有効にし、開発に必要なパッケージ群をインストールしていきます。
今回インストールするパッケージは以下です。
| 使用ライブラリ | ライセンス |
|---|---|
| Django==3.0.5 | BSD |
| numpy==1.16.4 | OSI Approved (new BSD) |
| pandas==0.25.0 | BSD |
| scikit-learn==0.21.3 | OSI Approved (new BSD) |
第3回・第4回でscikit-learnの機械学習モデルとStandardScalerで訓練セットの計算を求めたスケーラーをpickleファイルに保存しているので、それらを使う為に、そこで使用したscikit-learnのバージョンと揃えておく必要があります。
その他のパッケージは問題無く作動すると思います。
ではインスールして確認してみます。
# パッケージインストール
(ml_system)User@/py_system/ml_system$ pip3 install Django numpy pandas scikit-learn==0.21.3
...
...
# パッケージの確認
(ml_system)User@/py_system/ml_system$ pip3 freeze
asgiref==3.2.7
Django==3.0.5
joblib==0.14.1
numpy==1.18.3
pandas==1.0.3
pkg-resources==0.0.0
python-dateutil==2.8.1
pytz==2019.3
scikit-learn==0.21.3
scipy==1.4.1
six==1.14.0
sqlparse==0.3.1
各パッケージに必要なモジュールも一緒にインストールされています。
これでWebアプリケーションを開発する環境構築は終了です。
次はDjangoフレームワークの初期設定を行っていきます。
Djangoフレームワークの初期設定¶
Djangoで最初に行うことは、プロジェクトを実行して必要なファイル群を作成することです。
プロジェクトを立ち上げるコマンドを入力して、立ち上がったプロジェクトのディレクトリへ移動します。
ここでもプロジェクト名はml_systemとします。
# プロジェクトを立ち上げる
(ml_system)User@/py_system/ml_system$ django-admin startproject ml_system
これでDjangoプロジェクトに必要なファイル群が作成されたので、プロジェクトの階層に移動します。
プロジェクトディレクトリには幾つかファイルやディレクトリが作成されているのが分かります。
# プロジェクトへ移動
(ml_system)User@/py_system/ml_system$ cd ml_system
# ディレクトリ内の確認
(ml_system)User@/py_system/ml_system/ml_system$ ls
db.sqlite3 manage.py ml_system
現在いるディレクトリ内に、manage.pyファイルが確認できたら、さっそくDjangoアプリケーションを起動してみます。
# アプリを起動
(ml_system)User@/py_system/ml_system/ml_system$ python3 manage.py runserver
System check identified no issues (0 silenced).
April 28, 2020 - 18:54:07
Django version 3.0.5, using settings 'ml_system.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
開発サーバーが起動されたので、お使いのブラウザを開き「127.0.0.1:8000/」へアクセスします。
すると以下のような一覧画面が表示されます。
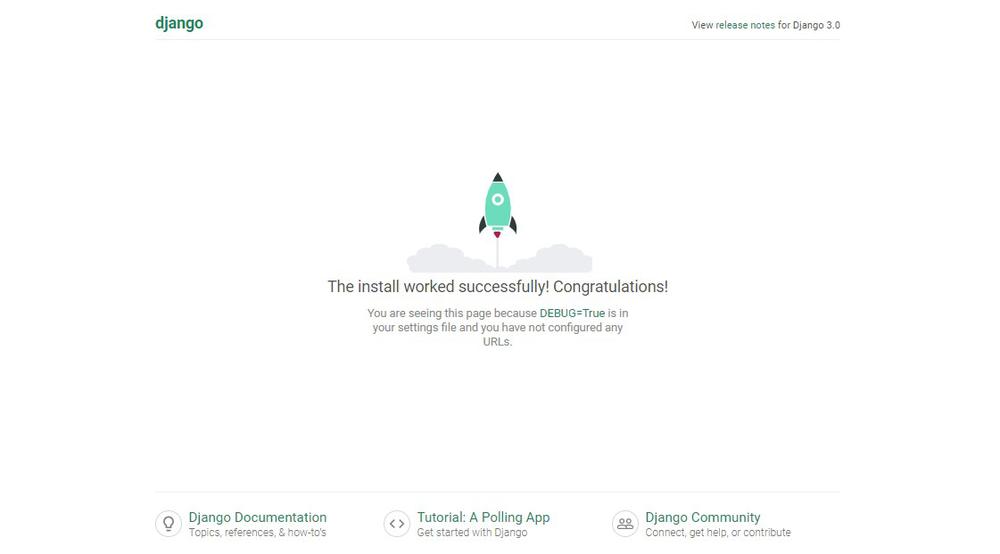
今の状態では英語設定となっているので、設定ファイルを開いて日本語設定にしていきます。
設定ファイルは、プロジェクトディレクトリ内にある、ml_systemディレクトリのsettings.pyです。
settings.pyファイル内の一番下の方にあるLANGUAGE_CODEとTIME_ZONEを以下のように変更します。
# ml_system/ml_system/settings.py
# Internationalization
# https://docs.djangoproject.com/en/3.0/topics/i18n/
# 変更
LANGUAGE_CODE = 'ja'
# 変更
TIME_ZONE = 'Asia/Tokyo'
USE_I18N = True
USE_L10N = True
USE_TZ = True
設定が完了したら、もう一度開発サーバーを起動して確認してみましょう。
これで最初の設定は完了しました。
アプリケーションを開発するための基本構成は整ったので、次は予測システムのアプリを作成していきたいと思います。
予測システムのCaliforniaアプリケーションの作成¶
ここからは仮想環境である前提のもと、manage.pyファイルのあるディレクトリを基本ディレクトリとして進めて行きます。
ml_system/
|--ml_system/
|--settings.py
|--urls.py
|--db.sqlite3
|--manage.py ←ここ
新規にアプリケーションを作成するには、以下のようにコマンドを実行します。
アプリ名は「california」とします(お好きな名前で)。
/ml_system$ python3 manage.py startapp california
するとcaliforniaのディレクトリが作成され、その中身はアプリケーション開発に必要な構成要素(ファイル)が出来上がります。
ml_system/
|--california
|--__pycache__
|--migrations
|--__init__.py
|--admin.py
|--apps.py
|--models.py
|--test.py
|--views.py
作成したcaliforniaアプリを設定ファイルのsettings.pyに定義します。
INSTALLED_APPSのリスト内に追記します。
# ml_system/ml_system/settings.py
# Application definition
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
# アプリケーション
'california',
]
そして同じ階層のurls.pyを編集します。
# ml_system/ml_system/urls.py
"""ml_system URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/3.0/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
Including another URLconf
1. Import the include() function: from django.urls import include, path
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
"""
from django.contrib import admin
from django.urls import path, include # 追加
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('california.urls')), # 追記
]
これで開発サーバー起動時、californiaアプリケーションが立ち上がるようになりました。
次に、アプリケーションが立ち上がった時の最初のトップ画面を作成していきます。
