【Django】django-pandasを使用してFileFieldからCSVファイルを読み込んで柔軟に詳細表示する
投稿日 2020年8月31日 >> 更新日 2023年3月1日
今回はdjango-pandasというデータ分析ライブラリを使用して、アップロードされている様々なCSVファイルを柔軟に詳細表示していきたいと思います。
「pandas」というのは、Pythonデータサイエンティストであれば必ず使うであろうデータ分析・解析ツールです。
分析・解析だけでは無く、データをクリーニング、つまり整えてから機械学習や深層学習にデータを学習させます。
まさに「痒い所に手が届く」といった高機能なツールとなります。
そんなpandasですが、有難いことに「django-pandas」というDjangoのクエリを簡単に読み込むことができ、容易に分析・解析ができるツールとして登場していました。
開発してくれた方にはとても感謝です。
そして人工知能に興味がある方などは手始めとして導入してみてはいかがでしょうか?
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsytem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
| 使用ライブラリ | ライセンス |
|---|---|
| Django==3.1 | BSD |
| django-cleanup==5.0.0 | MIT |
| django-pandas==0.6.2 | BSD |
プロジェクトの概要¶
Djangoはインストール済みとして、必要なライブラリをインストールします。
ちなみに、使用ライブラリ中にある「django-cleanup」は、Djangoのフォーム画面にて削除・更新されたファイルの相対パスに存在しているファイル自体も一緒に削除してくれるツールです。
$ pip install django-cleanup django-pandas
config/settings.py¶
「settings.py」では以下のように設定します。
# config/settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'django_cleanup.apps.CleanupConfig', # 設定
'django_pandas', # 設定
'app.apps.AppConfig', # アプリ名
]
...
STATIC_URL = '/static/'
# mediaファイルの設定(開発環境)
import os
MEDIA_URL = '/media/'
MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
config/urls.py¶
settings.pyと同じ階層にある「urls.py」の設定です。
# config/urls.py
from django.contrib import admin
from django.urls import path, include
from django.conf import settings
from django.conf.urls.static import static
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('app.urls')),
]
# 開発環境での設定
if settings.DEBUG:
urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
app/models.py¶
アプリディレクトリ内の「models.py」の設定です。
データベースのテーブルであるモデルは以下のようになります。
# app/models.py
from django.db import models
from django.core.validators import FileExtensionValidator
import os
class FileUpload(models.Model):
"""
ファイルのアップロード
"""
title = models.CharField(default='CSVアフィル', max_length=50)
upload_dir = models.FileField(upload_to='csv', validators=[FileExtensionValidator(['csv',])])
created_at = models.DateField(auto_now_add=True)
def __str__(self):
return self.title
def file_name(self):
"""
相対パスからファイル名のみを取得するカスタムメソッド
"""
path = os.path.basename(self.upload_dir.name)
return path
「FileExtensionValidator」は指定したファイルのみを受け付けるといった制御を行う機能です。
ここではCSVファイルのみをアップロードできるようにしています。
app/admin.py¶
管理画面での操作を行う為にアプリディレクトリ内の「admin.py」を設定します。
# app/admin.py
from django.contrib import admin
from .models import FileUpload
admin.site.register(FileUpload)
app/urls.py¶
アプリディレクトリ内の「urls.py」を設定します。
ここではプロジェクト内で設定したURLから始まるURLパターンを設定します。
# app/urls.py
from django.urls import path
from . import views
app_name = 'app'
urlpatterns = [
path('', views.index, name='index'),
]
app/views.py¶
テンプレートファイルで表示させるために、アプリディレクトリ内の「views.py」を設定します。
# app/views.py
from django.shortcuts import render
from .models import FileUpload
def index(request):
"""
トップページ
"""
file_obj = FileUpload.objects.all()
context = {
'file_obj': file_obj,
}
return render(request, 'app/index.html', context)
templates/ app/index.html¶
テンプレートファイルの「index.html」は以下のようになります。
<!-- app/templates/app/index.html -->
<!doctype html>
<html>
<head>
