【第1回ゼロからブログのデータマイニング】日付と目的データを取得
投稿日 2019年9月29日 >> 更新日 2024年7月9日
今回はブロガーさんによるブロガーさんのための、ブログサイト(Webサイト)の情報を元にゼロからデータマイニングをし、機械学習や深層学習に未来を予測させようといったシリーズ第1回目を書いていこうと思います。
未来を予測させるというのは、何らかの目的(訪問数や閲覧数)を一週間前や一ヶ月前に知っておくということになりますので、機械学習や深層学習に紐解いてもらう為にもこれまでに積み重ねた目的となるデータは必要になります。
また、未来を知ることによってどんなアクションを起こすべきかといった事も考える余裕が生まれてくると思います。
そもそもデータマイニングというのはその名の通り、情報を採掘することであってその採掘された情報がいかに目的へ影響を与えているか、と捉えてもいいと思います。
人間にもそれが言えます。
私たちは過去のデータ(情報)を元に未来を予測しています。
蓄えられた記憶から必要なものだけをピックアップし先のことをイメージします。
このマイニング(採掘)された情報を特徴量と呼んでいます。
しかし、そんな特徴量も増えてくることによって悪影響を及ぼしてくることもあり得ます。
ですので、まずは悪影響を及ぼすまでゼロからマイニングしていこうと思います。
私の実践する環境では、PythonのDjangoフレームワークを使用したWebサイトを元に行います。
データの取得方法は各々違うと思いますので、自身のやり方で取得してください。(Googleアナリティクスのデータ取得方法は説明します)
データのマイニングや解析は共通すると思うので、色々応用できるかと思います。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.8 |
| pip 9.0.1 |
| Jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| Django | BSD |
| Pandas | BSD |
| numpy | OSI Approved (new BSD) |
| matplotlib | PSF |
| Seaborn | BSD |
| scikit-learn | OSI Approved (new BSD) |
目的変数(ターゲット)で使うデータを取得する¶
このサイトを訪問しているかたはチラッと目にしたかもしれませんが、Dataというアプリも立ち上げていて、そこには予め閲覧数を獲得したグラフを過去7日間分プロットしています。
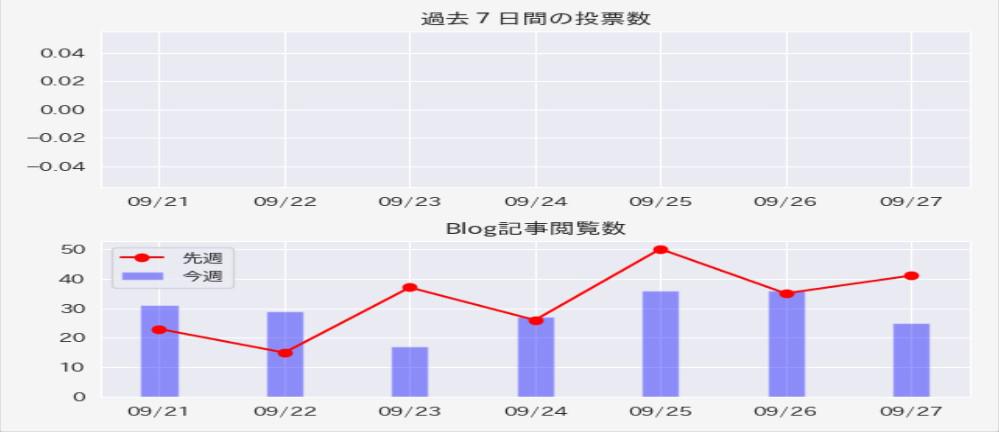
私はこの日のために貯めてあったものを使用しますが、GoogleアナリティクスなどのBIツールを使っている方は、訪問者数などをCSVファイルにしてそれを元にデータを作ります。
そのようなデータが無いという場合は、疑似的にですが後にNumpyを使って生成します。
Googleアナリティクス¶
まずは、Googleアナリティクスから訪問者数を取得する方法です。
画面を開いたら「ユーザーサマリー」をクリックします。
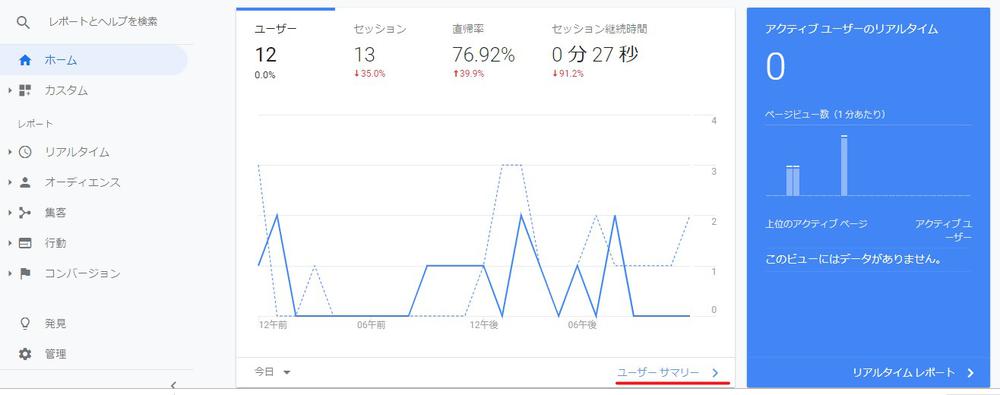
「取得したい日付を指定して、エクスポートをクリックし、CSVを選択します。
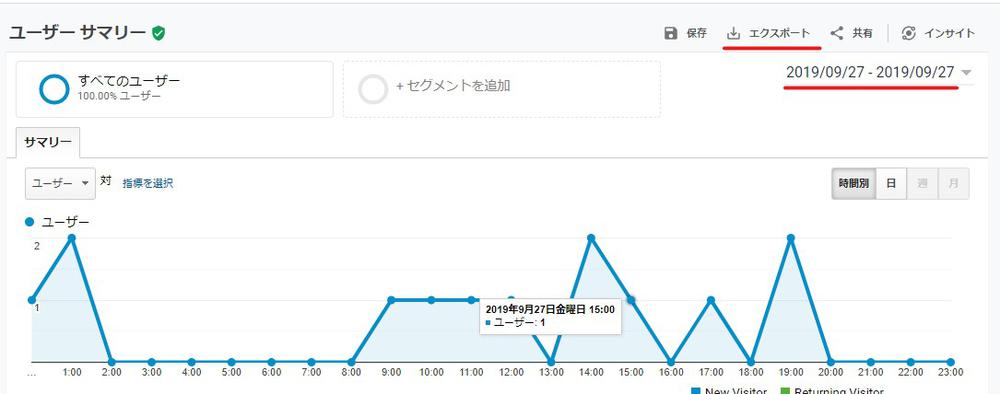
エディタ(メモ帳)形式でファイルを開き余分な部分を削除できたら、準備完了です。

DjangoAPI¶
私は自サイトであるDjangoから目的のデータを取得するので、DjangoAPIを使います。
データをCSVファイルにする際、管理者権限が必要な場合があるので、管理者として実行します。