トップ画面の作成¶
californiaアプリケーションが立ち上がるように設定しましたが、立ち上がった際に表示されるトップ画面の架け橋となる部分を構成していきます。
californiaディレクトリに移動し、新規ファイルとして、urls.pyを作成します。中身は以下のように記述します。
# ml_system/california/urls.py
from django.urls import path
from . import views
app_name = 'california'
urlpatterns = [
path('', views.index, name='index'), # トップ画面
]
pahtの第1引数ではトップ階層のURL名で、第2引数のviewsではviews.pyからindexという関数の処理を渡しています。
indexという名前は任意で、これからその関数を定義していきます。
次にviews.pyを編集します。
views.pyから、HTMLへの動的な処理を実行させます。
# ml_system/california/views.py
from django.shortcuts import render
def index(request):
"""
トップ画面
"""
return render(request, 'california/index.html')
最初のトップ画面として、render()の第2引数に指定されているテンプレートファイルを表示します。
Djangoではテンプレートファイル用に、「templates」というディレクトリを新たに作成する必要があります。
templatesディレクトリ内には「california」というディレクトリを作成し、その配下にテンプレートファイル群を作成していきます。
ml_system/
|--california
|--__pycache__
|--migrations
|--templates ←新規作成
|--california
|--index.html
|--__init__.py
|--admin.py
|--apps.py
|--models.py
|--test.py
|--urls.py
|--views.py
index.htmlを編集します。
<!-- ml_system/california/templates/california/index.html -->
<!doctype html>
<html>
<head>
<title>カリフォルニア住宅価格の予測システム</title>
</head>
<body>
<center>
<h2>カリフォルニア住宅価格の予測システム</h2>
</center>
</body>
</html>
では開発サーバーを再起動してみましょう。
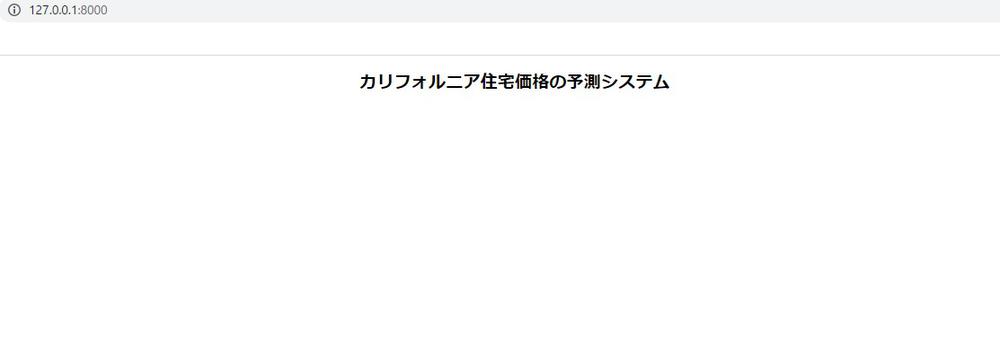
入力フォームの作成¶
次に、住宅価格の予測に必要な情報を入力するためのフォーム画面を作成していきます。
先ほどと同様に、urls.pyにてURLパターンを追記して、それをテンプレートへ渡すための関数をviews.pyに追記します。
まずがurls.pyから編集します。
# ml_system/california/urls.py
.....
.....
urlpatterns = [
path('', views.index, name='index'), # トップ画面
path('predictions', views.predictions, name='predictions'), # フォーム画面
]
次にviews.pyを編集します。
index関数の下に新しく関数を定義していきます。
# ml_system/california/views.py
from django.shortcuts import render
....
def predictions(request):
"""
入力フォーム内の処理
"""
return render(request, 'california/predictions.html')
ここで記述したのと同じpredictions.htmlファイルをtemplatesディレクトリ内に作成していきます。
<!-- ml_system/california/templates/california/predictions.html -->
<center>
<h2>入力画面</h2>
<hr>
<br>
<a href="{% url 'california:index' %}">
<p>戻る</p>
</a>
</center>
aリング内の{% url 'california:index' %}という記述は、テンプレートタグと言って、ここではURLとして機能を果たします。
テンプレートファイル内に{% %}を記述することで、Djangoプロジェクト内で作成していった要素を取り出すことができます。
例えば{% for .. in ... %}でイテレーションしたり、{% if ... %}と条件分岐させたりできます。また後ほど見ていきます。
ではフォーム画面に移動するための記述を、index.htmlに記述します。
<!-- ml_system/california/templates/california/index.html -->
<!doctype html>
<html>
<head>
<title>カリフォルニア住宅価格の予測システム</title>
</head>
<body>
<center>
<h2>カリフォルニア住宅価格の予測システム</h2>
<!-- ここから追記 -->
<hr>
<br>
<a href="{% url 'california:predictions' %}">
<h2>入力画面</h2>
</a>
<!-- ここまで追記 -->
</center>
</body>
</html>
トップ画面からのaリンクには、フォーム画面(予測画面)に遷移するためのテンプレートタグを記述しています。
ではサーバーを再起動させ試行してみます。

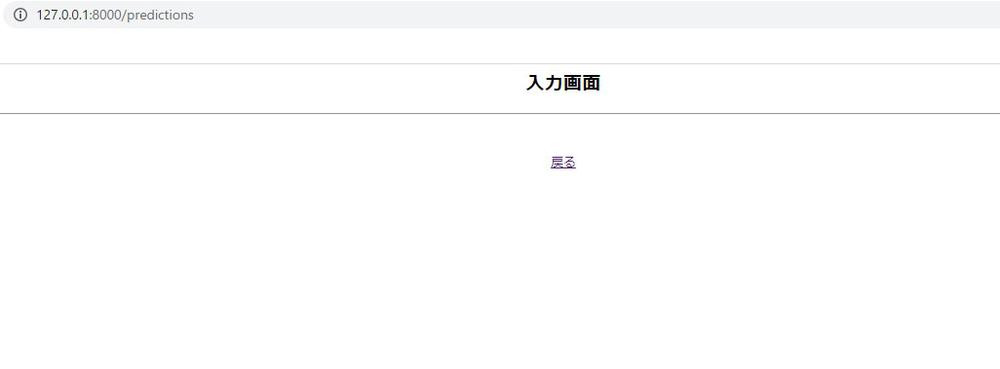
上手く遷移されたら、入力画面内に住宅価格の予測に必要な情報を入力するためのフォームを作成していきます。
DjangoにはFormクラスが用意されており、それを継承することによって簡単に入力フォームを作成することができます。
ではcaliforniaディレクトリ内に、forms.pyという新規ファイルを作成して以下のように記述します。
# ml_system/california/forms.py
from django import forms
class InputForm(forms.Form):
medinc = forms.FloatField(label='MedInc')
house_age = forms.FloatField(label='House_Age')
ave_rooms = forms.FloatField(label='AveRooms')
ave_bedrms = forms.FloatField(label='AveBedrms')
population = forms.FloatField(label='Population')
ave_occup = forms.FloatField(label='AveOccup')
latitude = forms.FloatField(label='Latitude')
longitude = forms.FloatField(label='Longitude')
これでforms.pyをviews.pyで呼び出し、テンプレートタグやテンプレートフィルタを使うだけで準備は完了します。
ではviews.pyのpredictions関数に、継承したFormクラスを渡します。
# ml_system/california/views.py
from django.shortcuts import render
# 入力フォームを出力するファイルのインポート
from .forms import InputForm
...