<title>テストアプリ</title>
</head>
<body>
<h2>CSVファイルリスト</h2>
<br>
{% if file_obj %}
{% for file in file_obj %}
<p>
{{ file.created_at }}
{{ file.title }}
<a href="#">詳細</a>
</p>
{% endfor %}
{% else %}
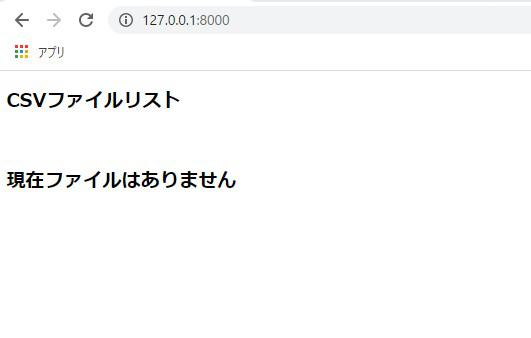
<h2>現在ファイルはありません</h2>
{% endif %}
</body>
</html>
migration¶
マイグレーションを実行しデータベースに反映させ、管理者として登録します。
$ python3 manage.py makemigrations app
$ python3 manage.py migrate app
$ python3 manage.py createsuperuser
「runserver」コマンドを実行すると、トップページは以下のようになります。
詳細ページの設定¶
では詳細ページにてCSVファイルの中身をテーブル形式で表示するための設定を行っていきます。
django-pandasをsettings.pyに設定していることを確認してから記述していきます。
app/urls.py(詳細ページ設定)¶
最初にURLパターンを設定します。
# app/urls.py
from django.urls import path
from . import views
app_name = 'app'
urlpatterns = [
path('', views.index, name='index'),
path('detail/<int:pk>/', views.detail, name='detail'), # 追記
]
app/views.py(詳細ページ設定)¶
ここから「django-pandas」を使用して、FileUploadモデルに保存されているファイルを読み込みます。
FileUploadモデル内には実際にファイルは保存されていないので、そのファイルまでのパスである絶対パスを渡します。
# app/views.py
from django.shortcuts import render, get_object_or_404 # 追記
from .models import FileUpload
from django_pandas.io import pd # 追記
...
def detail(request, pk):
"""
詳細ページ
"""
file_value = get_object_or_404(FileUpload, id=pk)
df = pd.read_csv(file_value.upload_dir.path, index_col=0)
context = {
'file_value': file_value,
'df': df,
}
return render(request, 'app/detail.html', context)
「from django_pandas.io import pd」の「pd」というのは、pandasをインポートして利用する際に用いられる型です。
そしてpdから「read_csv」属性を使用することで、CSVファイルをデータフレーム形式として読み込む事ができます。
データフレームとは以下のよう形です。
id name
0 1 A
1 2 B
2 3 C
read_csvに渡している「file_value.upload_dir.path」では、そのファイルの置かれている絶対パスを取得しています。
「index_col=0」は単に余分な枠を除外しているだけです。
templates/ app/detail.html(詳細ページ設定)¶
テンプレートファイルの「detail.html」を新規作成し、以下のように記述します。
<!-- app/templates/app/detail.html -->
<!doctype html>
<html>
<head>
<title>テストアプリ</title>
</head>
<body>
<h2>CSVファイル</h2>
<br>
<a href="{% url 'app:index' %}">戻る</a>
<br>
<!-- 各インスタンス属性の要素を取得 -->
<p>アップロード日:{{ file_value.created_at }}</p>
<p>ダウンロード:<a href="{{ file_value.upload_dir.url }}">{{file_value.file_name }}</a></p>
<br>
<!-- 読み込んだCSVファイルをテーブル形式で表示 -->
<table border="1">
<tr>
<td>index</td>
{% for columns, item in df.iteritems %}
<th>{{ columns }}</th>
{% endfor %}
</tr>
{% for index, rows in df.iterrows %}
<tr>
<th>{{ index }}</th>
{% for row in rows %}
<td>{{ row }}</td>
{% endfor %}
</tr>
{% endfor %}
</table>
</body>
</html>
tableタグ内では、「df.iteritems」や「df.iterrows」とすることで中身の要素を一つずつ取り出すことができます。
どのような処理となっているか簡単に見ていきます。
$ python3 manage.py shell
>>>
>>> # pdとしてインポート
>>> from django_pandas.io import pd
>>>
>>> # 辞書内の要素はリスト形式として変数に格納
>>> value_dict = {
... 'A': [1, 2, 3, 4],
... 'B': [5, 6, 7, 8],
... 'C': [9, 10, 11, 12]
... }
>>>
>>> value_dict
{'A': [1, 2, 3, 4], 'B': [5, 6, 7, 8], 'C': [9, 10, 11, 12]}
>>>
>>> # 辞書からデータフレームに変換
>>> df = pd.DataFrame(value_dict)
>>>
>>> # 中身を確認
>>> # ヘッダーである列名トップ’A, B, C'はカラム
>>> # 行番号はインデックス
>>> df
A B C
0 1 5 9
1 2 6 10
2 3 7 11
3 4 8 12
>>>
>>> # iteritems属性で各カラムを取り出す
>>> for columns, item in df.iteritems():
... print(columns)
... print('---------')
... print(item)
... print('---END---')
...
