【scikit-learn】SimpleImputerで欠損値を補完し、統計情報を保存する
投稿日 2020年5月10日 >> 更新日 2024年7月9日
今回は機械学習ライブラリのscikit-learnから、SimpleImputerという機能を使用してデータ内の欠損値や値を置き換えて、置き換える為に計算された統計値をいつでも使用できるように保管していきたいと思います。
もちろんデータ分析ライブラリのPandasを使って欠損値の除外や置き換えは簡単に行うことができますが、置き換えた値を保管して本番システムでも使いたい場合があるかと思います。
例えばある属性の欠損値に、その属性内の平均値に置き換えた場合、同じことを本番システムに流れてくるデータにも適用されたいと思います。
その未知のデータに欠損値が無ければ問題は無いですが、欠損値が含まれていて置き換えを行おうとしても、そもそも流れてくるデータは1つ2つだと思うので、平均値を割り出せなくなってしまいます。
予め求めた平均値をハードコードしその都度置き換えるか、訓練用のデータセットを引っ張ってきて平均値をその都度求め直して置き換えるか、色々な方法があります。
しかしそのような面倒を解消してくれるのがこれから実装するSimpleImputerです。
置き換えたい値を平均値といいましたが、それ以外にも中央値・最頻値・任意の値に置き換えることが可能な優れものなので是非とも試してみましょう。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
| Jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| numpy==1.16.4 | OSI Approved (new BSD) |
| pandas==0.25.0 | BSD |
| scikit-learn==0.21.3 | OSI Approved (new BSD) |
データの準備¶
では処理を行っていくために、欠損値を含めたデータを作成します。
numpyで5行5列のデータを作り、pandasのデータフレームに格納します。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(1, 26).reshape(5, 5), columns=list('ABCDE'))
df
適当な値をnull値に置き換えます。
# 実行
df = df.replace([12, 23, 10], np.nan)
df
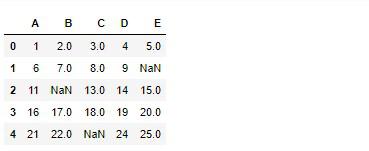
これで完成です。
scikit-learnのSimpleImputerが便利かどうか確かめる前に、pandasを使用して欠損値の取扱いを行っていきたいと思います。
Pandasを使った欠損値の置き換え¶
まずはpandasを使った欠損値の置き換えを行っていきます。
データ内にどれくらい欠損値が含まれているか確認します。
# 実行
df.isnull().sum()
# 結果
A 0
B 1
C 1
D 0
E 1
dtype: int64
もしも欠損値(null値)のある行が不必要なら、dropna()を使って除外します。
# 実行
df_drop_na = df.dropna()
df_drop_na

fillna()¶
重要なデータが少なくなってしまったので、それぞれの属性(説明変数)の欠損値に、指定した値・平均値・中央値・最頻値を順番に置き換えていきます。
# 実行
df
fillna()を使うと、欠損値に指定した値を置き換えることができます。
# 実行
df_test = df.fillna(3)
df_test
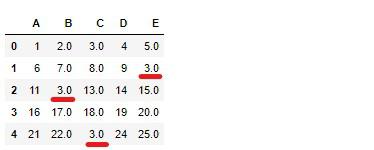
B属性の欠損値に、B属性全体の平均値に置き換えます。
# 実行
df_test_2 = df.copy()
df_test_2['B'] = df_test_2['B'].fillna(df_test_2['B'].mean())
df_test_2
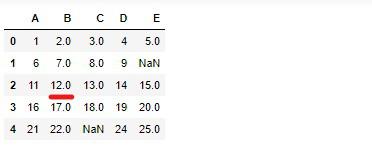
C属性の欠損値には、C属性全体の中央値に置き換えます。
# 実行
df_test_2['C'] = df_test_2['C'].fillna(df_test_2['C'].median())
df_test_2
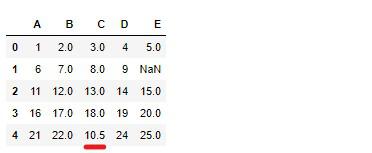
E属性の欠損値は、E属性内の最頻値に置き換えます。
# 実行
df_test_2['E'] = df_test_2['E'].fillna(df_test_2['E'].mode()[0])
df_test_2
