【scikit-learn】BaseEstimatorを継承して自作変換器のハイパーパラメータを取得する
投稿日 2020年5月18日 >> 更新日 2024年7月9日
今回は、機械学習ライブラリのscikit-learnからBaseEstimatorを継承して自作変換器のハイパーパラメータを取得していきたいと思います。
ハイパーパラメータ?と思う方もいらっしゃると思いますが、機械学習ではパラメータ(決定係数)を定めるためにハイパーパラメータを順次設定していきます。
scikit-learnでのハイパーパラメータは、fit()メソッドで適合された時に以下のような引数が表示されるかと思います。
※例:SGD回帰(確率的勾配降下法)
SGDRegressor(alpha=0.0001, average=False, early_stopping=False, epsilon=0.1,
eta0=0.01, fit_intercept=True, l1_ratio=0.15,
learning_rate='invscaling', loss='squared_loss', max_iter=1000,
n_iter_no_change=5, penalty='l2', power_t=0.25, random_state=None,
shuffle=True, tol=0.001, validation_fraction=0.1, verbose=0,
warm_start=False)
そして上記のように表示されるのは、scikit-learnで使用できる全ての基本クラスでBaseEstimatorが使われているからです。
まずはシンプルな変換器を作成してBaseEstimatorを継承してみたいと思います。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
| Jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| numpy==1.16.4 | OSI Approved (new BSD) |
| pandas==0.25.0 | BSD |
| scikit-learn==0.21.3 | OSI Approved (new BSD) |
シンプルな変換器の作成¶
numpyとpandasをインポートしてから、SimpleConverterというクラスを作成しました。
import pandas as pd
import numpy as np
class SimpleConverter():
# 初期化メソッド
def __init__(self, feature='add', n_1=None, n_2=None, dataframe=True):
self.feature = feature
self.n_1 = n_1
self.n_2 = n_2
self.dataframe = dataframe
# Xが渡されたら初期化メソッドの引数に従って処理を行う
def transform(self, X):
if self.n_1 or self.n_2 != None:
n_1 = self.n_1
n_2 = self.n_2
arr_add = X[:, n_1] + X[:, n_2]
if self.dataframe:
return pd.DataFrame(np.c_[X, arr_add])
else:
return np.c_[X, arr_add]
if self.dataframe:
return pd.DataFrame(X)
else:
return X
この変換器はnumpy配列が渡された時に初期化メソッドの引数に従って処理を行います。
初期化メソッド引数では
- feature:'add'は単に処理内容の加算を示しているだけですが、n_1(列)・n_2(列)に数字が渡されたときに実行されます。
- n_1/n_2:デフォルトNoneでは何もせず返し、渡された配列の列数を与えると列同士で加算されます。加算された結果は元の配列に結合されて返します。
- dataframe:デフォルTrueでは、pandasのデータフレームを使って格納します。Falseはnumpy配列。
- transformメソッドとしているのは、後々scikit-learnに準拠させていくために定めました。
では試しに5行5列のnumpy配列を作成して、自作変換器に流してみます。
# 実行
arr = np.arange(1, 26).reshape(5, 5)
arr
# 結果
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
デフォルト設定の変換器に与えてみると
# 実行
converter = SimpleConverter()
converter.transform(arr)

n_1/n_2はNoneなので、データフレームにだけ格納されて返ってきます。
では0番目と1番目の列を加算して、結果を元の配列と結合して出力してみます。
# 実行
converter = SimpleConverter(dataframe=True, n_1=0, n_2=1)
converter.transform(arr)
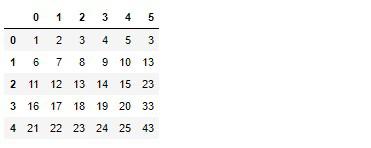
0番目と1番目が加算された結果が5番目(6列目)へ結合されました。
dataframeをFalseにして、他の列数を与えてみるとどうなるか見てみます。
# 実行
converter = SimpleConverter(dataframe=False, n_1=1, n_2=4)
converter.transform(arr)
# 結果
array([[ 1, 2, 3, 4, 5, 7],
[ 6, 7, 8, 9, 10, 17],
[11, 12, 13, 14, 15, 27],
[16, 17, 18, 19, 20, 37],
[21, 22, 23, 24, 25, 47]])
n_1/n_2に1番目(2列目)と4番目(5列目)を選択したので、暗算を行ってもしっかり機能していることが分かります。