def predictions(request):
"""
入力フォーム内の処理
"""
form = InputForm()
return render(request, 'california/predictions.html', {'form': form})
forms.pyで記述したフォームオブジェクトを変数に格納し、render関数の第3引数に辞書型として要素をテンプレートタグやフィルタで呼び出せるようになります。
辞書内の'form'というキー名は任意なので、分かりやすい名前で良いでしょう。
こうすることによってpredictions.html内でformの要素を表示できるようになります。
ではpredictions.htmlを編集します。
<!-- ml_system/california/templates/california/predictions.html -->
<center>
<h2>入力画面</h2>
<hr>
<br>
<a href="{% url 'california:index' %}">
<p>戻る</p>
</a>
<!-- ここから追記 -->
<br>
<form action="{% url 'california:predictions' %}" method="post">
{% csrf_token %}
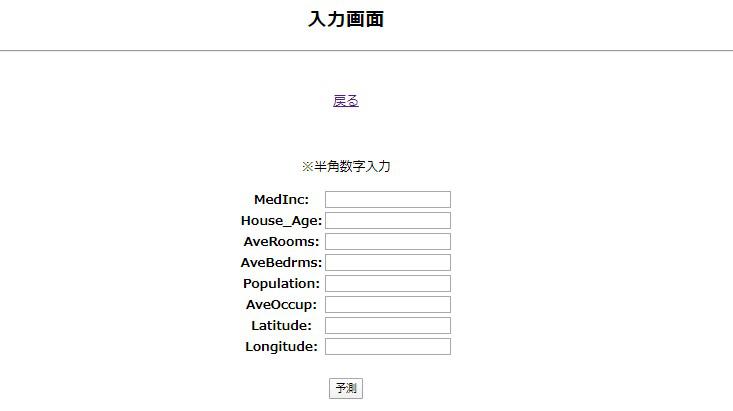
<p>※半角数字入力</p>
<table>
{{ form.as_table }}
</table><br>
<input type="submit" value="予測">
</form>
<!-- ここまで追記 -->
</center>
{% csrf_token %}はクロスサイトリクエストフォージェリ対策として、Webアプリケーションをフォーム入力の攻撃から守るための記述です。
Djangoの入力フォームで{% csrf_token %}の記述がされないとエラーとなります。
入力フォームを表示させる記述は、{{ form.as_table }}というテンプレートフィルタです。
DjangoのFormクラスを継承すると、複数の属性を使い簡単に入力フォームを呼び出すことができます。
ここまで出来たら、サーバーを再起動してみます。
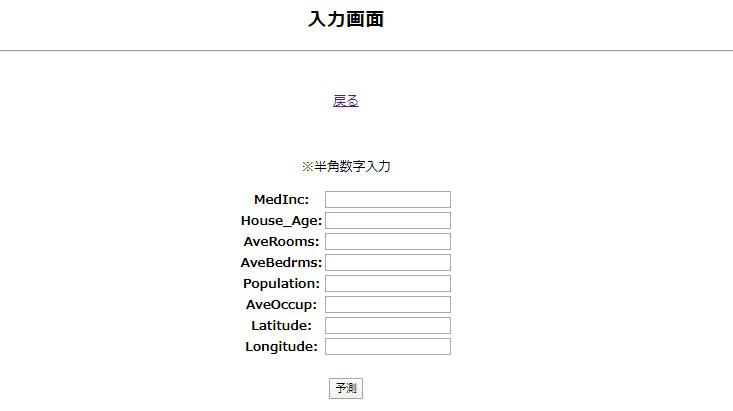
このままでは入力しても何も返さないので、試しに入力した情報をそのまま返す処理を記述してみます。
views.pyを編集します。
# ml_system/california/views.py
def predictions(request):
"""
入力フォーム内の処理
"""
if request.method == 'POST':
# inputタグが押された時
form = InputForm(request.POST)
# 入力された情報を検証し、内容を取り出す
if form.is_valid():
medinc = form.cleaned_data['medinc']
house_age = form.cleaned_data['house_age']
ave_rooms = form.cleaned_data['ave_rooms']
ave_bedrms = form.cleaned_data['ave_bedrms']
population = form.cleaned_data['population']
ave_occup = form.cleaned_data['ave_occup']
latitude = form.cleaned_data['latitude']
longitude = form.cleaned_data['longitude']
# 各要素をリスト形式にまとめる
prediction = [medinc, house_age, ave_rooms, ave_bedrms,
population, ave_occup, latitude, longitude]
# 各要素を'pred_output'キーとして記述
return render(request, 'california/predictions.html', {'form': form,
'pred_output': prediction})
else:
form = InputForm()
return render(request, 'california/predictions.html', {'form': form})
入力情報が送信されるとform.is_valid()により検証を行い、それにクリアされればその後の処理が実行されます。
各情報をpredictionリストに格納し、それを'pred_output'キーに与えています。
ではテンプレートファイルのpredictions.html内でpred_outputキーを記述し表示させます。
<!-- ml_system/california/templates/california/predictions.html -->
<center>
<h2>入力画面</h2>
<hr>
<br>
<a href="{% url 'california:index' %}">
<p>戻る</p>
</a>
<br>
<form action="{% url 'california:predictions' %}" method="post">
{% csrf_token %}
<p>※半角数字入力</p>
<table>
{{ form.as_table }}
</table><br>
<input type="submit" value="予測">
</form>
<!-- ここから記述 -->
{% if pred_output %}
<a href="{% url 'california:predictions' %}">
<p>もう一度やり直す</p>
</a>
<br>
<h1 style="font-size: 100px;">{{ pred_output }}</h1>
{% endif %}
<!-- ここまで記述 -->
</center>
テンプレートタグの{% if pred_output %}では、情報が送信された際に処理される記述です。
処理内容はh1タグにテンプレートフィルタでpred_outputキーを渡し要素を出力させます。
サーバーを再起動し試行してみます。
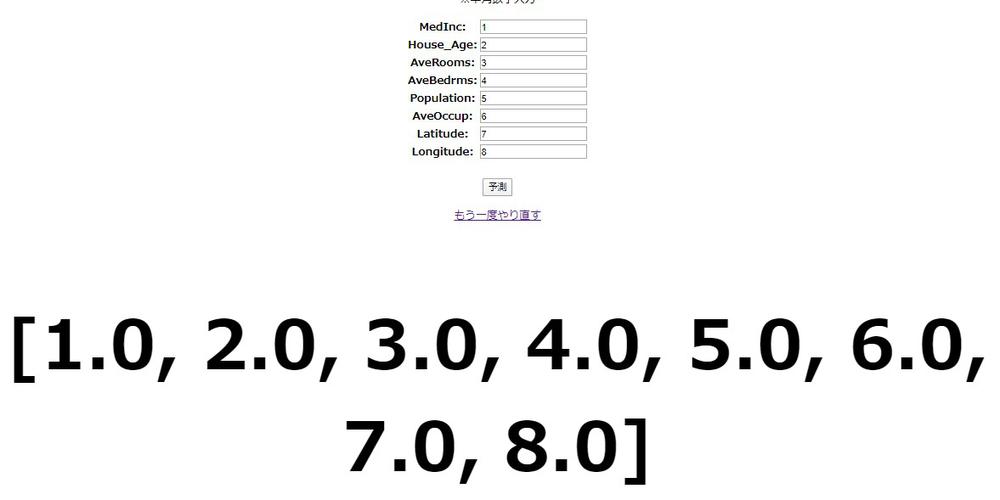
入力情報を予測¶
