【scikit-learn】自作変換器にTransformerMixinを継承してfit_transformメソッドを使えるようにする
投稿日 2020年5月19日 >> 更新日 2024年7月9日
今回は自作変換器にscikit-learnのTransformerMixinクラスを継承して、適合と変換を一括で処理できるfit_transformメソッドを使えるようにしていきたいと思います。
この記事の後半で話題にしますが、fit_transformメソッドが使えるようになることで、scikit-learnのPipelineというクラスを使い、scikit-learn内の変換器をまとめて1つのオブジェクトとして使うことができます。
既存の変換器だけでも便利ですが、自分で作成した前処理用のオブジェクトなんかも一緒にまとめられて一括処理が行えるとなると、さらに便利です。
非常に簡単なクラス定義で実装できるので試してみましょう。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
| Jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| numpy==1.16.4 | OSI Approved (new BSD) |
| pandas==0.25.0 | BSD |
| scikit-learn==0.21.3 | OSI Approved (new BSD) |
シンプルな変換器の作成¶
numpyとpandasをインポートしてから、SimpleConverterというクラスを作成しました。
import pandas as pd
import numpy as np
class SimpleConverter():
# 初期化メソッド
def __init__(self, feature='add', n_1=None, n_2=None, dataframe=True):
self.feature = feature
self.n_1 = n_1
self.n_2 = n_2
self.dataframe = dataframe
# Xが渡されたら初期化メソッドの引数に従って処理を行う
def transform(self, X):
if self.n_1 or self.n_2 != None:
n_1 = self.n_1
n_2 = self.n_2
arr_add = X[:, n_1] + X[:, n_2]
if self.dataframe:
return pd.DataFrame(np.c_[X, arr_add])
else:
return np.c_[X, arr_add]
if self.dataframe:
return pd.DataFrame(X)
else:
return X
この変換器はnumpy配列が渡された時に初期化メソッドの引数に従って処理を行います。
初期化メソッド引数では
- feature:'add'は単に処理内容の加算を示しているだけですが、n_1(列)・n_2(列)に数字が渡されたときに実行されます。
- n_1/n_2:デフォルトNoneでは何もせず返し、渡された配列の列数を与えると列同士で加算されます。加算された結果は元の配列に結合されて返します。
- dataframe:デフォルTrueでは、pandasのデータフレームを使って格納します。Falseはnumpy配列。
- transformメソッドとしているのは、後々scikit-learnに準拠させていくために定めました。
では試しに5行5列のnumpy配列を作成して、自作変換器に流してみます。
# 実行
arr = np.arange(1, 26).reshape(5, 5)
arr
# 結果
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
デフォルト設定の変換器に与えてみると
# 実行
converter = SimpleConverter()
converter.transform(arr)

n_1/n_2はNoneなので、データフレームにだけ格納されて返ってきます。
では0番目と1番目の列を加算して、結果を元の配列と結合して出力してみます。
# 実行
converter = SimpleConverter(dataframe=True, n_1=0, n_2=1)
converter.transform(arr)
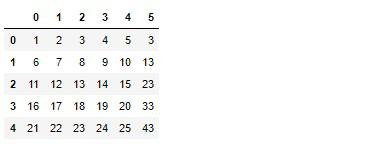
0番目と1番目が加算された結果が5番目(6列目)へ結合されました。
dataframeをFalseにして、他の列数を与えてみるとどうなるか見てみます。
# 実行
converter = SimpleConverter(dataframe=False, n_1=1, n_2=4)
converter.transform(arr)
# 結果
array([[ 1, 2, 3, 4, 5, 7],
[ 6, 7, 8, 9, 10, 17],
[11, 12, 13, 14, 15, 27],
[16, 17, 18, 19, 20, 37],
[21, 22, 23, 24, 25, 47]])
n_1/n_2に1番目(2列目)と4番目(5列目)を選択したので、暗算を行ってもしっかり機能していることが分かります。
この自作変換器にTransformerMixinを継承させてみたいと思います。
TransformerMixinの継承¶
scikit-learnの公式ドキュメント TransformerMixin
TransformerMixinクラスはscikit-learnで使用できる全ての変換器に使われていると言われています。
さっそく自作変換器に継承していきますが、fitメソッドとtransformメソッドを定義する必要があります。
transformメソッドは定義してあるので、fitメソッドを新たに定義しておきましょう。
from sklearn.base import TransformerMixin
class SimpleConverter(TransformerMixin):
def __init__(self, feature='add', n_1=None, n_2=None, dataframe=True):
self.feature = feature