$ sudo python3.6 manage.py shell
PandasとDjangoのモデルに格納しているテーブルをインポートします。
>>> import pandas as pd
>>> from data.models import BlogData
目的のデータがあるテーブル名を指定して、pandasのデータフレームにしてから変数に格納します。今回は閲覧数と日付を同時に取得します。
>>> df = pd.DataFrame(BlogData.objects.values_list('閲覧数のテーブル'),
.... BlogData.objects.values_list('日付のテーブル'))
>>>
# 最初の10行を取得
>>> df.head(10)
2019-06-24 0
2019-06-25 0
2019-06-26 0
2019-06-27 0
2019-06-28 0
2019-06-29 0
2019-06-30 27
2019-07-01 14
2019-07-02 9
2019-07-03 15
このデータをCSVファイルに納めます。
>>> df.to_csv('sample.csv')
本番環境で「Tera Term」を使用している方に限り、ファイルの転送方法です。
まず先ほど作成したCSVファイルのsample.csvの絶対パスを取得します。
$ find / -name sample.csv
/path/path/sample.csv
絶対パスをコピーし、ターミナル左上のファイル(F)をクリックします。「SSH SCP...」という項目をクリックすると、下図のようになるので、先ほどコピーした絶対パスをFrom:に、移動させたいフォルダTo:を指定し、Receiveをクリックします。
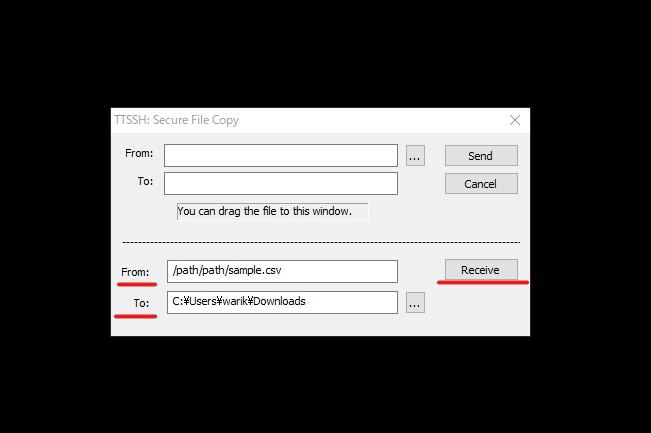
移動させたいフォルダを見ながら実行すると確実です。
Numpyを使用して疑似データを生成¶
疑似データなので全く意味を成さない結果になりますが、疑似体験しておくことも大事です。
なのでサクッとデータを生成してしまいましょう。
まずは必要なライブラリのインポート
import pandas as pd
import numpy as np
import datetime
7月1日から現在辺りまでの日付を生成。
# 実行
"""
日付データ格納用のmonth_day
開始から88日後までカウントするcount_day
"""
month_day = []
count_day = 88
for i in range(count_day):
c = datetime.date(2019, 7, 1)
month_day.append(c+datetime.timedelta(days=i))
"""最終日から10日前のデータを取得"""
month_day[-10:]
[datetime.date(2019, 9, 17),
datetime.date(2019, 9, 18),
datetime.date(2019, 9, 19),
datetime.date(2019, 9, 20),
datetime.date(2019, 9, 21),
datetime.date(2019, 9, 22),
datetime.date(2019, 9, 23),
datetime.date(2019, 9, 24),
datetime.date(2019, 9, 25),
datetime.date(2019, 9, 26)]
次に日付分の疑似データを生成をします。
# 実行
# 1から50までの値をランダムに88個生成する
pseudo = np.random.randint(1, 50, size=88)
pseudo
array([33, 42, 4, 12, 17, 5, 5, 16, 15, 1, 5, 32, 12, 28, 5, 16, 19,