ここからはいよいよ、pickleファイルに保存した最良の機械学習モデルを使用して入力された情報を予測する処理を作成していきます。
picileファイルに保存してある、モデルと標準化に使うスケーラーをcaliforniaディレクトリ内に移動しておきます。
ml_system/
|--california
|--__pycache__
|--migrations
|--templates
|--__init__.py
|--admin.py
|--apps.py
|--best_model.pickle ←ここ
|--models.py
|--scaler.pickle ←ここ
|--test.py
|--urls.py
|--views.py
pickleファイルが配置されたら、前処理用のファイルと予測用のファイルを新規に作成していきます。
前処理用のファイルは、conversion.pyとして作成します。
# ml_system/california/conversion.py
import numpy as np
import pandas as pd
import pickle
from sklearn.datasets import fetch_california_housing
# スケーラーを読み込む
with open('california/scaler.pickle', 'rb') as f:
scaler = pickle.load(f)
def round_number(df):
"""
指定された属性の値を四捨五入し整数に置き換える
"""
ave_columns = ['AveRooms', 'AveBedrms', 'AveOccup']
for col in ave_columns:
df[col] = np.round(df[col])
return df
def category(df):
"""
その区域の人口は、少ない(few)か、普通(usually)か、多い(many)か。
大体のの区域では600人から3000人ということから、この範囲を指標とする。
"""
if df < 600:
return 'few'
elif df > 3000:
return 'many'
else:
return 'usually'
""" 上の関数をまとめたカスタム変換器"""
def custom_conversion(x):
# カリフォルニア住宅価格のデータセットを読み込む
housing = fetch_california_housing()
df_housing = pd.DataFrame(housing.data, columns=housing.feature_names)
df = pd.DataFrame([x], columns=df_housing.columns)
m = len(df)
# カリフォルニア住宅価格のデータセットに、入力された情報を結合する
df = pd.concat([df_housing, df])
# ここからデータセットをまとめて処理
df = round_number(df)
# 平均部屋数に対して平均寝室数を比較する
df['Bedrms_per_Rooms'] = df['AveBedrms'] / df['AveRooms']
df['Population_Feature'] = df['Population'].apply(category)
# カテゴリー属性をダミー変数化する
feature_dummies = pd.get_dummies(df['Population_Feature'], drop_first=True)
df = pd.concat([df, feature_dummies], axis=1)
X = df.drop(['AveBedrms', 'Population_Feature'], axis=1)
# 下からm個のデータだけ取り出す
X = X[-m:]
X = scaler.transform(X)
return X
上記のコードは、第2回カリフォルニア住宅価格の予測で作成したカスタム変換器を少し変更したものです。
最後のcustom_conversion()関数でわざわざカリフォルニア住宅価格のデータセットを読み込んでいるのを不思議に感じたと思います。
受け取るデータは1つだけなので、ダミー変数化しようとしても属性値が足りないので、吐き出される説明変数の数が足りなくなります。
従って最良のモデルが訓練を行った説明変数の数を合わせるためにカリフォルニアのデータセットを結合して、ブロック内の人口が多いか・少ないか・普通かをダミー変数として渡せるように処理を行っています。
詳しくは第2回カリフォルニア住宅価格の予測をご参照ください。
次に前処理が行われた後の予測処理です。
新しくml_model.pyという新規ファイルを作成して処理内容を定義します。
# ml_system/california/ml_model.py
import pickle
import numpy as np
with open('california/best_model.pickle', 'rb') as f:
model = pickle.load(f)
def predict(x):
y_pred = model.predict(x)
# 結果表示用
y_pred_1 = y_pred[0] * 10
y_pred_1 = np.round(y_pred_1, 1)
y_pred_1 = str(y_pred_1)
ten_thousand = y_pred_1.split('.')[0]
thousand = y_pred_1.split('.')[1]
# 保存用
save_prediction = np.round(y_pred[0], 3)
return ten_thousand, thousand, save_prediction
predict関数の処理内容は、テンプレートファイルに与える用としてten_thousand・thousand、保存用としてave_predictionという3つの異なる要素を戻り値として与えています。
モデルから直接予測された要素はドル表記となっていないので、10倍して小数点を一桁ずらし、小数点までを万単位、小数点以下を千単位として分割しています。
そして保存用の要素は、後ほどデータベースに入力された情報と予測結果を保存するために別で用意しておきました。
では新規に作成したファイルをviews.pyで使えるように編集します。
# ml_system/california/views.py
...