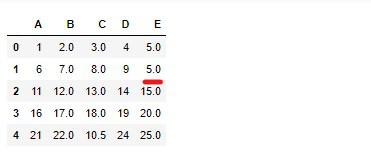
各属性によって置き換えるために求めた値は違いますが、fillna()を使って疑似的なデータとして活用できるようになります。
次にscikit-learnのSimpleImputerを使って欠損値の置き換えを行っていきます。
scikit-learnのSimpleImputer¶
scikit-learnのバージョン0.20以前では、preprocessing.Imputerが使われていましたが、バージョン0.20以降からはimpute.SimpleImputerが推奨となりました。
Scikit-Learn:SimpleImputer公式ドキュメント
インポートします。
from sklearn.impute import SimpleImputer
平均値の置き換え¶
SimpleImputerのデフォルト値は、欠損値に各属性の平均値を置き換える設定となっています。
SimpleImputer(missing_values=np.nan, strategy='mean', fill_value=None)
- missing_values:置き換える値
- strategy:統計値の種類
- fill_value:strategyがconstantになっている場合に、整数や文字列を指定して置き換える
まずは平均値を設定して欠損値の置き換えを行っていきます。
# SimpleImputerのデフォルト値
imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean', fill_value=None)
# もしくわ
# imp_mean = SimpleImputer()
fit()を行い統計結果を保管します。
imp_mean.fit(df)
各属性から算出された平均値の結果を出力してみます。
# 実行
print(imp_mean.statistics_)
# pandasの結果
print(df.mean().values)
# 結果
[11. 12. 10.5 14. 16.25]
[11. 12. 10.5 14. 16.25]
SimpleImputerはこの値を保持しているので、transform()を使えばこの結果を欠損値に置き換えることができます。
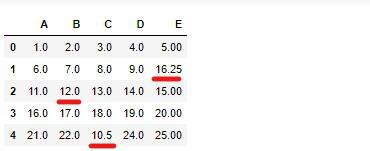
result_mean = imp_mean.transform(df)
出力される要素はnumpy配列となっているので、データフレームに格納します。
# 実行
result_mean_df = pd.DataFrame(result_mean, columns=df.columns)
result_mean_df
中央値の置き換え¶
続いて中央値に置き換えてみます。
先ほどのようにSimpleImputerの引数「strategy」に「median」を設定するだけです。
# 実行
imp_med = SimpleImputer(strategy='median')
imp_med.fit(df)
print(imp_med.statistics_)
print(df.median().values)
# 結果
[11. 12. 10.5 14. 17.5]
[11. 12. 10.5 14. 17.5]
欠損値を置き換え、結果をデータフレームに格納します。
# 実行
result_med = imp_med.transform(df)
result_med_df = pd.DataFrame(result_med, columns=df.columns)
result_med_df
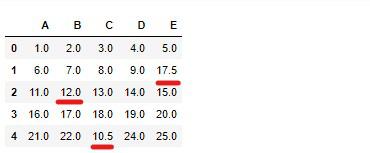
最頻値の置き換え¶
続きまして、最頻値での置き換えです。
整数やカテゴリカルなデータの文字列に適用できるので、新しくF属性を作成します。
# 実行
df_2 = pd.DataFrame([True, True, True, np.nan, False], columns=['F'])
df = pd.concat([df, df_2], axis=1)
df
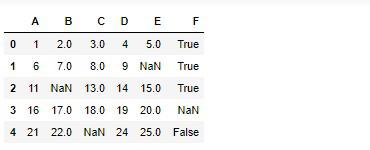
では引数strategyに、most_frequentを設定し、最頻値を計算します。
# 実行
imp_freq = SimpleImputer(strategy='most_frequent')
imp_freq.fit(df)
print(imp_freq.statistics_)
print(df.mode()[:1].values)
# 結果
[1 2.0 3.0 4 5.0 True]
[[1 2.0 3.0 4 5.0 True]]
