【Python】文字コードを把握してEncode(エンコード)・Decode(デコード)エラーを回避する
投稿日 2020年9月20日 >> 更新日 2023年3月1日
今回はPythonにまつわるEncode(エンコード)・Decode(デコード)エラーについて説明していきたいと思います。
エンコード・デコードのエラーが起こる理由としては、Pythonで扱われている文字列などの内部表現(データ型)と、ファイル入出力や外部データの取得をする際の外部との表現が異なった時に「UnicodeEncodeError」や「UnicodeDecodeError」が吐き出されます。
Encode・Decodeの意味や処理内容をしっかり理解することにより簡単に防ぐことができるので、実装例などを踏まえて回避できるようにしていきましょう。
実行環境¶
| 実行環境 |
|---|
| Windows Subsystem for Linux Ubuntu |
| Python 3.6.9 |
エンコード・デコードとは¶
まずそれぞれの意味は以下のようになります。
-
Encode(エンコード)
文字列(テキスト)をバイト列に変換する(符号化する) -
Decode(デコード)
バイト列を文字列(テキスト)に戻す(復号する)
この工程は主に、ファイル入出力や外部データを扱う際に行われています。
バイト(byte)列とは文字一つ一つの情報量の単位であり、その情報量の最小単位はビット(bit)となります。
つまり文字一つ一つに数バイトのメモリ領域が使用されています。
そして文字列をバイト列に表現させる変換器の1つに「UTF-8」という文字コードがあります。
Pythonではデフォルトエンコーディングとして「UTF-8」が定められています。
※実行しているPCの言語環境によって異なるかもしれません
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'
文字コードとは、文字との対応関係にあるデータ型への変換器ですが、深掘りし過ぎると混乱してしまう可能性があるので、簡単に説明していきます。
文字コードとは¶
文字コードとは文字とデータ型の対応関係を表す手段に使われていますが、文字コード内においても様々な規格や実装手段があります。
Pythonの例でいうと、コンピュータが文字列や記号を処理できる手段として「Unicode」と「UTF-8」という組み合わせで文字コードを使用しています。
これらは実は別々のタイプで、それぞれ「符号化文字集合」と「文字符号化方式」に分けられます。
UnicodeとUTF-8を混同してしまう事がありますが以下のようなカテゴリーで文字コードは分けられます。
| 符号化文字集合 |
|---|
| Unicode |
| JIS X 0213 |
| その他 |
| 文字符号化方式 |
|---|
| UTF-8 |
| UTF-16 |
| UTF-32 |
| ASCII |
| Shift-JIS |
| cp932 |
| その他 |
基本的にPythonはUnicode標準として文字列を表現しているため、どのような文字符号化方式を利用しているかがカギとなります。
符号化文字集合という規格に合わせて、文字符号化方式でバイト列に変換させます。
では符号化文字集合と文字符号化方式をそれぞれ簡単に実装していきたいと思います。
Unicode(符号化文字集合)¶
PythonではUnicode標準の符号化文字集合がサポートされており、文字列や記号などはUnicode文字列として表示されます。
>>> 'あ'
'あ'
Unicodeは世界中のあらゆる文字や記号が収録されている文字集合で、殆どのプログラムやアプリで利用されいます。
先ほど「あ」というUnicode文字を表示しましたが、「あ」という文字にはコンピュータが処理を行えるように番号(符号)が割り当てられています。
この割り当てられている番号を「コードポイント」と言います。
Python組み込み関数のord()メソッドの引数に、文字を当てはめるとコードポイントを取得することができます。
>>> ord('あ')
12354
人間が普段使用している10進数での表記12354は、Unicodeで定められている「あ」という文字のコードポイントです。
コードポイントから文字を取得すには、chr()メソッドの引数に整数を与えます。
>>> chr(12354)
'あ'
>>> chr(ord('あ'))
'あ'
Pythonやその他プログラムでは10進記法が標準なので、2進数・8進数・16進数の値を取得するには、以下の組み込み関数を使用します。