...
# 前処理用のファイルをインポート
from .conversion import custom_conversion
# 予測用ファイルのインポート
from .ml_model import predict
....
def predictions(request):
"""
入力フォーム内の処理
"""
if request.method == 'POST':
form = InputForm(request.POST)
if form.is_valid():
medinc = form.cleaned_data['medinc']
house_age = form.cleaned_data['house_age']
ave_rooms = form.cleaned_data['ave_rooms']
ave_bedrms = form.cleaned_data['ave_bedrms']
population = form.cleaned_data['population']
ave_occup = form.cleaned_data['ave_occup']
latitude = form.cleaned_data['latitude']
longitude = form.cleaned_data['longitude']
""" ここから追記 """
# 変数を先ほどのpredictionからelementに変更
element = [medinc, house_age, ave_rooms, ave_bedrms,
population, ave_occup, latitude, longitude]
# 入力されたデータの前処理
df = custom_conversion(element)
# 前処理されたデータを万単位、千単位、保存用の予測値として返す
ten_thousand, thousand, save_prediction = predict(df)
# テンプレートアフィルに渡す予測結果
prediction = '予測結果:' + ten_thousand + '万' + thousand + '千ドル'
""" ここまで追記 """
return render(request, 'california/predictions.html', {'form': form,
'pred_output': prediction})
else:
form = InputForm()
return render(request, 'california/predictions.html', {'form': form})
これで予測が行われるはずです。
サーバーを再起動させ、入力フォームに値を入れ予測してみましょう。
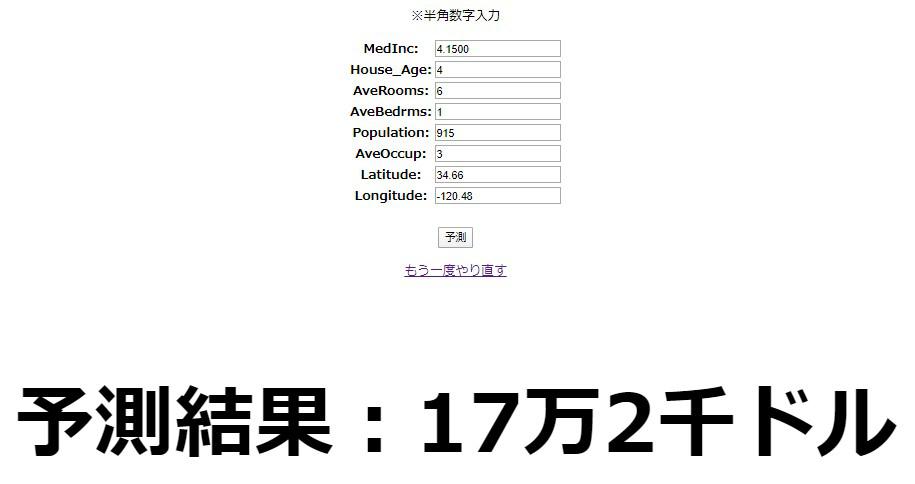
色々な値を予測させてみて、予測結果がしっかり変化していればひとまず成功です。
次に、入力された値(情報)と予測結果をデータベースに保存していく処理を書いていきます。
入力情報と予測結果を保存¶
Djangoでデータベースを構築するには、californiaディレクトリ内にあるmodels.pyファイルで、テーブルやカラムを定義していきます。
Djangoではテーブルの事をモデルと呼び、カラムをフィールドと呼びます。
そしてModelクラスが用意されているので、それを継承してFormクラスで定義したようにモデルを作成していきます。
# ml_system/california/models.py
from django.db import models
""" モデル """
class California_Data(models.Model):
"""
各フィールド
"""
medinc = models.FloatField('MedInc')
house_age = models.FloatField('House_Age')
ave_rooms = models.FloatField('AveRooms')
ave_bedrms = models.FloatField('AveBedrms')
population = models.FloatField('Population')
ave_occup = models.FloatField('AveOccup')
latitude = models.FloatField('Latitude')
longitude = models.FloatField('Longitude')
prediction = models.FloatField('Prediction')
created_at = models.DateField(auto_now_add=True)
# 管理サイトでの表記を明示
def \_\_str__(self):
return str(self.created_at)
モデルを定義したら、データベースに適用させます。
CUIに戻って、manage.pyファイルのあるml_systemディレクトリで以下のコマンドを実行します。
/ml_system$ python3 manage.py migrate
....
移行ファイルの作成
/ml_system$ python3 manage.py makemigrations
....
モデルを編集した際は、必ず上記のコマンドを実行します。
移行ファイルはcaliforniaディレクトリ内にあるmigrationsディレクトリ内に作成されます。
データベースの構築はこれで済んだので、入力情報と予測結果を保存するための処理を書いていきます。
views.pyを編集します。
# ml_system/california/views.py
...
...
...
...
