【scikit-learn】Pipelineと簡素化版のmake_pipelineを使いscikit-learnモジュールを組み合わせて一括処理
投稿日 2020年5月21日 >> 更新日 2024年7月9日
今回は、scikit-learnのPipelineモジュールを使用して、scikit-learnのモジュールである変換器や機械学習モデルを一括処理させる実装を行っていきたいと思います。
一度Pipelineにモジュールをまとめ上げてしまえば、Pipeline独自のメソッドを利用していつでもハイパーパラメータなどを再設定することができます。
また、Pipelineの簡素化版であるmake_pipelineも後半で実装していきます。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
| Jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| numpy==1.16.4 | OSI Approved (new BSD) |
| pandas==0.25.0 | BSD |
| scikit-learn==0.21.3 | OSI Approved (new BSD) |
自作変換器の準備¶
必要なライブラリをインポートして、SimpleConverterという自作変換器を作成します。
SimpleConverterには、scikit-learnモジュールのBaseEstimatorクラスとTransformerMixinクラスが多重継承されており、scikit-learnで使われている基本的なメソッドが使えるようになります。
BaseEstimatorやTransformerMixinについての詳しい内容はこちらの記事をご参照ください。
import numpy as np
import pandas as pd
from sklearn.base import BaseEstimator, TransformerMixin
class SimpleConverter(BaseEstimator, TransformerMixin):
def __init__(self, feature='add', n_1=None, n_2=None, dataframe=True):
self.feature = feature
self.n_1 = n_1
self.n_2 = n_2
self.dataframe = dataframe
def fit(self, X):
return self
def transform(self, X):
if self.n_1 or self.n_2 != None:
n_1 = self.n_1
n_2 = self.n_2
arr_add = X[:, n_1] + X[:, n_2]
if self.dataframe:
return pd.DataFrame(np.c_[X, arr_add])
else:
return np.c_[X, arr_add]
if self.dataframe:
return pd.DataFrame(X)
else:
return X
この変換器はnumpy配列が渡された時に初期化メソッドの引数に従って処理を行います。
初期化メソッド引数では
- feature:'add'は単に処理内容の加算を示しているだけですが、n_1(列)・n_2(列)に数字が渡されたときに実行されます。
- n_1/n_2:デフォルトNoneでは何もせず返し、渡された配列の列数を与えると列同士で加算されます。加算された結果は元の配列に結合されて返します。
- dataframe:デフォルTrueでは、pandasのデータフレームを使って格納します。Falseはnumpy配列。
- transformメソッドとしているのは、後々scikit-learnに準拠させていくために定めました。
では試しに5行5列のnumpy配列を作成して、自作変換器に流してみます。
# 実行
arr = np.arange(1, 26).reshape(5, 5)
arr
# 結果
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
デフォルト設定の変換器に与えてみると
# 実行
converter = SimpleConverter()
converter.fit_transform(arr)

n_1/n_2はNoneなので、データフレームにだけ格納されて返ってきます。
では0番目と1番目の列を加算して、結果を元の配列と結合して出力してみます。
# 実行
converter = SimpleConverter(dataframe=True, n_1=0, n_2=1)
converter.fit_transform(arr)
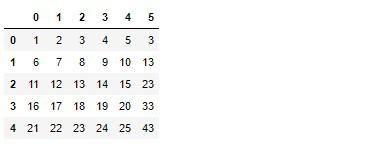
0番目と1番目が加算された結果が5番目(6列目)へ結合されました。
dataframeをFalseにして、他の列数を与えてみるとどうなるか見てみます。
# 実行
converter = SimpleConverter(dataframe=False, n_1=1, n_2=4)
converter.fit_transform(arr)
# 結果
array([[ 1, 2, 3, 4, 5, 7],
[ 6, 7, 8, 9, 10, 17],
[11, 12, 13, 14, 15, 27],
[16, 17, 18, 19, 20, 37],
[21, 22, 23, 24, 25, 47]])
n_1/n_2に1番目(2列目)と4番目(5列目)を選択したので、暗算を行ってもしっかり機能していることが分かります。
では他のscikit-learnモジュール(変換器)と、この自作変換器を交えてPipelineに順次変換を実装していきます。
Pipelineの実装¶
いよいよPipelineに各変換器をまとめていきますが、色々な変換器を取り入れて結果を出力したいので、先ほど自作変換器に与えていたarrデータをpandasのデータフレームに格納し、numpyを使って幾つか欠損値を作ります。
# 実行
df = pd.DataFrame(arr, columns=list('ABCDE'))
df = df.replace([12, 23, 10], np.nan)
df
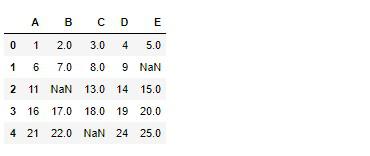