>>> _2 = bin(ord('あ'))
>>> _8 = oct(ord('あ'))
>>> _10 = ord('あ')
>>> _16 = hex(ord('あ'))
>>>
>>> print('2進数表記:{}\n8進数表記:{}\n10進数表記:{}\n16進数表記:{}'.format(
... _2,
... _8,
... _10,
... _16
... ))
2進数表記:0b11000001000010
8進数表記:0o30102
10進数表記:12354
16進数表記:0x3042
10進以外の各記数法のプレフィックス(頭文字)には「0b」「0o」「0x」などと付与されいて、Pythonではその当てはまる記数を表しています。
それぞれの値を直接入力すると10進整数が返されます。
>>> print(0b11000001000010, 0o30102, 0x3042)
12354 12354 12354
ドキュメントやエラーログには16進数表記で表されることがあるので、覚えておくと助けになると思います。
結果的に符号化文字集合は、コードポイントと文字の対応関係をコンピュータ上で表現をする文字コードの1つということになります。
そして符号化文字集合においてコンピュータの情報量を表現するバイト列への変換が文字符号化方式となります。
文字符号化方式¶
文字符号化方式は、文字符号化スキーム・文字エンコーディング方式とも言って、文字列をバイト列に変換(符号化)させる文字コードの1つです。
符号化文字集合によって使用される文字符号化方式は異なりますが、PythonはUnicode標準の符号化文字集合をベースとしたUTF-8という文字符号化方式をデフォルトで採用されています。
UTF-8は「Unicode Transformation Format-8」と言って、Unicodeの符号を8ビット単位で表す1~4バイトの可変長です。
特徴としては、最も多く使用されている文字コードの「ASCII」と互換性があり、1バイトの文字に対する符号は同じバイト列が使われています。
Python組み込みの文字列メソッドencode()を使用して文字列からバイト列に符号化してみます。
「a」という文字列に対してエンコードを実行します。
>>> 'a'.encode() # デフォルトエンコーディングはUTF-8
b'a'
>>>
>>> 'a'.encode(encoding='ascii')
b'a'
文字列の外の最初に「b」が付与されている場合は、Python内部においてバイト列として表現されます。
len()の引数にバイト列を与えると、バイト数を取得できます。
>>> len(b'a')
1
そして冒頭でも言いましたが、PythonはデフォルトエンコーディングとしてUTF-8を使用しているので、引数に文字コード(文字符号化方式)を指定しない限りデフォルト値で符号化し、復号します。
UTF-8とASCIIのバイト列が文字列「a」に対して同じ「b'a'」ですが、先ほど言った特徴の1つです。
UTF-8はASCII文字列との互換性を保って作成されていることもあり、1バイトまでの0~127番目の文字列に対しては同じバイト列で表現されます。
なぜ0~127番目なのか?
ASCIIは7ビット単位で128個の文字(アルファベット・記号など)を収録している文字コードだからです。
コンピュータの情報量における基本最小単位はビットで、1ビットでコンピュータが処理できる範囲は「0」か「1」の2通り、つまり2進数の世界です。
コンピュータは0か1の2進数によって何かを表現するので2進数の0だったら10進数で言われる「0」、2進数の1だったら10進数で言われる「1」、10進数で言われる「2」の表現は2進数では桁上がりして2ビット整数となるので2進数1と0の組み合わせ(10)だったら10進数で言われる「2」に当たります。
# 1ビット
0 = 0
1 = 1
# 2ビット
00 = 0
01 = 1
10 = 2
11 = 3
# 3ビット
000 = 0
001 = 1
010 = 2
011 = 3
100 = 4
101 = 5
110 = 6
111 = 7
1ビットでは2通り、2ビットでは4通り、3ビットでは8通りというふうにビット数を増やすことにより指数関数的に表現できる範囲が増えます。
1~7ビットでは以下の通り分、表現が出来るようになります。
>>> bit = range(1, 8)
>>> num = 1
>>>
>>> for i in bit:
... num *= 2
... print('{}ビット:{}通り'.format(i, num))
...