# データベースに紐づいているファイルをインポート
from .models import California_Data
....
def predictions(request):
"""
入力フォーム内の処理
"""
if request.method == 'POST':
form = InputForm(request.POST)
if form.is_valid():
medinc = form.cleaned_data['medinc']
house_age = form.cleaned_data['house_age']
ave_rooms = form.cleaned_data['ave_rooms']
ave_bedrms = form.cleaned_data['ave_bedrms']
population = form.cleaned_data['population']
ave_occup = form.cleaned_data['ave_occup']
latitude = form.cleaned_data['latitude']
longitude = form.cleaned_data['longitude']
# 変数を先ほどのpredictionからelementに変更
element = [medinc, house_age, ave_rooms, ave_bedrms,
population, ave_occup, latitude, longitude]
# 入力されたデータの前処理
df = custom_conversion(element)
# 前処理されたデータを万単位、千単位、保存用の予測値として返す
ten_thousand, thousand, save_prediction = predict(df)
# テンプレートアフィルに渡す予測結果
prediction = '予測結果:' + ten_thousand + '万' + thousand + '千ドル'
""" ここから追記 """
# Modelクラスの各フィールドに要素を与える
california_save = California_Data(
medinc=medinc,
house_age=house_age,
ave_rooms=ave_rooms,
ave_bedrms=ave_bedrms,
population=population,
ave_occup=ave_occup,
latitude=latitude,
longitude=longitude,
prediction=save_prediction, # 保存用の予測値を与える
)
# 格納された要素を保存
california_save.save()
""" ここまで追記 """
return render(request, 'california/predictions.html', {'form': form,
'pred_output': prediction})
else:
form = InputForm()
return render(request, 'california/predictions.html', {'form': form})
入力ファームに値を入れ、予測が行われると勝手に保存される仕組みです。
サーバーを再起動させ、さっそく適当な値を入力して予測してみましょう。
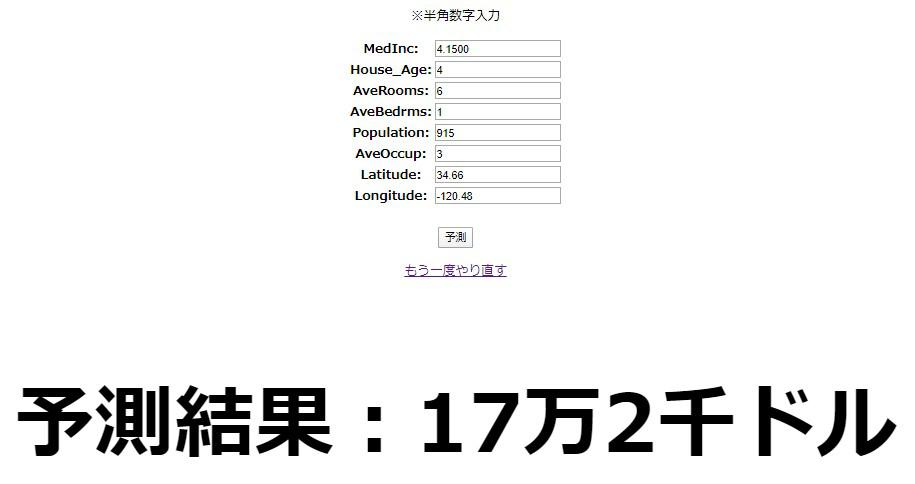
問題無く予測結果が表示されれば、正常に保存されているはずです。
保存されたデータを確認するには、管理サイトへアクセスします。
Djangoでは管理サイトが用意されおり、簡単な設定で利用することができます。
californiaディレクトリ内にあるadmin.pyを編集します。
#ml_system/california/admin.py
from django.contrib import admin
# Modelクラスをインポート
from .models import California_Data
# 追記
admin.site.register(California_Data)
管理者として、アカウントを作成します。
