【scikit-learn】FeatureUnionを使ってデータの前処理を自動化
投稿日 2020年5月22日 >> 更新日 2024年7月9日
今回はscikit-learnモジュールのFeatureUnionを使用して、機械学習モデルなどに与える際のデータの前処理を自動化させていきたいと思います。
データの前処理は、概ねpandasを利用して(Pythonを使っている方は)欠損値の処理や外れ値の処理、カテゴリー属性を数値に置き換えたりなど、それぞれの処理方法で合ったやり方を実装していくと思います。
そんなそれぞれの処理方法を1つのオブジェクトにまとめ上げて、生データを与えるだけで自動的に機械学習モデルに訓練をさせらるのがFeatureUnionです。
FeatureUnionは様々なオブジェクト(変換器)を組み合わせて実装するのですが、組み合わされた各オブジェクト(変換器)の再設定も行えるので、非常に柔軟で再利用可能な便利なツールです。
FeatureUnionには簡素化版のmake_unionというモジュールも用意されているので、後半の方で実装していきたいと思います。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
| Jupyter notebook |
| 使用ライブラリ | ライセンス |
|---|---|
| numpy==1.16.4 | OSI Approved (BSD) |
| pandas==0.25.0 | BSD |
| scikit-learn==0.21.3 | OSI Approved (new BSD) |
FeatureUnionの概要¶
scikit-learnの公式ドキュメント FeatureUnion
FeatureUnionの特徴としては、1つのデータに対して異なる変換器(オブジェクト)で並列処理を行い、その異なる変換器の戻り値同士を最終的に結合して結果を出力してくれます。
例として、数字を与えたらnumpyによってその数字の行と列が作成されて、その行列の要素を1に初期化する変換器と、要素を0に初期化する変換器をFeatureUnionにセッティングして、結合された結果を得る実装をしてみます。
まずは簡単な変換器を作っていきます。
この変換器はscikit-learnのBaseEstimatorクラスとTransformerMixinクラスを継承しています。詳しく知りたいという方はこちらの記事をご参照ください。
import numpy as np
import pandas as pd
from sklearn.base import BaseEstimator, TransformerMixin
class one_or_zero(BaseEstimator, TransformerMixin):
def __init__(self, one_vector=True):
self.one_vector = one_vector
def fit(self, line):
return self
def transform(self, line):
if self.one_vector:
return np.ones((line, line))
else:
return np.zeros((line, line))
例えばこの変換器のtransformメソッドに5を与えてみると5行5列の要素が1に初期化された配列が出力されます。
# 実行
one_or_zero().transform(5)
# 結果
array([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
この変換器のデフォルトではone_vector=Trueとなっており1に初期化されるので、Falseに設定して0に初期化させてみます。
# 実行
one_or_zero(one_vector=False).transform(5)
# 結果
array([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
異なる設定をした変換器をFeatureUnionに組み込んで結果を出力してみたいと思います。
FeatureUnionに組み込む際は、リスト内に1オブジェクトごとをタプルで設置します。
from sklearn.pipeline import FeatureUnion
feature_union = FeatureUnion([
('ones', one_or_zero()),
('zeros', one_or_zero(one_vector=False)),
])
タプル内では辞書型のようにキーとオブジェクト(変換器)のセットとなっていて、キーはそのオブジェクトの名前となります。
FeatureUnionは基本クラスとしてBaseEstimatorやTransformerMixinの各メソッドを使えるので、それらのメソッドを呼び出してみましょう。
# 実行
feature_union.fit_transform(5)
# 結果
array([[1., 1., 1., 1., 1., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 0., 0., 0., 0., 0.]])
このように、5の数字を与えると、5行5列の要素1と要素0を持つ異なる結果が結合されて出力されます。
異なる変換、そして最終的に結合されて戻ってくることから、数値属性の処理とカテゴリー属性の処理に分けて並列処理を実装できることが分かります。
次はその例を見ていきます。
数値属性とカテゴリー属性のデータを一括処理¶
FeatureUnionの概要を少し理解できたところで、数値属性とカテゴリー属性の要素を持つデータを作成し、そのデータの属性を摘出できる新たな変換器を作成していきます。
データの準備¶
以下のように数値属性とカテゴリー属性共に欠損値のあるデータを作成します。
# 実行
df = pd.DataFrame(np.arange(1, 26).reshape(5, 5), columns=list('ABCDE'))
df['F'] = ['Yes', 'No', 'Yes', np.nan, 'Yes']
df['G'] = [np.nan, 'High', 'Low', 'High', 'High']
df = df.replace([12, 23, 10], np.nan)
df
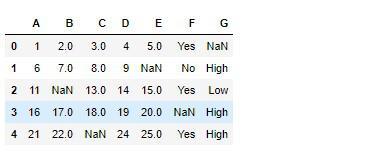
このdfというデータをFeatureUnionのtransformメソッドに渡すだけでそれぞれの属性に合った処理を行いたいので、先ほどの自作変換器と同じような要領で新たな変換器を作ります。
自作変換器の作成¶
scikit-learnモジュールのBaseEstimatorクラスとTransformerMixinクラス継承して、属性を摘出できる変換器を作ります。
BaseEstimatorとTransformerMixinについてはこちらをご参照ください。
class Selecter(BaseEstimator, TransformerMixin):
def __init__(self, num_attribute=True):
self.num_attribute = num_attribute
# 何もしない
def fit(self, X):
return self
# 初期化メソッドの引数に従って変換
def transform(self, X):
if self.num_attribute:
X = X.select_dtypes(exclude=['object'])
return X.values
else:
X = X.select_dtypes(include=['object'])
return X.values
Selecterの処理内容は、初期化メソッドの引数num_attributeをTrueかFalseに予め設定することで、各属性を摘出しnumpy配列として返されるようになります。
デフォルトでは数値属性のみ返されます。
# 実行
Selecter().fit_transform(df)
# 結果
array([[ 1., 2., 3., 4., 5.],
[ 6., 7., 8., 9., nan],
[11., nan, 13., 14., 15.],
[16., 17., 18., 19., 20.],
[21., 22., nan, 24., 25.]])