1ビット:2通り
2ビット:4通り
3ビット:8通り
4ビット:16通り
5ビット:32通り
6ビット:64通り
7ビット:128通り
>>>
ASCIIは7ビット単位で収録されているので128通りの表現が可能ですが、10進数においてのプログラムは基本的に0から始まり、0〜127までの表現が可能ということになります。
各ビットの最後の2進数は1の羅列で終わり桁上がりしていました。
それぞれのビット数の末尾を2進数に変換してみます。
>>> num = [1, 3, 7, 15, 31, 63, 127]
>>>
>>> for index, i in enumerate(num, 1):
... print('{}ビット == 2進数末尾:{}'.format(index, bin(i)))
...
1ビット == 2進数末尾:0b1
2ビット == 2進数末尾:0b11
3ビット == 2進数末尾:0b111
4ビット == 2進数末尾:0b1111
5ビット == 2進数末尾:0b11111
6ビット == 2進数末尾:0b111111
7ビット == 2進数末尾:0b1111111
組み込み関数のbin()メソッドに10進整数を与えるとプレフィックスが「0b」の2進数が返されました。
文字コードの話題から少し離れてしまいましたが、ASCIIは0〜127番までの整数で英語圏の文字(アルファベットや記号)を1バイトで表現します。
そしてUTF-8はASCIIコードとの互換性を保つために、0〜127の1バイトまではASCIIと同様の表現をし、127以降は2バイト、3バイトといった可変長で文字をエンコードしていきます。
では試しに120〜130の文字をASCIIとUTF-8でエンコーディングして比べてみます。
>>> number = range(120, 131)
>>>
>>> for i in number:
... print(i, '文字:{} = ASCII:{}:{}バイト = UTF-8:{}:{}バイト'.format(
... chr(i),
... chr(i).encode('ascii', errors='replace'),
... len(chr(i).encode('ascii', errors='replace')),
... chr(i).encode(),
... len(chr(i).encode())
... ))
...
120 文字:x = ASCII:b'x':1バイト = UTF-8:b'x':1バイト
121 文字:y = ASCII:b'y':1バイト = UTF-8:b'y':1バイト
122 文字:z = ASCII:b'z':1バイト = UTF-8:b'z':1バイト
123 文字:{ = ASCII:b'{':1バイト = UTF-8:b'{':1バイト
124 文字:| = ASCII:b'|':1バイト = UTF-8:b'|':1バイト
125 文字:} = ASCII:b'}':1バイト = UTF-8:b'}':1バイト
126 文字:~ = ASCII:b'~':1バイト = UTF-8:b'~':1バイト
127 文字: = ASCII:b'\x7f':1バイト = UTF-8:b'\x7f':1バイト
128 文字: = ASCII:b'?':1バイト = UTF-8:b'\xc2\x80':2バイト
129 文字: = ASCII:b'?':1バイト = UTF-8:b'\xc2\x81':2バイト
130 文字: = ASCII:b'?':1バイト = UTF-8:b'\xc2\x82':2バイト
encode()メソッドの引数に「errors=replace」を指定すると、エンコーディングに指定した文字コードではエンコードできない文字のバイト列を「?」に置き換えます。
つまりUTF-8は127番目まではASCIIと同じ表現をし、それ以降はマルチバイトシーケンスとして収録されている文字に対してのバイト列を返しています。
UTF-8以外の文字符号化方式ではどのようなバイト列となるのか見てみます。
>>> encoder = ['utf-8', 'utf-16', 'utf-32', 'ascii', 'shift-jis', 'cp932']
>>>
>>> for code_name in encoder:
... byte = 'あ'.encode(encoding=code_name, errors='replace')
... print('{} = {} = {}バイト'.format(code_name, byte, len(byte)))
...
