【第2回ゼロからブログのデータマイニング】日付から特徴量を生成し、機械学習に流してみる
投稿日 2019年9月30日 >> 更新日 2024年7月9日
前回の第1回目日付データや目的データの取得の続きとなる第2回目では、マイニング作業である特徴量の生成をしていきたいと思います。
特徴量というのは、シンプルに言ってしまうと目的への因果関係を表します。
今回使う目的(予測ターゲット)は前回でもお話しした閲覧数の予測です。
この閲覧数の因果関係となる特徴量をサイト内の情報や他のツール(SNS)などから探し出してそれを分析し機械学習に予測をさせるのですが、今回は時系列データということもあるので、日付から特徴量を作っていきます。
このようなデータを元に月・日・曜日などを各1つのバイナリデータとして作り、相関の無い循環性のあるデータを機械学習の説明変数として学習させてみようと思います。

込み入った話はしませんが、最後には日付データがどれぐらいの予測精度を叩き出してくれるのかを検証して終わりましょう。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.8 |
| pip 9.0.1 |
| Jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| Django | BSD |
| Pandas | BSD |
| numpy | OSI Approved (new BSD) |
| matplotlib | PSF |
| Seaborn | BSD |
| scikit-learn | OSI Approved (new BSD) |
データを確認し必要であれば変更する¶
先ほどの図で今回扱うデータを見ましたが、インデックス(行)が日付順となっています。
pandasのデータフレームを扱う際インデックスのタイプや並び順が統一されていないと、他のデータフレームと上手く結合できないといった問題が起こります。
今回はPython標準の組み込みライブラリであるdatetimeモジュールを使うので、既に用意されているデータ(CSVなど)のインデックスをdatetimeオブジェクトに統一しましょう。
まずはタイプを確認
# 実行
import pandas as pd
df = pd.read_csv('sample.csv', index_col=0)
df.head(7)
ユーザー
日の指標
2019/07/01 7
2019/07/02 6
2019/07/03 6
2019/07/04 2
2019/07/05 3
2019/07/06 2
2019/07/07 4
type(df.index[0])
srt
これはGoogleアナリティクスから取得したデータになるのですが、日付の形式が2019/07/01のようにスラッシュ(/)で区切られています。
こちらをdatetimeモジュールを使って変更します。
# 実行
import datetime
day_num = range(len(df))
time_get = []
for i in day_num:
time_get.append(datetime.date(2019, 7, 1) + datetime.timedelta(days=i))
df.index = time_get
df.head(7)
ユーザー
2019-07-01 7
2019-07-02 6
2019-07-03 6
2019-07-04 2
2019-07-05 3
2019-07-06 2
2019-07-07 4
type(df.index[0])
datetime.date
タイプを見てみるとdatetime.dateとなりましたが、CSVファイルに納めて再度CSVファイルをロードするとstrに戻ります。
ここではわかりやすくGoogleアナリティスクから取得したCSVファイルからの例を説明しましたが、これからは私が独自に集めた最初のデータ(閲覧数)をもとにデータの生成を進めて行きます。
月と日のバイナリデータの生成¶
ではさっそく日付から特徴量を生成していきたいと思います。
使用するライブラリをインポートしてデータを表示させます。
# 実行
import pandas as pd
import numpy as np
import datetime
from sklearn.preprocessing import OneHotEncoder
df = pd.read_csv('sample.csv', index_col=0)
df.head(7)
count
2019-07-01 14
2019-07-02 9
2019-07-03 15
2019-07-04 6
2019-07-05 5
2019-07-06 7
2019-07-07 5
# 実行
# 最後から手前7行
df.tail(7)
count
2019-09-22 29
2019-09-23 17
2019-09-24 27
2019-09-25 36
2019-09-26 36
2019-09-27 25
2019-09-28 25
まず月のバイナリデータの生成ですが、7月~9月まであって、これを一列の特徴量「Month」として作ることも考えられますが、「July(7月)」「August(8月)」「September(9月)」の3つの列を作ることを考えます。
イメージ的には
「Month」列

「July(7月)」「August(8月)」「September(9月)」列

この「July(7月)」「August(8月)」「September(9月)」列ごとに1か0のバイナリ表現にすることを「ワンホットエンコーディング」と呼びます。
この手法はデータの要素がカテゴリなど文字列型を数値で表現するときにも使われるので非常に便利です。
そしてScikit-LearnのOneHotEncoderを用いることで簡単に変換することができます。
それでは「July(7月)」「August(8月)」「September(9月)」列を新たに生成していきます。
# 実行
# データの行数を取得
count = len(df)
month_day = []
# データの行数分回して同じ数の日付を取得
# datetime.dateの開始はデータに合わせる
for i in range(count):