CUIに戻り、manage.pyファイルのあるディレクトリで以下のコマンドを実行します。
/ml_system$ python3 manage.py createsuperuser
ユーザー名:
アドレス:
パスワード:
パスワード確認:
ユーザー名、アドレス、パスワードを設定します。
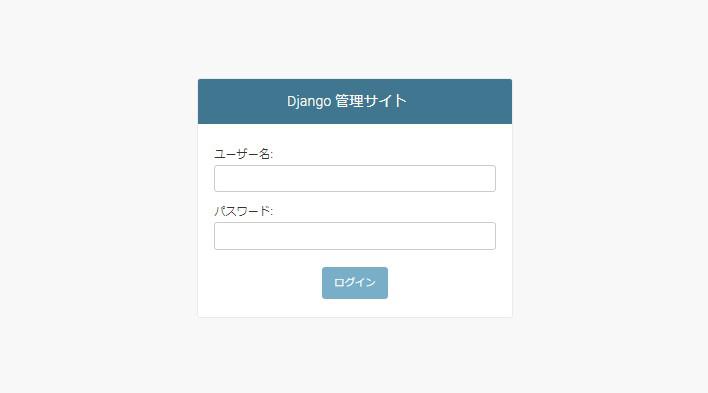
設定が終わったら再起動し、ブラウザの検索欄でドメイン/admin(127.0.0.1:8000/admin)へアクセスします。
すると下図の画面が表示されるので、ユーザー名とパスワードを記入します。
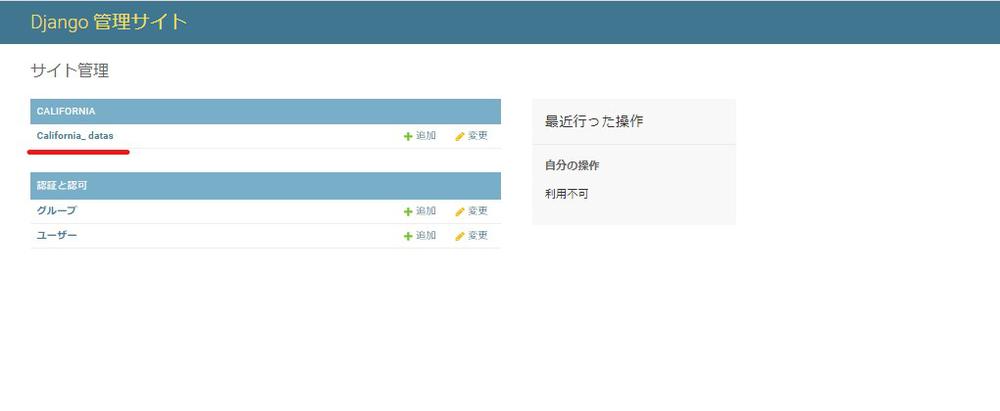
管理画面に入ることができたら、models.pyで定義したCalifornia_Dataモデルが表示されているかと思います。
詳細を開いていくと保存されたデータを確認することができます。
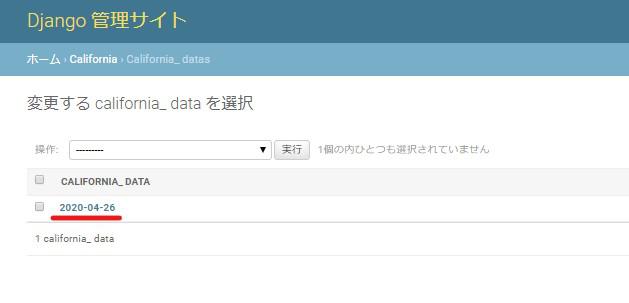
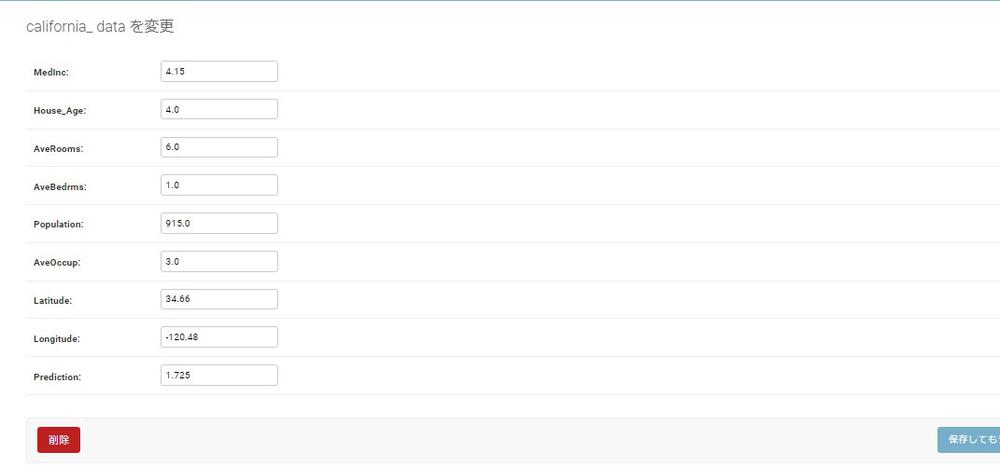
保存されているデータを確認することが出来ましたが、管理者しか見ることができません。
わざわざ管理画面へ移動しデータを確認するのは不便なので、履歴画面のページを新しく作成していきたいと思います。
履歴画面の作成¶
californaディレクトリ内のurls.pyファイルに、historyというURLパターンを追加します。
# ml_system/california/urls.py
from django.urls import path
from . import views
app_name = 'california'
urlpatterns = [
path('', views.index, name='index'), # トップ画面
path('predictions', views.predictions, name='predictions'), # 予測画面
path('history', views.history, name='history'), # 履歴
]
次にviews.pyで、履歴画面用の関数を新たに記述します。
# ml_system/california/views.py
from django.shortcuts import render
...
...
...
def history(request):
"""
履歴画面
"""
# California_Dataモデル内の全ての要素を取り出す
california_history = California_Data.objects.all()
return render(request, 'california/history.html', {'historys': california_history})
次にhistory.htmlというテンプレートファイルを新規に作成します。
<!-- ml_system/california/templates/california/history.html -->
<center>
<h2>履歴画面</h2>
<hr>
<br>
<a href="{% url 'california:index' %}">
<p>戻る</p>
</a>
<br>
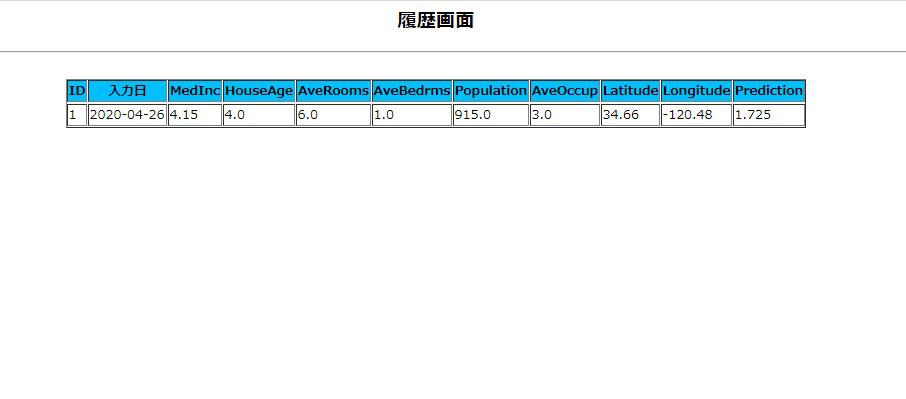
{% for history in historys %}
{{ history.id }}
{{ history }}
{{ history.medinc }}
{{ history.house_age }}
{{ history.ave_rooms }}
{{ history.ave_bedrms }}
{{ history.population }}
{{ history.ave_occup }}
{{ history.latitude }}
{{ history.longitude }}
{{ history.prediction }}
{% endfor %}
</center>
テンプレートタグ内で、California_Dataモデルの各フィールドから要素を取り出します。