utf-8 = b'\xe3\x81\x82' = 3バイト
utf-16 = b'\xff\xfeB0' = 4バイト
utf-32 = b'\xff\xfe\x00\x00B0\x00\x00' = 8バイト
ascii = b'?' = 1バイト
shift-jis = b'\x82\xa0' = 2バイト
cp932 = b'\x82\xa0' = 2バイト
「あ」の一文字を取っても文字符号化方式によってバイト列が異なっています。
ASCIIは英語圏の文字や記号しか収録されていないので127以降の文字は「errors=replace」によって「?」に置き換えられています。
「Shift-JIS」や「cp932」はASCIIを拡張させた日本語対応の文字符号化方式なので、「あ」に対しては同じバイト列を返しています。
が
「UTF-8」「UTF-16」「UTF-32」では符号化する規則が違うので、それぞれ異なるバイト列を表現しています。
これまでエンコードという文字列からバイト列に符号化していきましたが、逆の作業であるデコードでバイト列から文字列へ戻すという復号化を実装してみます。
復号化の実装はバイト列型メソッドであるdecode()によって行うことができます。
>>> 'あ'.encode() # バイト列へエンコード
b'\xe3\x81\x82'
>>>
>>> b'\xe3\x81\x82'.decode() # 文字列へデコード
'あ'
>>> 'あ'.encode('shift-jis') # 文字符号化方式をShift-JISにしてエンコード
b'\x82\xa0'
>>>
>>> b'\x82\xa0'.decode('shift-jis') # Shift-JISのバイト列に対して文字符号化方式をShift-JISにしてデコード
'あ'
>>>
エンコードとデコードの工程は同じ文字符号化方式を利用してUnicode文字列として表現することができます。
異なる文字符号化方式のエンコードとデコードを行うとどのような結果となるか確かめてみます。
>>> shift_jis_b = 'abcあ'.encode('shift-jis')
>>>
>>> print(shift_jis_b) # バイト列を出力
b'abc\x82\xa0'
>>>
>>> print(len(shift_jis_b)) # バイト数を出力
5
>>>
>>> shift_jis_b.decode() # デフォルトのUTF-8でデコード
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x82 in position 3: invalid start byte
「'utf-8' codec can't decode byte 0x82 in position 3: invalid start byte」というUnicodeDecodeErrorが検出されました。
これは外部ファイルの読み込み時に良く起こるエラーです。
内容は「バイト列の3番目の要素から始まるバイト値0x82はUTF-8では無効です」との事です。
プログラムは0から数え上げるので、0から2番目の「abc」要素はUTF-8でもデコードできましたが、それ以降からの3番目は無効な開始バイトとなります。
最初のバイト値0x82は16進数表記、つまりバイト列で表すと「\x82」となります。
>>> 0x82 # 16進整数
130
>>>
>>> chr(130) # コードポイントをUnicode文字に変換
'\x82'
Shift-JISにてエンコードを行ったので、デコードにおいてもShift-JISを指定してあげれば問題無くUnicode文字列として戻すことができます。
>>> shift_jis_b.decode('shift-jis')
'abcあ'
もしくわエンコードを行った文字コードを無視して、異なる文字コードで無理矢理デコードしたい場合は引数の「errors」エラーハンドリングを指定します。
Python公式ドキュメント --codecs エラーハンドラ
>>>
>>> shift_jis_b.decode(errors='replace') # 無効なバイト列を?に置き換える
'abc��'
>>>
>>> shift_jis_b.decode(errors='ignore') # 無効なバイト列を除外する
'abc'
>>>
>>> shift_jis_b.decode(errors='backslashreplace') # 無効なバイト列にバックスラッシュを添える
'abc\\x82\\xa0'
>>>
>>> shift_jis_b.decode(errors='surrogateescape') # サロゲート領域の代理バイト列に置き換える
'abc\udc82\udca0'
文字コードを深掘りしていくと複雑で混乱してしまい勝ちですが、符号化文字集合や文字符号化方式はそれぞれ決まった役割があり、組み合わせることによってコンピュータが文字を表現することが出来ています。
エンコードとデコードの工程が分かったところで、外部ファイルの入出力を実装してみたいと思います。
外部ファイルの読み込み・書き込み¶
Pythonではファイルを読み込んだり書き込んだりする際に、文字コードをUTF-8にエンコーディングしています。
ファイルの操作は組み込み関数の「open()」で開くことができます。
デフォルトでは
open(file, mode='r', encoding=None, uffering=-1, errors=None, newline=None, closefd=True, opener=None)
となっていて基本的に良く操作する引数は「file、mode、encoding」となります。
ひとまずテキストファイルを書き込みモードで選択して開いて保存してみます。
>>> with open(file='text.txt', mode='wt') as file:
... file.write('abcあいう')
...