month_day.append(datetime.date(2019, 7, 1) + datetime.timedelta(days=i))
month_day[:7]
[datetime.date(2019, 7, 1),
datetime.date(2019, 7, 2),
datetime.date(2019, 7, 3),
datetime.date(2019, 7, 4),
datetime.date(2019, 7, 5),
datetime.date(2019, 7, 6),
datetime.date(2019, 7, 7)]
新しく生成したmonth_dayデータから月を取得します。
# 実行
month = []
# month_dayを元に月だけを格納する
for i in month_day:
month.append(i.strftime('%b'))
month[27:35]
['Jul', 'Jul', 'Jul', 'Jul', 'Aug', 'Aug', 'Aug', 'Aug']
ここでpandasの機能であるfactorize()メソッドを使うことで、月の文字列をNumpy配列で数値と文字列に分けて返してくれます。
なので作成した月のデータをpandasのデータフレームします。
# 実行
month_df = pd.DataFrame(month, index=month_day, columns=['month'])
month_df.head()
month
2019-07-01 Jul
2019-07-02 Jul
2019-07-03 Jul
2019-07-04 Jul
2019-07-05 Jul
# 実行
# month列の文字列を数値と文字列に分割する
month_int, month_str = month_df['month'].factorize()
month_int
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2])
# 実行
month_str
Index(['Jul', 'Aug', 'Sep'], dtype='object')
あとはScikit-Learnのワンホットエンコーディングを使用して各列に0か1の表現をする値にするだけです。(※from sklearn.preprocessing import OneHotEncoderのインポートを忘れずに)
# 実行
# オブジェクトを取得
encoder = OneHotEncoder(categories='auto')
month_encoder = encoder.fit_transform(month_int.reshape(-1, 1))
# 呼び出す場合はNumpyのtoarray()を使う
month_encoder.toarray()
array([[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.]])
あとはこの変数をデータフレームにして月の特徴量は終わりです。
# 実行
# 列名(columns)にはfactorize()で分割したmonth_strを渡します
month_new_df = pd.DataFrame(month_encoder.toarray(), index=month_df.index, columns=month_str)
month_new_df.head()
Jul Aug Sep
2019-07-01 1.0 0.0 0.0
2019-07-02 1.0 0.0 0.0
2019-07-03 1.0 0.0 0.0
2019-07-04 1.0 0.0 0.0
2019-07-05 1.0 0.0 0.0
日の特徴量も流れは先ほどとほぼ同じなので、毎日使えるように関数にして自動化しましょう。
def day_category(list_year):
count = len(list_year)
month_day = []
for i in range(count):
month_day.append(datetime.date(2019, 7, 1) + datetime.timedelta(days=i))
day = []
for i in month_day:
day.append(int(str(i).split('-')[2]))
day_df = pd.DataFrame(day, index=month_day, columns=['day'])
day_int, day_str = day_df['day'].factorize()
encoder = OneHotEncoder(categories='auto')
day_encoder = encoder.fit_transform(day_int.reshape(-1, 1))
day_new_df = pd.DataFrame(day_encoder.toarray(), index=day_df.index, columns=day_str)
return day_new_df
この関数は2019年7月1日を開始としているので各データの開始日に合った日付を入れてください。
そして引数に数値のリスト、もしくわデータフレームをそのまま渡すだけで機能します。
# 実行
day_new_df = day_category(df)
day_new_df.head()
1 2 3 4 5 6 7 8 9 10 ... 22 23 24 25 26 27 28 29 30 31
2019-07-01 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2019-07-02 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2019-07-03 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2019-07-04 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2019-07-05 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
