【scikit-learn】OneHotEncoderによるカテゴリー属性の数値化とラベルの保存
投稿日 2020年5月17日 >> 更新日 2024年7月9日
今回は機械学習ライブラリscikit-learnのOneHotEncoderを使用して、カテゴリー属性の数値化を行っていきたいと思います。
カテゴリー属性を数値にする理由は、機械学習モデルは文字列を読み込むことができないため、代わりとなる値に置き換える必要があります。
イメージとしては、pandasのget_dummies()と同様に、カテゴリー属性内の各カテゴリーを0か1の値として新たな説明変数(ダミー変数)を作成します。
このように処理を行えば、機械学習モデルは正確に学習をして予測を行えるようになります。
「それならpandasのget_dummies()を使えばいいのでは?」と思ったかもしれませんが、その理由についても実際に実装をしてみて判断していただきたいと思います。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
| Jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| numpy==1.16.4 | OSI Approved (new BSD) |
| pandas==0.25.0 | BSD |
| scikit-learn==0.21.3 | OSI Approved (new BSD) |
データの準備¶
それでは必要なライブラリをインポートしてから、5行5列の数値属性を作成し、カテゴリー属性を新たに加えます。
# 実行
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(1, 26).reshape(5, 5), columns=list('ABCDE'))
df['F'] = ['Yes', 'No', 'Yes', 'Yes', 'No']
df
これで準備は完了です。
さっそくscikit-learnのOneHotEncoderを使って数値に変換していきたいと思います。
OneHotEncoderでカテゴリー属性の数値化¶
scikit-learn公式ドキュメント OneHotEncoder
OneHotEncoderをインポートしてから、初期化を行います。
初期化を行う際に、デフォルト引数ではsparse=Trueとなっておりスパース配列(疎行列)が返されるようになっているので、sparse=Falseにしてnumpyの行列に置き換えます。
※詳しくわ公式ドキュメントをご参照ください。
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse=False)
一次元配列を適合させる場合¶
encoderオブジェクトのfitメソッドで、データのカテゴリー属性であるF列を適合させたいところですが、そのまま渡すとエラー(「Expected 2D array, got 1D array instead:
array=['Yes' 'No' 'Yes' 'Yes' 'No'].
Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.」)となってしまいます。
二次元以上からなる配列を適合できるということなので、F列を一次元から二次元に置き換えてfitメソッドに渡します。
一次元配列の場合
# 実行
np.shape(df['F'])
# 結果
(5,)
二次元配列の場合
# 実行
np.shape(df['F'].values.reshape(-1, 1))
# 結果
(5, 1)
numpyのreshape()メソッドを使ってOneHotEncoderのfit()メソッドに渡します。
# 実行
encoder.fit(df['F'].values.reshape(-1, 1))
# 結果
OneHotEncoder(categorical_features=None, categories=None, drop=None,
dtype=<class 'numpy.float64'>, handle_unknown='error',
n_values=None, sparse=False)
fit()メソッドもしくわget_params属性で引数(scikit-learnではハイパーパラメータ)を確認することができます。
適合されたカテゴリーも確認できます。
# 実行
encoder.categories_
# 結果
[array(['No', 'Yes'], dtype=object)]
それでは変換を行い出力してみます。
# 実行
arr = encoder.transform(df['F'].values.reshape(-1, 1))
arr
# 結果
array([[0., 1.],
[1., 0.],
[0., 1.],
[0., 1.],
[1., 0.]])
このように0か1の値となってnumpy配列で出力されます。
データフレームに格納する場合は、arr変数とcolumnsに先ほどのcategories_属性を渡します。
# 実行
df_onehot = pd.DataFrame(arr, columns=encoder.categories_)
df_onehot