6
書き込みモード「mode='wt'」でファイルを開き暗黙ではUTF-8の文字コードとなります。
なので読み込み時では何も気にせずファイルを開いて中身を取得するこができます。
>>> with open('text.txt') as file:
... text_file = file.read()
...
>>> text_file
'abcあいう'
ファイルには「txt、csv、excel、pdf」と様々なものがありますが、それぞれハードディスクのメモリに保存する際は文字符号化方式を指定しています。
※以下はWindowsの場合
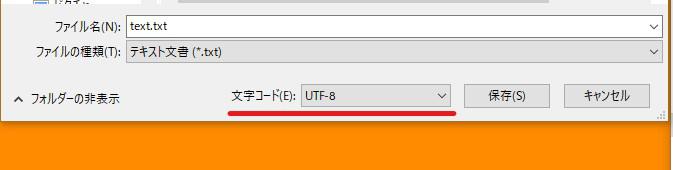
幾つかのファイル形式を選ぶことができますが、「ANSI」を指定し再度同じファイル名で保存してみます。
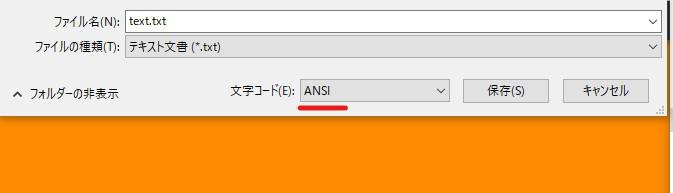
ANSIは「American National Standards Institute」の略で、米国国家規格協会で定めらている文字コードです。
先ほどと同じような要領でテキストファイルを読み込んでみます。
>>> with open('text.txt') as file:
... ansi_file = file.read()
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
File "/usr/lib/python3.6/codecs.py", line 321, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x82 in position 3: invalid start byte
何かしらの文字コードでエンコードされているバイト列と、デフォルトのUTF-8で収録されているバイト列が異なるのでデコードできなくなりました。
テキストファイルの文字コードが分かればエンコーディングに文字コードを指定すればいいのですが、分からない場合は以下のような方法を使います。
Python標準モジュールの「subprocess」を使用してテキストファイルの文字コードを調べます。
私の場合はUbuntuターミナルを使用しているので、subprocess.run()メソッドにLinuxコマンドを与えます。
>>> import subprocess
>>>
>>> # 文字コードを確認
>>> subprocess.run(['file', 'text.txt'])
text.txt: Non-ISO extended-ASCII text, with no line terminators
CompletedProcess(args=['file', 'text.txt'], returncode=0)
>>>
>>> # テキストの中身を確認
>>> subprocess.run(['cat', 'text.txt'])
abc
CompletedProcess(args=['cat', 'text.txt'], returncode=0)
>>>
>>> # バイト数を確認
>>> subprocess.run(['du', '-b', 'text.txt'])
9 text.txt
CompletedProcess(args=['du', '-b', 'text.txt'], returncode=0)
>>>
文字コードはASCII規格だということは分かりましたが、テキストの中身を見ると3文字のアルファベットが記されているので3バイトであるという事が分かります。
ですがバイト数を確認してみると9バイトとなっているので、UTF-8で無効なバイト列はエスケープされていることが分かります。
これらの情報から、ASCIIを日本語に対応させた拡張版の「Shift-JIS」もしくわ「cp932」の文字コードでファイルをデコードすれば、中身を取得できるということが分かりました。
>>> with open('text.txt', encoding='shift-jis') as file:
... ansi_file = file.read()
...