A
---------
0 1
1 2
2 3
3 4
Name: A, dtype: int64
---END---
B
---------
0 5
1 6
2 7
3 8
Name: B, dtype: int64
---END---
C
---------
0 9
1 10
2 11
3 12
Name: C, dtype: int64
---END---
>>>
>>> # 再度中身を確認
>>> df
A B C
0 1 5 9
1 2 6 10
2 3 7 11
3 4 8 12
>>>
>>> # iterrows()属性でインデックス番号並びに各行を取り出す
>>> for index, rows in df.iterrows():
... print(index)
... print('--------')
... print(rows)
... print('----NEXT----')
... for row in rows:
... print(row)
... print('-----END-----')
...
0
--------
A 1
B 5
C 9
Name: 0, dtype: int64
----NEXT----
1
-----END-----
5
-----END-----
9
-----END-----
1
--------
A 2
B 6
C 10
Name: 1, dtype: int64
----NEXT----
2
-----END-----
6
-----END-----
10
-----END-----
2
--------
A 3
B 7
C 11
Name: 2, dtype: int64
----NEXT----
3
-----END-----
7
-----END-----
11
-----END-----
3
--------
A 4
B 8
C 12
Name: 3, dtype: int64
----NEXT----
4
-----END-----
8
-----END-----
12
-----END-----
>>>
>>> quit()
これまでの処理を見て、テンプレートファイル内のtableタグで何が行われているのかが直感的に理解できたと思います。
他にも、クエリセットをそのままデータフレームに変換しCSVファイルとして作成した「django-pandas」の方法が以下の記事で紹介しているので興味がある方はご覧ください。
templates/ app/index.html(詳細ページ設定)¶
「index.html」にて詳細ページに移動するためのリンクを設定します。
<!-- app/templates/app/index.html -->
<!doctype html>
<html>
<head>
<title>テストアプリ</title>
</head>
<body>
<h2>CSVファイルリスト</h2>
<br>
....
<p>
{{ file.created_at }}
{{ file.title }}
<a href="{% url 'app:detail' pk=file.id %}">詳細</a>
</p>
....
</body>
</html>
CSVファイルの読み込み&エラー対策¶
それではさっそく、CSVファイルをアップロードして詳細ページで表示してみます。
アップロードして読み込む¶
アップロードするCSVファイルは以下のWebサイトから入手できます。
これらのサイトはデータウェアハウスなどと呼ばれ、データの分析や解析をするためのデータセット(統計データなど)をリリースして下さっています。