scikit-learnの各モジュールをインポートして、Pipelineを組み上げていきます。
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('imputer', SimpleImputer()),
('conversion', SimpleConverter(n_1=0, n_2=1)),
('scaler', StandardScaler())
])
Pipelineの引数には、リスト形式内に1つのオブジェクトに対してタプルで定義します。
タプルでは辞書型のようにオブジェクトの名前となるキーを定義して、その名前に当てはまるオブジェクトを定義します。
名前付けする理由は後の実装で明らかになります。
そしてPipelineはリスト内に先に定義されたオブジェクトから変換が行われるので、ここではSimpleImputer、SimpleConverter、StandardScalerという順番で処理が行われます。
SimpleImputerの詳しい実装についてこちらをご参照ください。
準備ができたので、Pipelineにデータを適合してみます。
# 実行
pipeline.fit(df)
# 結果
Pipeline(memory=None,
steps=[('imputer',
SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='mean',
verbose=0)),
('conversion',
SimpleConverter(dataframe=True, feature='add', n_1=0, n_2=1)),
('scaler',
StandardScaler(copy=True, with_mean=True, with_std=True))],
verbose=False)
fitメソッドを呼び出すと、stepsパラメータ内の各オブジェクトのハイパーパラメータに従って適合されます。
ではtransformメソッドで変換を行ってみます。
※fit_transformで適合・変換
# 実行
arr_result = pipeline.transform(df)
arr_result
# 結果
array([[-1.41421356, -1.41421356, -1.5 , -1.41421356, -1.70084013,
-1.41421356],
[-0.70710678, -0.70710678, -0.5 , -0.70710678, 0. ,
-0.70710678],
[ 0. , 0. , 0.5 , 0. , -0.18898224,
0. ],
[ 0.70710678, 0.70710678, 1.5 , 0.70710678, 0.56694671,
0.70710678],
[ 1.41421356, 1.41421356, 0. , 1.41421356, 1.32287566,
1.41421356]])
結果は上記のようになりました。
少し分りずらいので、各オブジェクトの変換器を手動で行ってみて、等しい結果なのかを比べてみましょう。
Pipelineの結果はデータフレームに渡すだけなので、先に手動で変換を行っていきます。
# 実行
imp = SimpleImputer()
converter = SimpleConverter(n_1=0, n_2=1)
scaler = StandardScaler()
df_imp = imp.fit_transform(df)
df_converter = converter.fit_transform(df_imp)
df_scaler = scaler.fit_transform(df_converter)
df_manual = pd.DataFrame(df_scaler, columns=list('ABCDEF'))
df_manual
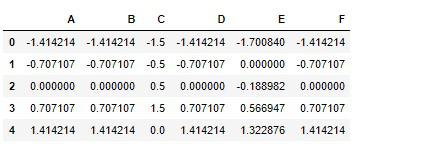
ではPipelineの出力をデータフレームに格納します。
# 実行
df_automatic = pd.DataFrame(arr_result, columns=df_manual.columns)
df_automatic
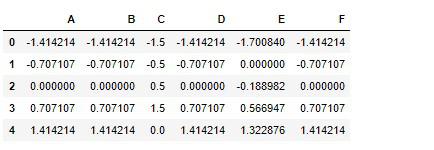
問題無く機能しているのが分かります。
Pipelineには、他のscikit-learnモジュール同様BaseEstimatorクラスが継承されているため、get_paramsとset_params属性を使用することができます。
get_paramsではPipelineのハイパーパラメータを確認することができます。
# 実行
pipeline.get_params()
# 結果
{'memory': None,
'steps': [('imputer',
SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='mean', verbose=0)),
('conversion', SimpleConverter(dataframe=True, feature='add', n_1=0, n_2=1)),
('scaler', StandardScaler(copy=True, with_mean=True, with_std=True))],
'verbose': False,
'imputer': SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='mean', verbose=0),
'conversion': SimpleConverter(dataframe=True, feature='add', n_1=0, n_2=1),
'scaler': StandardScaler(copy=True, with_mean=True, with_std=True),
'imputer__add_indicator': False,
'imputer__copy': True,
'imputer__fill_value': None,
'imputer__missing_values': nan,
'imputer__strategy': 'mean',
'imputer__verbose': 0,
'conversion__dataframe': True,
'conversion__feature': 'add',
'conversion__n_1': 0,