num_attributeをFalseに設定すると、カテゴリー属性のみ返されます。
# 実行
Selecter(num_attribute=False).fit_transform(df)
# 結果
array([['Yes', nan],
['No', 'High'],
['Yes', 'Low'],
[nan, 'High'],
['Yes', 'High']], dtype=object)
これで準備は整ったので、属性ごとに前処理を行うそれぞれに必要なscikit-learnモジュールを使って2つの変換器を組み立てます。
Pipelineを使って属性ごとの前処理を行う¶
scikit-learnモジュールのPipelineを使って、数値属性を処理する変換器とカテゴリー属性を処理する変換器をそれぞれ組み立てていきます。
Pipelineの詳しい内容に関しては、こちらの記事をご参照ください。
Pipelineに必要な変換器をセッティングするだけで、順次処理を行ってくれます。
まずは数値属性用の変換器(Pipeline)です。
必要な変換器は先ほど作った自作変換器のデフォルト設定と欠損値を他の数字に置き換えるscikit-learnモジュールのSimpleImputerと、データをスケーリング(標準化)するscikit-learnモジュールのStandardScalerをセッティングします。
SimpleImputerについての詳しい操作はこちらをご参照ください。
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
num_pipeline = Pipeline([
('num_selecter', Selecter()),
('imputer', SimpleImputer(strategy='mean')), # 欠損値を平均値に置き換える
('scaler', StandardScaler()),
])
Pipeline引数にリストとして1つの変換器につきタプルで定義します。
辞書型のように変換器とその変換器の名前となるキーをそれぞれ定義してPipelineのオブジェクトを初期化します。
ではfit_transformメソッドを呼び出しでデータを変換してみます。
# 実行
num_pipeline.fit_transform(df)
# 結果
array([[-1.41421356, -1.41421356, -1.5 , -1.41421356, -1.70084013],
[-0.70710678, -0.70710678, -0.5 , -0.70710678, 0. ],
[ 0. , 0. , 0.5 , 0. , -0.18898224],
[ 0.70710678, 0.70710678, 1.5 , 0.70710678, 0.56694671],
[ 1.41421356, 1.41421356, 0. , 1.41421356, 1.32287566]])
Selecter自作変換器が数値属性だけを摘出し、欠損値を平均値に置き換え、スケーリングして返しました。
次にカテゴリー属性用の変換器(Pipeline)を組み立てます。
こちらではSelecter自作変換器のパラメータnum_attributeをFalseに設定し、SimpleImputerを使って欠損値を最頻値に置き換え、最後はscikit-learnモジュールのOneHotEncoderを使用してカテゴリーを数値に置き換えます。
OneHotEncoderについての詳細はこちらをご参照ください。
from sklearn.preprocessing import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
cat_pipeline = Pipeline([
('cat_selecter', Selecter(num_attribute=False)),
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(sparse=False)),
])
fit_transformメソッドを呼び出しデータを変換してみます。
# 実行
cat_pipeline.fit_transform(df)
# 結果
array([[0., 1., 1., 0.],
[1., 0., 1., 0.],
[0., 1., 0., 1.],
[0., 1., 1., 0.],
[0., 1., 1., 0.]])