欠損値を置き換え、結果をデータフレームに格納します。
# 実行
result_freq = imp_freq.transform(df)
result_freq_df = pd.DataFrame(result_freq, columns=df.columns)
result_freq_df

定数の置き換え¶
続いて、今度は指定した整数や文字列を欠損値に置き換えていきます。
設定は、引数strategyにconstantを与え、第3引数のfill_valueに置き換えたい整数もしくわ文字列を与えます。
# 実行
imp_const = SimpleImputer(strategy='constant', fill_value=100)
imp_const.fit(df)
print(imp_const.statistics_)
# 結果
[100, 100, 100, 100, 100, 100]
欠損値を置き換え、データフレームに格納します。
# 実行
result_const = imp_const.transform(df)
result_const_df = pd.DataFrame(result_const, columns=df.columns)
result_const_df

データを元に戻します。
# 実行
df = result_const_df.replace(100, np.nan)
df
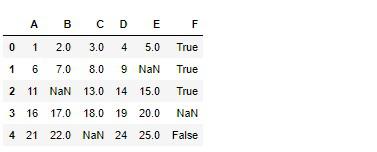
属性ごとに異なる統計結果で置き換える¶
これまでは全ての属性に同じ計算方法を使って欠損値の置き換えを行ってきましたが、各属性それぞれに異なる計算を適用させて欠損値の置き換えを行ってみたいと思います。
まず異なるSimpleImputerを初期化します。
# 平均値
imp_mean = SimpleImputer()
# 中央値
imp_med = SimpleImputer(strategy='median')
# 最頻値
imp_freq = SimpleImputer(strategy='most_frequent')
それぞれの統計に当てはめるため、属性分けしたリストを作成しイテレーションしながら適用させていきます。
# 実行
freater_b_c = [['B', 'C']]
freater_e = ['E']
freater_f = ['F']
for b_c, e, f in zip(freater_b_c, freater_e, freater_f):
df[b_c] = imp_mean.fit_transform(df[b_c])
# 1次元配列を2次元配列に変換し適用
df[e] = imp_med.fit_transform(np.array(df[e]).reshape(-1, 1))
df[f] = imp_freq.fit_transform(np.array(df[f]).reshape(-1, 1))
df
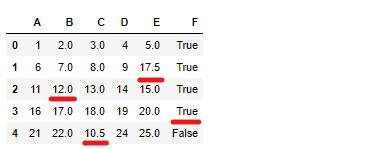
B・C属性には平均値、E属性には中央値、F属性には最頻値に欠損値が置き換えられました。
SimpleImputerをpickleファイルに保存¶
では最後に、保持された統計結果を本番システムでも使えるように保存します。
import pickle
with open('imp_mean.pickle', 'wb') as f:
pickle.dump(imp_mean, f)
with open('imp_med.pickle', 'wb') as f:
pickle.dump(imp_med, f)
with open('imp_freq.pickle', 'wb') as f:
pickle.dump(imp_freq, f)
保存された各統計値を読み込んでみましょう。
# 実行
with open('imp_mean.pickle', 'rb') as f:
imputer_mean = pickle.load(f)
with open('imp_med.pickle', 'rb') as f:
imputer_med = pickle.load(f)
with open('imp_freq.pickle', 'rb') as f:
imputer_freq = pickle.load(f)
print(imputer_mean.statistics_)
print(imputer_med.statistics_)
print(imputer_freq.statistics_)
# 結果
[12. 10.5]
[17.5]
[True]
これで未知のデータに欠損値が含まれていても、transform()をするだけで値を置き換えることができます。
それでは以上です。
最後までご覧いただき、ありがとうございました。