最後に月と日を結合します。
# 実行
# axis=1で列を指定
df_encoder = pd.concat([month_new_df, day_new_df], axis=1)
df_encoder.head()
Jul Aug Sep 1 2 3 4 5 6 7 ... 22 23 24 25 26 27 28 29 30 31
2019-07-01 1.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2019-07-02 1.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2019-07-03 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2019-07-04 1.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2019-07-05 1.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
曜日のバイナリデータを生成¶
次に一週間の月曜日~日曜日までの特徴量を生成していきたいと思います。
こちらの作業工程に関しても先ほどの工程と殆ど一緒なので、関数で定義し自動化してしまいましょう。
def week_category(list_year):
count = len(list_year)
month_day = []
for i in range(count):
month_day.append(datetime.date(2019, 7, 1) + datetime.timedelta(days=i))
weeks = []
for i in month_day:
weeks.append(i.strftime('%a'))
week = pd.DataFrame(weeks, index=month_day, columns=['weeks'])
week_int, week_str = week['weeks'].factorize()
encoder = OneHotEncoder(categories='auto')
week_encoder = encoder.fit_transform(week_int.reshape(-1, 1))
week_new_df = pd.DataFrame(week_encoder.toarray(), index=week.index, columns=week_str)
return week_new_df
引数にデータを入れるだけで
# 実行
df_new_week = week_category(df)
df_new_week.head(7)
Mon Tue Wed Thu Fri Sat Sun
2019-07-01 1.0 0.0 0.0 0.0 0.0 0.0 0.0
2019-07-02 0.0 1.0 0.0 0.0 0.0 0.0 0.0
2019-07-03 0.0 0.0 1.0 0.0 0.0 0.0 0.0
2019-07-04 0.0 0.0 0.0 1.0 0.0 0.0 0.0
2019-07-05 0.0 0.0 0.0 0.0 1.0 0.0 0.0
2019-07-06 0.0 0.0 0.0 0.0 0.0 1.0 0.0
2019-07-07 0.0 0.0 0.0 0.0 0.0 0.0 1.0
一週間分の列がしっかり出来上がっています。
先ほどのデータフレームと結合させて、月・日・曜日の入ったデータが完成しました。別途で休日などの列も作ることによって、分析するときに何か気づくことがあるかもしれません。
# 実行
df_comp = pd.concat([df_encoder, df_new_week], axis=1)
df_comp.head(7)
Jul Aug Sep 1 2 3 4 5 6 7 ... 29 30 31 Mon Tue Wed Thu Fri Sat Sun
2019-07-01 1.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0
2019-07-02 1.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0
2019-07-03 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0
2019-07-04 1.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0
2019-07-05 1.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0
2019-07-06 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0
2019-07-07 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0
生成した特徴量で予測をしてみよう¶
予測を行う機械学習モデルは、線形回帰・ランダムフォレスト・多層パーセプトロン(ニューラルネットワーク)を使用していきます。
ランダムフォレストではグリッドサーチを使って最適なハイパーパラメータ値の組み合わせを見つけ、多層パーセプトロンではランダムサーチを使って最適なハイパーパラメータ値を見つけます。
必要なモジュールをインポートします。
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
訓練用とテスト用に準備をする¶
すでに説明変数(日付データ)と目的変数(閲覧数)に分かれていますが、それぞれXとyに格納してScikit-Learnのtrain_test_splitで訓練用とテスト用にデータを綺麗に振り分けます。
X = df_comp
y = df