'conversion__n_2': 1,
'scaler__copy': True,
'scaler__with_mean': True,
'scaler__with_std': True}
次にset_params属性で、ハイパーパラメータ値を変更していきます。
ハイパーパラメータ値を変更するには、get_paramsでも表示されている変換器に名前付けされたキーを変数に渡します(例:imputer__...)。
名前付けされている理由は、個々の変換器を指定できるようにしているためです。
試しにSimpleImputerの統計値を中央値に変更し、自作変換器のSimpleConverterのデータフレーム化をFalseに変更してみます。
# 実行
# 名前の後にアンダースコア2個でアクセスできる
pipeline.set_params(imputer__strategy='median', conversion__dataframe=False)
# 結果
Pipeline(memory=None,
steps=[('imputer',
SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='median',
verbose=0)),
('conversion',
SimpleConverter(dataframe=False, feature='add', n_1=0, n_2=1)),
('scaler',
StandardScaler(copy=True, with_mean=True, with_std=True))],
verbose=False)
get_params属性を使って、変更が反映されているか確認してみます。
# 実行
pipeline.get_params()
# 結果
{'memory': None,
'steps': [('imputer',
SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='median', verbose=0)),
('conversion',
SimpleConverter(dataframe=False, feature='add', n_1=0, n_2=1)),
('scaler', StandardScaler(copy=True, with_mean=True, with_std=True))],
'verbose': False,
'imputer': SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='median', verbose=0),
'conversion': SimpleConverter(dataframe=False, feature='add', n_1=0, n_2=1),
'scaler': StandardScaler(copy=True, with_mean=True, with_std=True),
'imputer__add_indicator': False,
'imputer__copy': True,
'imputer__fill_value': None,
'imputer__missing_values': nan,
'imputer__strategy': 'median', ←meanからmedianに
'imputer__verbose': 0,
'conversion__dataframe': False, ←TrueからFalseに
'conversion__feature': 'add',
'conversion__n_1': 0,
'conversion__n_2': 1,
'scaler__copy': True,
'scaler__with_mean': True,
'scaler__with_std': True}
すべての変換器をまとめて管理できるので非常に便利です。
機械学習モデルを組み合わせたPipeline¶
Pipelineは、変換器だけではなく機械学習モデルも組み合わせて一括処理を行うことができます。
Pipelineは機械学習モデルで使われているメソッドも持ち合わせているので、変換器の後に付け加えることで順次実行してくれます。
機械学習モデルで適合する際のfitメソッドでは、説明変数Xと目的変数yを引数に与えるので、自作変換器のfitメソッド引数にy=Noneを追記します。
class SimpleConverter(BaseEstimator, TransformerMixin):
def __init__(self, feature='add', n_1=None, n_2=None, dataframe=True):
self.feature = feature
self.n_1 = n_1
self.n_2 = n_2
self.dataframe = dataframe
# y=Noneを追記
def fit(self, X, y=None):
return self
# 変換
def transform(self, X):
if self.n_1 or self.n_2 != None:
n_1 = self.n_1
n_2 = self.n_2
arr_add = X[:, n_1] + X[:, n_2]
if self.dataframe:
return pd.DataFrame(np.c_[X, arr_add])
else:
return np.c_[X, arr_add]
if self.dataframe:
return pd.DataFrame(X)
else:
return X
実際はハイパーパラメータを返すだけですが、これで機械学習モデルを組み合わせてもfitで適合できるようになりました。
機械学習モデルは、線形回帰を使って行きます。
説明変数が欲しいので、scikit-learnのデータセット内からカリフォルニア住宅価格をロードして予測を行います。
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_california_housing
# 説明変数
X = fetch_california_housing().data
# 目的変数
y = fetch_california_housing().target
ではPipelineを組み立てます。
lin_pipeline = Pipeline([
('imputer', SimpleImputer()),