この自作変換器にBaseEstimatorを継承させてみたいと思います。
BaseEstimatorの継承¶
Scikit-Learn公式ドキュメント BaseEstimator
BaseEstimatorを継承する際は、初期化メソッドが定義されている必要があります。
初期化メソッドが定義されていなくても自作変換器自体は動きますが、BaseEstimatorの真骨頂であるパラメータの取得を行えなくなってしまうので、定義しておきます。
BaseEstimatorをインポートし、自作変換器に継承させます。
from sklearn.base import BaseEstimator
class SimpleConverter(BaseEstimator):
# 初期化メソッド
def __init__(self, feature='add', n_1=None, n_2=None, dataframe=True):
self.feature = feature
self.n_1 = n_1
self.n_2 = n_2
self.dataframe = dataframe
def transform(self, X):
if self.n_1 or self.n_2 != None:
n_1 = self.n_1
n_2 = self.n_2
arr_add = X[:, n_1] + X[:, n_2]
if self.dataframe:
return pd.DataFrame(np.c_[X, arr_add])
else:
return np.c_[X, arr_add]
if self.dataframe:
return pd.DataFrame(X)
else:
return X
たったこれだけで、scikit-learnモジュールに半分だけ仲間入りできました。
完全に仲間入りするためには、他のクラスも継承させる必要があるので、余力のある方はこちらも合わせてご覧になってみてください。
ではBaseEstimatorを継承する事によりどのようなことができるのか見ていきます。
n_1とn_2に適当な値を与え初期化します。
converter_es = SimpleConverter(n_1=3, n_2=4, dataframe=False)
BaseEstimatorが継承された自作変換器には、get_params()メソッドとset_params()メソッドが使用できるようになります。
get_params()メソッドではハイパーパラメータ(初期化メソッドの引数)を出力できます。
# 実行
converter_es.get_params()
# 結果
{'dataframe': False, 'feature': 'add', 'n_1': 3, 'n_2': 4}
set_params()メソッドでは、ハイパーパラメータ値を再設定することができます。
dataframe=FalseをTrueに再設定してみます。
# 実行
converter_es.set_params(dataframe=True)
# 結果
SimpleConverter(dataframe=True, feature='add', n_1=3, n_2=4)
set_params()メソッドに変更したいハイパーパラメータ値を設定するだけで、内容は反映されているので、get_params()、もしくわnumpy配列を与えてtransformして確認してみましょう。
# 実行
converter_es.transform(arr)
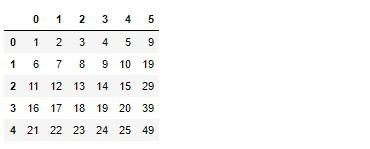
しっかり機能していることが分かります。
最後に、冒頭でも表示したfit()メソッドによるハイパーパラメータの出力が行えるように、新たに関数を定義して終わりたいと思います。
class SimpleConverter(BaseEstimator):
def __init__(self, feature='add', n_1=None, n_2=None, dataframe=True):
self.feature = feature
self.n_1 = n_1
self.n_2 = n_2
self.dataframe = dataframe
# fit()メソッドが呼び出された時にハイパーパラメータを返す
def fit(self, X):
return self
def transform(self, X):
if self.n_1 or self.n_2 != None:
n_1 = self.n_1
n_2 = self.n_2
arr_add = X[:, n_1] + X[:, n_2]
if self.dataframe:
return pd.DataFrame(np.c_[X, arr_add])
else:
return np.c_[X, arr_add]
if self.dataframe:
return pd.DataFrame(X)
else:
return X
適合してみます。
# 実行
converter_es = SimpleConverter()
converter_es.fit(arr)
# 結果
SimpleConverter(dataframe=True, feature='add', n_1=None, n_2=None)
fit()メソッドではハイパーパラメータを返す処理だけですが、scikit-learnのモジュールに近づけることができました。
BaseEstimatorとMixinクラス¶
ここではscikit-learnの全ての基本クラスで使われているBaseEstimatorを実装していきましたが、他にもBaseEstimatorと組み合わせて実装できるMixinクラスがScikit-Learnにはあります。
いわゆる多重継承をすることによって、自作変換器が完全なScikit-Learnモジュールへと生まれ変わることができるようになります。
scikit-learnと同等の扱いができることによって、変換器(推定器など)同士を組み合わせられるPipelineに充てることができます。
そのような実装に関してはこちらをご参照ください。
それでは以上となります。
最後までご覧いただきありがとうございました。