ではトップ画面のindex.htmlに履歴画面のリンクを記述しましょう。
<!-- ml_system/california/templates/california/index.html -->
<!doctype html>
<html>
<head>
<title>カリフォルニア住宅価格の予測システム</title>
</head>
<body>
<center>
<h2>カリフォルニア住宅価格の予測システム</h2>
<hr>
<br>
<a href="{% url 'california:predictions' %}">
<h2>入力画面</h2>
</a>
<!-- ここから追記 -->
<br>
<a href="{% url 'california:history' %}">
<h2>履歴画面</h2>
</a>
<!-- ここまで追記 -->
</center>
</body>
</html>
サーバーを再起動し、確認してみます。

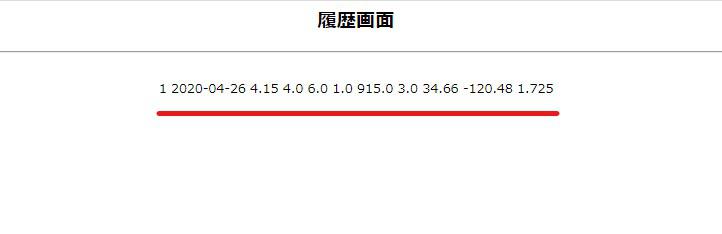
問題無く要素を表示出来ていたら成功です。
あとはtableタグを使い見栄えを整えていきます。
もう一度history.htmlを編集します。
<!-- ml_system/california/templates/california/history.html -->
<center>
<h2>履歴画面</h2>
<hr>
<br>
<a href="{% url 'california:index' %}">
<p>戻る</p>
</a>
<br>
<!-- ここから編集 -->
{% if historys %}
<table border="1">
<tr bgcolor="deepskyblue">
<th>ID</td>
<th>入力日</th>
<th>MedInc</th>
<th>HouseAge</th>
<th>AveRooms</th>
<th>AveBedrms</th>
<th>Population</th>
<th>AveOccup</th>
<th>Latitude</th>
<th>Longitude</th>
<th>Prediction</th>
</tr>
{% for history in historys %}
<tr>
<td>{{ history.id }}</td>
<td>{{ history }}</td>
<td>{{ history.medinc }}</td>
<td>{{ history.house_age }}</td>
<td>{{ history.ave_rooms }}</td>
<td>{{ history.ave_bedrms }}</td>
<td>{{ history.population }}</td>
<td>{{ history.ave_occup }}</td>
<td>{{ history.latitude }}</td>
<td>{{ history.longitude }}</td>
<td>{{ history.prediction }}</td>
</tr>
{% endfor %}
</table>
{% else %}
<h2>現在履歴はありません</h2>
{% endif %}
<!-- ここまで編集 -->
</center>
{% if historys %}での処理は、保存データが存在していればデータを表示し、データが存在していなければ「現在履歴はありません」と表示されます。
では確認してみます。
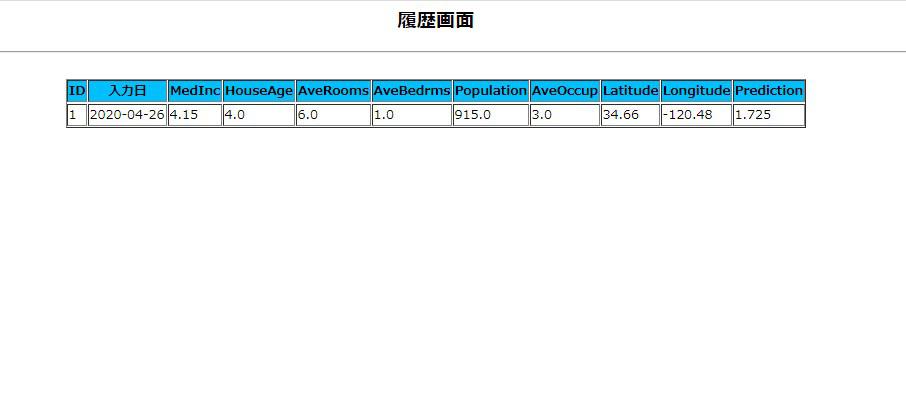
最後にもう一度適当な値で予測をして、履歴データが追加されるか試してみます。
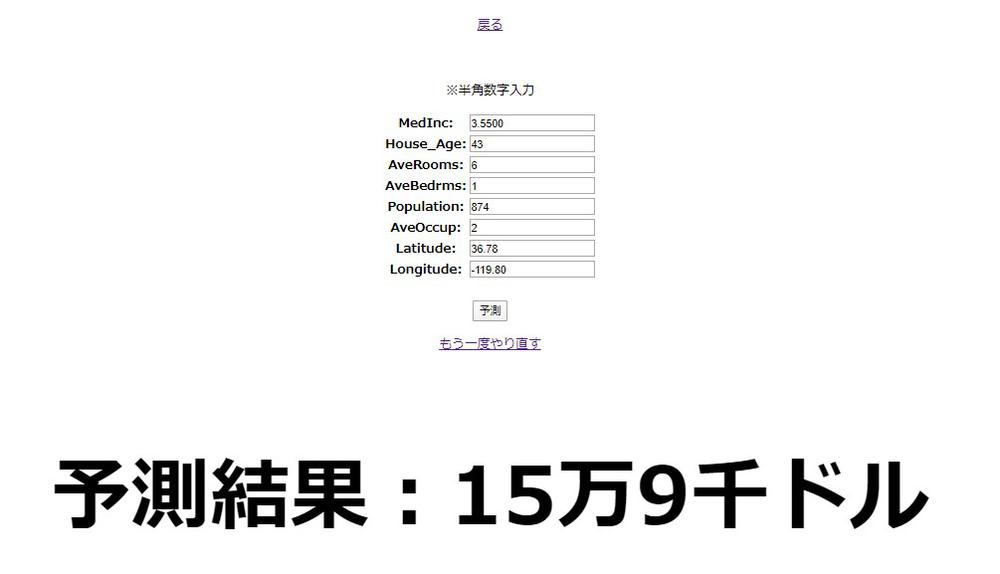
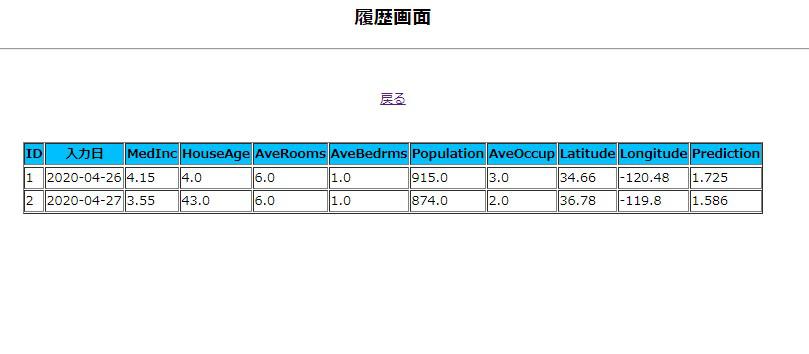
上手く追加されていれば完成です。
因みにデータを削除すると

今回は予測システムの実装をメインに行ってきました。
説明も不十分でコードも分かり難かった部分も多々あったかと思いますが、少しでも参考になっていただければ幸いです。
それでは以上となります。
最後までご覧いただきありがとうございました。