他にも、多重共線性と言った問題を避けるために、カテゴリーの1つ目を除外することができます。
その場合は、引数drop=Noneをdrop='first'に切り替えます。
# 実行
encoder = OneHotEncoder(drop='first', sparse=False)
# 適合と変換を一度で行う
arr_d_first = encoder.fit_transform(df['F'].values.reshape(-1, 1))
arr_d_first
# 結果
array([[1.],
[0.],
[1.],
[1.],
[0.]])
二次元以上の配列を適合させる場合¶
二次元以上からなるカテゴリー属性であれば、OneHotEncoderにそのままフィットさせることができます。
データをコピーして新たなデータを作成します。
# 実行
df_2 = df.copy()
df_2['G'] = ['Width', 'Width', 'Height', 'Height', 'Width']
df_2
このデータのカテゴリー属性を渡します。
※先ほどのencoderオブジェクトを使っているので、各カテゴリー属性の1つ目のカテゴリーは除外されています。
# 実行
arr_2 = encoder.fit_transform(df_2[['F', 'G']])
arr_2
# 結果
array([[1., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.]])
各カテゴリーの確認
# 実行
encoder.categories_
# 結果
[array(['No', 'Yes'], dtype=object), array(['Height', 'Width'], dtype=object)]
get_dummies()を使わない理由¶
これまで行ってきたカテゴリー属性の数値への変換は、pandasのget_dummies()を使えば簡単に実行することができます。
# 実行
pd.get_dummies(df_2)
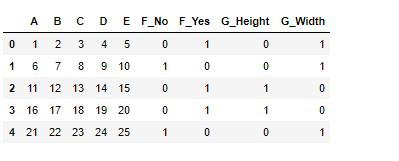
非常に便利なことが分かります。
では例として、上記のような配列で機械学習モデルに訓練を行った場合、本番システムでの未知データに対してどのように処理されるか見ていきます。
未知データにも訓練前と同じ前処理を施す必要があるので、実際に行ってみます。
未知のデータとして1つだけ取り出します。
# 実行
test_data = df_2[:1].copy()
test_data

先ほどのget_dummies()されたデータで機械学習モデルに訓練を行った場合、9次元の配列が必要となります。
※行×列
# 実行
np.shape(pd.get_dummies(df_2))
# 結果
(5, 9)
未知のデータが流れてきたとして、そのままget_dummies()に渡してみると
# 実行
pd.get_dummies(test_data)

上記のようにカテゴリー属性内カテゴリーが1つしか見えていないためそれぞれ1つの説明変数しか作成されていません。
このように次元数が異なってしまうと機械学習モデルは予測を行えなくなります。
# 実行
np.shape(pd.get_dummies(test_data))
# 結果
(1, 7)
OneHotEncoderを使って前処理を行うと、fit()メソッドにより適合されたカテゴリーのラベルを保持しているので、訓練データと同等の変換を未知データに対して行ってくれます。
# 実行
encoder = OneHotEncoder(sparse=False)
encoder.fit(df_2[['F', 'G']])
encoder.transform(test_data[['F', 'G']])
# 結果
array([[0., 1., 0., 1.]])
なので、「pandasのget_dummies()を使わない」のではなく、場面に応じてそれぞれのツールを使用していくのが良いかと思います。
本番システムでも使えるように保存¶
pickleファイルに保存して、いつでも使えるようにしていきましょう。
import pickle
with open('onehot.pickle', 'wb') as f:
pickle.dump(encoder, f)
読み込んで使用してみます。
with open('onehot.pickle', 'rb') as f:
enc = pickle.load(f)
arr_cat = enc.transform(test_data[['F', 'G']])
# exclude=はオブジェクト以外を取り出す
arr_num = test_data.select_dtypes(exclude=['object']).values
new_test_data = np.concatenate([arr_num, arr_cat], axis=1)
new_test_data
# 結果
array([[1., 2., 3., 4., 5., 0., 1., 0., 1.]])
本番システムでは無駄な処理を行わず簡易的に実行させることで、トラブルも回避できるかと思います。
それでは以上となります。
最後までご覧いただきありがとうございました。