規約事項なども読んでおくと良いかもしれません。
Kaggleについての詳細はこちらの記事で紹介しているので興味のある方はご覧ください。
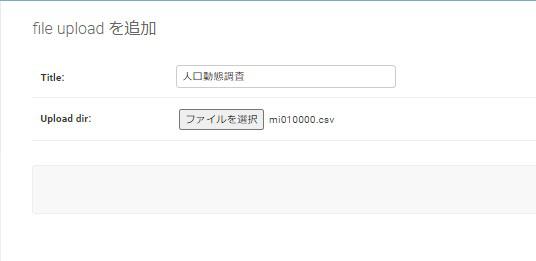
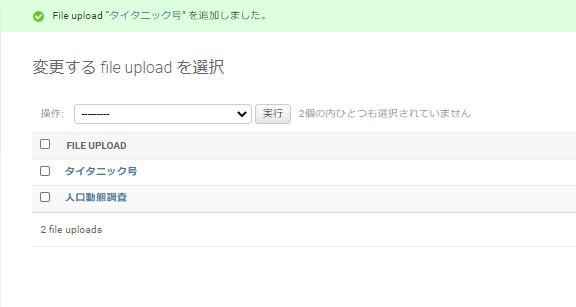
CSVファイルが見つかりましたら、管理画面にて幾つかアップロードをします。
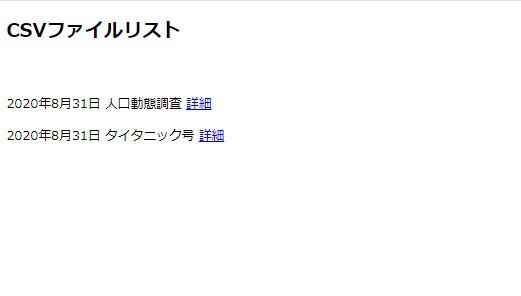
トップページへ移動し、表示されているか確認してみます。
それでは先に、Kaggleから入手したタイタニック号というタイトルのCSVファイル詳細を開いてみます。
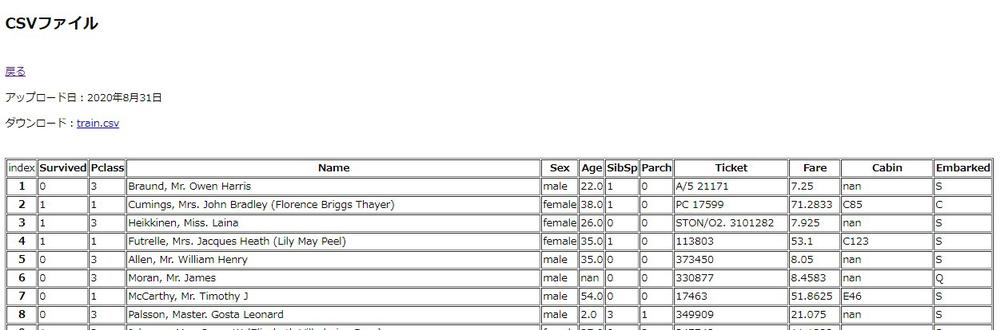
上手く読み込んで各セルにしっかり当てはまっています。
エラー対策¶
もう一方の人口動態調査というCSVファイルを開いてみます。
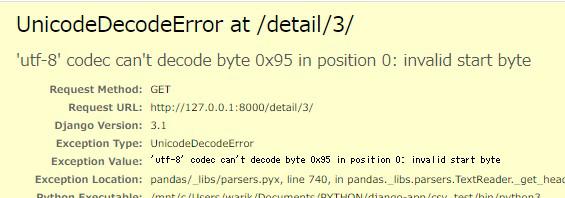
こちらのページでは、「'utf-8' codec can't decode byte 0x95 in position 0: invalid start byte」というエラーが発生しました。
pandasのread_csvでの読み込み時のユニコードはデフォルトで「utf-8」という世界標準の統一規格となっています。
例えばWindowsのエクセルなどで作成されるファイルは、「shift_jis」や「cp932」というユニコードで作成されるため、その規格で読み込まない限り出力できないといったことがあります。
読み込もうとした「人口動態調査」のファイルは恐らくエクセルから作成された規格なので、それに対応したユニコードを指定する必要があります。
つまりshift_jisやcp932で作成されたファイルはshift_jisかcp932で読み込むのです。
ここでは割と対応確率の高い「cp932」を設定していきたいと思います。
では、「views.py」を編集します。
# app/views.py
from django.shortcuts import render, get_object_or_404
from .models import FileUpload
from django_pandas.io import pd
...
def detail(request, pk):
"""
詳細ページ
"""
file_value = get_object_or_404(FileUpload, id=pk)
try:
# utf-8に対応
df = pd.read_csv(file_value.upload_dir.path, index_col=0)
except UnicodeDecodeError:
# cp932に対応
df = pd.read_csv(file_value.upload_dir.path, index_col=0, encoding='cp932')
context = {
'file_value': file_value,
'df': df,
}
return render(request, 'app/detail.html', context)
ではエラーとなっていた「人口動態調査」の詳細ページをリロードしてみます。
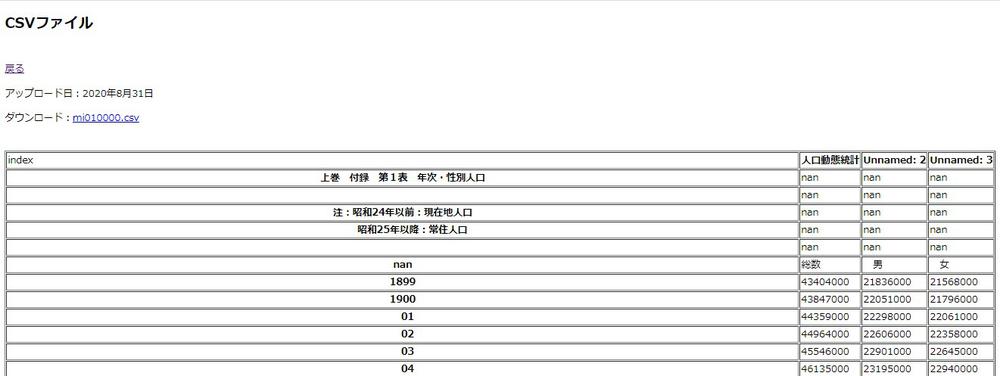
上手く読み込むことができました。
気になったデータセットなどをアップロードして、いつでも取り出せるようなファイル管理アプリとして開発していくのも面白そうですね。
それでは以上となります。
最後までご覧いただきありがとうございました。