self.n_1 = n_1
self.n_2 = n_2
self.dataframe = dataframe
# 戻り値はこのオブジェクトを参照するだけ
def fit(self, X):
return self
# 変換
def transform(self, X):
if self.n_1 or self.n_2 != None:
n_1 = self.n_1
n_2 = self.n_2
arr_add = X[:, n_1] + X[:, n_2]
if self.dataframe:
return pd.DataFrame(np.c_[X, arr_add])
else:
return np.c_[X, arr_add]
if self.dataframe:
return pd.DataFrame(X)
else:
return X
では、適当な値を当てはめ初期化します。
converter_tf = SimpleConverter(n_1=0, n_2=4)
fitメソッドは、オブジェクト自身を参照します。
# 実行
converter_tf.fit(arr)
# 結果
__main__.SimpleConverter at 0x7fc481536160
transformメソッドで、要素が変換されます。
# 実行
converter_tf.transform(arr)
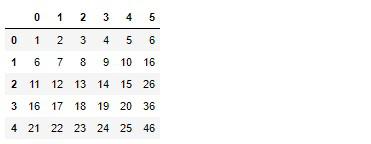
では同じことの繰り返しですが、fit_transformで適合と変換を一括処理します。
# 実行
converter_tf.fit_transform(arr)
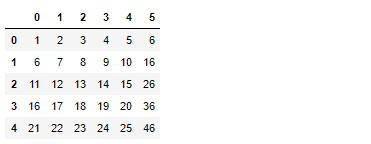
もちろんfitメソッドはselfを返しているので適合とは言えませんが、scikit-learnのモジュールとして扱う事ができるようになりました。
しかしまだ完全体ではありません。
もう1つのクラス、BaseEstimatorクラスを加えることで完全なscikit-learnモジュールとして仲間入りすることができます。
TransformerMixinとBaseEstimatorの多重継承¶
BaseEstimatorに関してはこちらの記事をご参照してみてください。
scikit-learnからBaseEstimatorをインポートし、自作変換器に多重継承します。
from sklearn.base import BaseEstimator, TransformerMixin
class SimpleConverter(BaseEstimator, TransformerMixin):
def __init__(self, feature='add', n_1=None, n_2=None, dataframe=True):
...
...
...
これでこの自作変換器には、get_params()とset_params()によるハイパーパラメータの参照・設定と、fit_transform()による適合と変換の3つのメソッドを使えるようになりました。
この自作変換器のfitメソッドではオブジェクト自身を参照するようにselfとしているので、初期化メソッドの、すなわちハイパーパラメータを参照することができます。
# 実行
converter_tf = SimpleConverter(dataframe=False, n_1=0, n_2=4)
converter_tf.fit(arr)
# 結果
SimpleConverter(dataframe=False, feature='add', n_1=0, n_2=4)
最後にscikit-learnと同じメソッドが使えるようになると、どのように便利になるか見ていきたいと思います。
Pipelineによる実装¶
scikit-learnにはPipelineというクラスが用意されています。
このPipelineは、引数に順次変換を行いたい変換器を与えて、最後に変換された要素を返します。
例えば自作変換器と標準化を行うscikit-learnのStandardScalerを使用してPipelineに設定してみたいと思います。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipeline = Pipeline([
('conversion', SimpleConverter(n_1=0, n_2=1)),
('scaler', StandardScaler()),
])
変換は、先に与えられたオブジェクトから順次行っていくので、順番を間違えないようにします。
ではfit_transformメソッドを呼び出すとどうなるか。
# 実行
pipeline.fit_transform(arr)
# 結果
array([[-1.41421356, -1.41421356, -1.41421356, -1.41421356, -1.41421356],
[-0.70710678, -0.70710678, -0.70710678, -0.70710678, -0.70710678],
[ 0. , 0. , 0. , 0. , 0. ],
[ 0.70710678, 0.70710678, 0.70710678, 0.70710678, 0.70710678],
[ 1.41421356, 1.41421356, 1.41421356, 1.41421356, 1.41421356]])
最終で標準化が行われているのが分かります。
get_params()もしくわset_params()を呼び出して、各変換器のハイパーパラメータを確認できます。
# 実行
pipeline.set_params()
# 結果
Pipeline(memory=None,
steps=[('conversion',
SimpleConverter(dataframe=True, feature='add', n_1=None,
n_2=None)),
('scaler',
StandardScaler(copy=True, with_mean=True, with_std=True))],
verbose=False)
Pipelineに関してはこちらの記事で詳しく実装していますので、宜しければ下記もご参照ください。
それでは以上となります。
最後までご覧いただきありがとうございました。