('conversion', SimpleConverter(n_1=0, n_2=1)),
('scaler', StandardScaler()),
('lin_reg', LinearRegression()),
])
fitメソッドで適合します。
# 実行
lin_pipeline.fit(X, y)
# 結果
Pipeline(memory=None,
steps=[('imputer',
SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='mean',
verbose=0)),
('conversion',
SimpleConverter(dataframe=True, feature='add', n_1=0, n_2=1)),
('scaler',
StandardScaler(copy=True, with_mean=True, with_std=True)),
('lin_reg',
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None,
normalize=False))],
verbose=False)
scoreメソッドを呼び出すと、それぞれの変換器が順次変換(transform)されたあとに線形回帰の精度が出力されます。
# 実行
lin_pipeline.score(X, y)
# 結果
0.6062326851998049
transformをしていないので少し不思議に感じられますが、Pipelineで機械学習モデルの推定量を出力される際は先に変換が適用されるようになっています。
テストデータを作って予測を行ってみます。
# 実行
X_test = X[:1]
y_test = y[:1]
print('予測子:{}'.format(lin_pipeline.predict(X_test)))
print('\n')
print('ラベル:{}'.format(y_test))
# 結果
予測子:[4.13164983]
ラベル:[4.526]
予測もしっかり行えています(精度は別として)。
他にも様々な属性が用意されているので余力のある方はドキュメント等を見て試してみて下さい。
Pipelineの簡素版、make_pipeline¶
scikit-learnの公式ドキュメント make_pipeline
make_pipelineはPipelineを簡素化させた、つまり無駄を無くし簡単な実装が行える代物です。
Pipelineの実装では、オブジェクトをタプルで定義し、名前付けを自ら行っていました。
make_pipelineでは、オブジェクトが定義されたコードから自動的に名前付けがされます。
従って引数には単にオブジェクトだけ与えればmake_pipelineは順次実行されます。
では実装してみましょう。
# 実行
from sklearn.pipeline import make_pipeline
make_pipe = make_pipeline(SimpleImputer(),
SimpleConverter(n_1=0, n_2=1),
StandardScaler(),
LinearRegression())
make_pipe.fit(X, y)
# 結果
Pipeline(memory=None,
steps=[('simpleimputer',
SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='mean',
verbose=0)),
('simpleconverter',
SimpleConverter(dataframe=True, feature='add', n_1=0, n_2=1)),
('standardscaler',
StandardScaler(copy=True, with_mean=True, with_std=True)),
('linearregression',
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None,
normalize=False))],
verbose=False)
steps引数の文字列を見てみると、オブジェクト名が小文字へと自動で名前付けされています。
先ほどのテストデータを使用して予測を行ってみます。
# 実行
print('予測子:{}'.format(make_pipe.predict(X_test)))
print('\n')
print('ラベル:{}'.format(y_test))
# 結果
予測子:[4.12583785]
ラベル:[4.526]
set_paramsでハイパーパラメータを変更してみます。
# 実行
make_pipe.set_params(simpleimputer__strategy='median')
# 結果
Pipeline(memory=None,
steps=[('simpleimputer',
SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='median',
verbose=0)),
('simpleconverter',
SimpleConverter(dataframe=True, feature='add', n_1=0, n_2=1)),
('standardscaler',
StandardScaler(copy=True, with_mean=True, with_std=True)),
('linearregression',
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None,
normalize=False))],
verbose=False)
簡単な説明でしたがここまでが、Pipelineとmake_pipelineを使用してオブジェクトを組み合わせた一括処理の実装です。
pickleファイルに保存できることから、本番システムでの実装も無駄なコードを定義せずファイル1つ読み込むだけで行うことができてしまいます。
非常に便利な機能です。
scikit-learnではさらに層を厚くできるFeatureUnionというモジュールがあります。
FeatureUnionは前処理の一括変換に特化したモジュールなので、非常に便利です。
宜しければこちらの記事をご参照ください。
それでは以上となります。
最後までご覧いただきありがとうございました。