>>>
>>> print(ansi_file)
abcあいう
他の方法としては、open()メソッドの引数にエラーハンドリング「errors」を指定する方法です。
「errors='ignore'」の場合
>>> with open('text.txt', errors='ignore') as file:
... ansi_file = file.read()
...
>>>
>>> print(ansi_file)
abc
UTF-8でデコードできないバイト列は除外されます。
「errors='replace'」の場合
>>> with open('text.txt', errors='replace') as file:
... ansi_file = file.read()
...
>>> print(ansi_file)
abc������
UTF-8でデコードできないバイト列は「?」に置き換えられます。
「errors='backslashreplace」の場合
>>> with open('text.txt', errors='backslashreplace') as file:
... ansi_file = file.read()
...
>>> print(ansi_file)
abc\x82\xa0\x82\xa2\x82\xa
バックスラッシュ付きのエスケープシーケンスに置き換えられます。
「errors='surrogateescape'」の場合
>>> with open('text.txt', errors='surrogateescape') as file:
... ansi_file = file.read()
...
>>> print(ansi_file)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'utf-8' codec can't encode characters in position 3-8: surrogates not allowed
サロゲート領域のバイト列に置き換えられますが、UTF-8では許可されていなのでエンコードできていません。
文字列はどうなっているかというと以下のように置き換えられています。
>>> ansi_file
'abc\udc82\udca0\udc82\udca2\udc82\udca4'
このバイト列は一時的に置き換えられているに過ぎないので、もう一度エラーハンドリングに「surrogateescape」を与えると元のエンコードされているバイト列に戻すことができます。
>>> ansi_file.encode(errors='surrogateescape')
b'abc\x82\xa0\x82\xa2\x82\xa4'
とりあえずファイル内を編集したい場合に使用するのが便利です。
>>> ansi_file += 'defg'
>>>
>>> with open('text.txt', mode='wt', errors='surrogateescape') as file:
... file.write(ansi_file)
...
13
>>>
>>> import subprocess
>>>
>>> subprocess.run(['file', 'text.txt'])
text.txt: Non-ISO extended-ASCII text, with no line terminators
CompletedProcess(args=['file', 'text.txt'], returncode=0)
>>>
>>> subprocess.run(['cat', 'text.txt'])
abcdefg
CompletedProcess(args=['cat', 'text.txt'], returncode=0)
>>>
>>> subprocess.run(['du', '-b', 'text.txt'])
13 text.txt
CompletedProcess(args=['du', '-b', 'text.txt'], returncode=0)
再度エンコーディングの文字コードを指定すると、ファイル内のすべてを取得できます。
>>> with open('text.txt', encoding='shift-jis') as file:
... ansi_file = file.read()
...
>>> print(ansi_file)
abcあいうdefg
書き込み時は、これから作業を行うプログラムの文字コードに合わせて保存します。
>>> with open('text.txt', mode='wt') as file:
... file.write(ansi_file)
...
10
>>>
>>> import subprocess
>>>
>>> subprocess.run(['file', 'text.txt'])
text.txt: UTF-8 Unicode text, with no line terminators
CompletedProcess(args=['file', 'text.txt'], returncode=0)
>>>
>>> subprocess.run(['cat', 'text.txt'])
abcあいうdefg
CompletedProcess(args=['cat', 'text.txt'], returncode=0)
>>>
>>> subprocess.run(['du', '-b', 'text.txt'])
16 text.txt
CompletedProcess(args=['du', '-b', 'text.txt'], returncode=0)
実装は以上です。
今回はEncode・Decodeエラーを回避する上での文字コードについて説明してきましたが、まだまだ説明を怠っている事や、混乱を招くような内容が多々あったかと思います。
色々な専門用語や文字コードの規格が入り混じっているので、1つ1つ内容を理解して心置きなく実装していきましょう!
それでは以上となります。
最後までご覧いただきありがとうございました。