35, 29, 39, 22, 25, 35, 31, 49, 27, 49, 21, 42, 15, 29, 48, 6, 21,
31, 20, 4, 32, 18, 43, 41, 11, 46, 6, 42, 21, 5, 26, 42, 40, 10,
11, 9, 20, 3, 49, 13, 49, 47, 6, 4, 11, 12, 7, 4, 17, 11, 43,
2, 15, 22, 22, 20, 31, 48, 32, 46, 1, 16, 32, 34, 25, 15, 19, 43,
19, 36, 30])
random_seed()とセットで使うことによってランダムで生成された値を再現することができます。
# 実行
# 引数は任意の値を入れる
np.random.seed(1)
np.random.randint(1, 50, size=88)
array([38, 44, 13, 9, 10, 12, 6, 16, 1, 17, 2, 13, 8, 46, 7, 26, 21,
38, 19, 21, 12, 43, 29, 30, 15, 5, 24, 24, 42, 31, 33, 23, 14, 42,
10, 8, 23, 2, 1, 18, 9, 25, 14, 48, 43, 9, 31, 8, 4, 7, 22,
4, 5, 25, 44, 13, 27, 17, 46, 42, 19, 16, 1, 5, 26, 48, 35, 24,
8, 27, 26, 41, 23, 10, 4, 40, 24, 37, 28, 38, 20, 39, 9, 33, 35,
11, 24, 16])
# 実行
# 同じ乱数を生成したい場合
np.random.seed(1)
np.random.randint(1, 50, size=88)
array([38, 44, 13, 9, 10, 12, 6, 16, 1, 17, 2, 13, 8, 46, 7, 26, 21,
38, 19, 21, 12, 43, 29, 30, 15, 5, 24, 24, 42, 31, 33, 23, 14, 42,
10, 8, 23, 2, 1, 18, 9, 25, 14, 48, 43, 9, 31, 8, 4, 7, 22,
4, 5, 25, 44, 13, 27, 17, 46, 42, 19, 16, 1, 5, 26, 48, 35, 24,
8, 27, 26, 41, 23, 10, 4, 40, 24, 37, 28, 38, 20, 39, 9, 33, 35,
11, 24, 16])
これで日付データと疑似データが出来上がりましたので、pandasを使用してデータフレームに格納し、CSVファイルに納めるだけです。
# 実行
month_psed = pd.DataFrame(pseudo, index=month_day)
month_psed.tail(10)
0
2019-09-17 16
2019-09-18 32
2019-09-19 34
2019-09-20 25
2019-09-21 15
2019-09-22 19
2019-09-23 43
2019-09-24 19
2019-09-25 36
2019-09-26 30
# CSVファイルに格納
month_psed.to_csv('sample.csv')
次回へ¶
これで日付と目的のデータを準備することができたので、さっそくマイニング作業へ移りたいと思いますが、第2回目へ預けたいと思います。
Twitterの方で新着記事投稿のお知らせなどをツイートしていますので、最速で受け取りたい方はぜひフォローをして頂ければありがたいです。
最後までご覧いただきありがとうございました。