# random_stateを設定することでランダムに振り分けられたデータを再現できる
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
線形回帰¶
まずはシンプルで且つ単純なモデルである線形回帰から実装します。
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)
訓練セットでの予測正解率を測定
# 実行
lin_reg.score(X_train, y_train)
0.7854030815513006
78%。
以外に高かったのでビックリしています。
ではテストセットでの測定です。
# 実行
lin_reg.score(X_test, y_test)
0.7001041870754963
こちらも以外に高い数値を叩き出しているのでビックリしています。
では可視化してみます。
# 実行
lin_pred = lin_reg.predict(X_test)
x = range(len(y_test))
plt.figure(figsize=(15, 5))
plt.plot(x, y_test, 'b', label='Test')
plt.plot(x, lin_pred, 'r', label='Linear')
plt.legend()
plt.show()
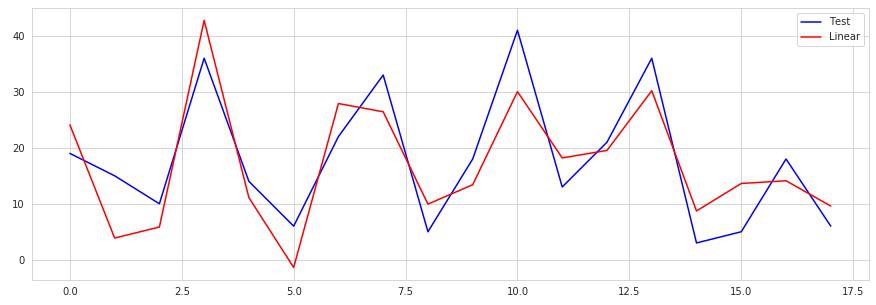
ランダムフォレスト¶
ここからの機械学習モデルでは交差検証を使用し最適なハイパーパラメータ値を見つけるための手法で学習していきたいと思います。
# リスト形式でハイパーパラメータ値を適当に設定
param_grid = [
{'n_estimators': [3, 10, 15, 20, 100], 'max_features': [3, 10, 15, 20, 30, 80]},
]
forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid, cv=3, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
交差検証を行った際に見つけた最適な値。
# 実行
grid_search.best_params_
{'max_features': 20, 'n_estimators': 3}
最適な値のモデルを変数に格納して、再び学習する。
forest_reg = grid_search.best_estimator_
forest_reg.fit(X_train, y_train)
訓練セットでの正解率を確認
# 実行
forest_reg.score(X_train, y_train)
0.7746568484736591
77%。
線形回帰の方が訓練セットに対しての精度は良い。
テストセットでの正解率を確認
# 実行
forest_reg.score(X_test, y_test)
0.5132009752699409
過学習を起こしていますがデータ量が少なすぎるのと、目的変数に対する因果関係のある特徴量が不足しているのでデータ量を増やすか、モデルを再度チューニングしてみるか試してみましょう。
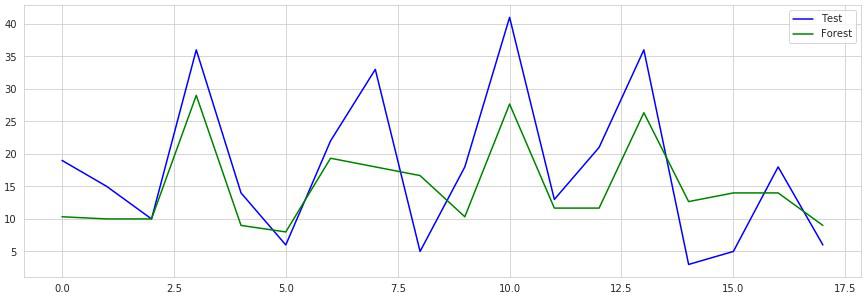
多層パーセプトロン(ニューラルネットワーク)¶
では最後のモデルは多層パーセプトロンです。
これまでのモデルとは違って隠れ層などがありパラメータもいくつもあって複雑です。
ハイパーパラメータの探索空間が大きいときには、グリッドサーチではなくランダムサーチを使って値を評価するのが相応しいとされています。
多層パーセプトロン(MLPRegressor)のドキュメント
さまざまな値を適当に設定
random_search = {'batch_size': [10, 50, 100, 300, 350, 400, 450, 500],
'hidden_layer_sizes': [(50, 50), (100, 50), (100, 50, 20), (100, 100, 50), (50, 50, 50, 20)],
'max_iter': [200, 300, 400, 500, 600, 1000],
'learning_rate_init': [0.1, 0.01, 0.001, 0.0001, 0.00001],
'random_state': [0]}
mlp_random_search = RandomizedSearchCV(MLPRegressor(), random_search, cv=10,
n_jobs=-1, scoring='neg_mean_squared_error', random_state=0)
mlp_random_search.fit(X_train, y_train)
最高の組み合わせを確認
# 実行
mlp_random_search.best_params_
{'random_state': 0,
'max_iter': 300,
'learning_rate_init': 0.001,
'hidden_layer_sizes': (50, 50),
'batch_size': 400}
この組み合わせで訓練して評価。
# 実行
mlp_best = mlp_random_search.best_estimator_
mlp_best.fit(X_train, y_train)
mlp_best.score(X_train, y_train)
0.8659132525746687
86%。
テストセットを確認。
# 実行
mlp_best.score(X_test, y_test)
0.6750864511530283
67%。
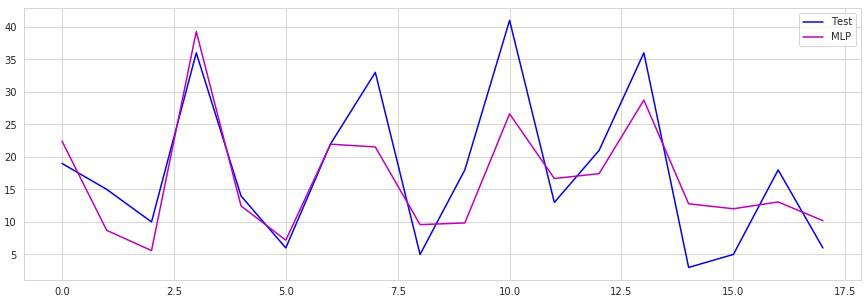
現段階では線形回帰モデルが一番データセットによく適合していたんじゃないかと思います。
他にもさまざまな機械学習モデルがあるので、試してみましょう。
次回¶
今回は日付を生成して機械学習に流すという一連の作業を行いました。
次回はブログサイト内(Webサイト)から目的変数に関係のありそうなデータを抽出し、新しくデータセットを作ってみようと思います。
最後までご覧いただきありがとうございました。