カテゴリー属性内の欠損値は各カテゴリーの最頻値に置き換えられ、各カテゴリーの数に従って数値属性として説明変数が作られました。
最後はnum_pipelineとcat_pipelineの返り値を結合させるためにFeatureUnionに与えたいと思います。
FeatureUnionでフルパイプライン¶
これまでの実装でFeatureUnionのセッティング方法は理解していると思うので、さっそく組み立てていきましょう。
from sklearn.pipeline import FeatureUnion
full_pipeline = FeatureUnion([
('num_pipeline', num_pipeline),
('cat_pipeline', cat_pipeline),
])
ではfit_transformメソッドを呼び出し、結果を変数Xに格納します。
# 実行
X = full_pipeline.fit_transform(df)
X
# 結果
array([[-1.41421356, -1.41421356, -1.5 , -1.41421356, -1.70084013,
0. , 1. , 1. , 0. ],
[-0.70710678, -0.70710678, -0.5 , -0.70710678, 0. ,
1. , 0. , 1. , 0. ],
[ 0. , 0. , 0.5 , 0. , -0.18898224,
0. , 1. , 0. , 1. ],
[ 0.70710678, 0.70710678, 1.5 , 0.70710678, 0.56694671,
0. , 1. , 1. , 0. ],
[ 1.41421356, 1.41421356, 0. , 1.41421356, 1.32287566,
0. , 1. , 1. , 0. ]])
上手く前処理が行われ、結合されているかと思います。
FeatureUnionのハイパーパラメータはget_paramsメソッドで表示することができます。
# 実行
full_pipeline.get_params()
# 結果
{'n_jobs': None, 'transformer_list': [('num_pipeline', Pipeline(memory=None,
steps=[('num_selecter', Selecter(num_attribute=True)),
('imputer',
SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='mean',
....
....
長いので省略
....
'num_pipeline__verbose': False, 'num_pipeline__num_selecter': Selecter(num_attribute=True),
'num_pipeline__imputer': SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='mean', verbose=0),
'num_pipeline__scaler': StandardScaler(copy=True, with_mean=True, with_std=True),
'num_pipeline__num_selecter__num_attribute': True, 'num_pipeline__imputer__add_indicator': False,
'num_pipeline__imputer__copy': True, 'num_pipeline__imputer__fill_value': None,
'num_pipeline__imputer__missing_values': nan, 'num_pipeline__imputer__strategy': 'mean',
'num_pipeline__imputer__verbose': 0, 'num_pipeline__scaler__copy': True,
'num_pipeline__scaler__with_mean': True, 'num_pipeline__scaler__with_std': True, 'cat_pipeline__memory': None, 'cat_pipeline__steps': [('cat_selecter',
....
....
'cat_pipeline__cat_selecter__num_attribute': False, 'cat_pipeline__imputer__add_indicator': False,
'cat_pipeline__imputer__copy': True, 'cat_pipeline__imputer__fill_value': None,
'cat_pipeline__imputer__missing_values': nan, 'cat_pipeline__imputer__strategy': 'most_frequent',
'cat_pipeline__imputer__verbose': 0, 'cat_pipeline__onehot__categorical_features': None,
'cat_pipeline__onehot__categories': None, 'cat_pipeline__onehot__drop': None,
'cat_pipeline__onehot__dtype': numpy.float64, 'cat_pipeline__onehot__handle_unknown': 'error',
'cat_pipeline__onehot__n_values': None, 'cat_pipeline__onehot__sparse': False}
上記の出力結果は辞書構造となっており、各オブジェクトのトップクラスの名前がキーとなっています。
set_paramsメソッドではハイパーパラメータの変更が行えますが、アンダークラス(最下層の変換器)のハイパーパラメータにアクセスするにはキーを指定する必要があります。
例えば以下のハイパーパラメータの変更は、数値属性のPipelineにあるSimpleImputerの統計値を中央値に変更しています。
# 実行
full_pipeline.set_params(num_pipeline__imputer__strategy='median')
# 結果
FeatureUnion(n_jobs=None,
transformer_list=[('num_pipeline',
Pipeline(memory=None,
steps=[('num_selecter',
Selecter(num_attribute=True)),
('imputer',
SimpleImputer(add_indicator=False,
copy=True,
fill_value=None,
missing_values=nan,
strategy='median', # 変更済み
verbose=0)),
('scaler',
StandardScaler(copy=True,
with_mean=True,
with_std=True))],
verbose=False)),
('cat_pipeline...
....
....
verbose=False))],
transformer_weights=None, verbose=False)
set_paramsメソッドの際の変更は反映されているので変数に格納しなくても大丈夫です。
先ほどFeatureUnionの結果を変数Xに格納しておきましたが、FeatureUnion(full_pipeline)と同じ処理を手動で行ってみて、双方同じ結果となっているのか確認していきたいと思います。
まずは手動で数値属性、カテゴリー属性を順番に変換処理をしていきます。
pandasのselect_dtypesメソッドで各属性を変数に格納します。
# 実行
df_num = df.select_dtypes(exclude=['object'])
df_num
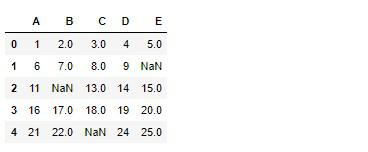
# 実行
df_cat = df.select_dtypes(include=['object'])
df_cat

scikit-learnの各変換器を初期化し、変換・結合のあとデータフレームに格納します。
# 実行
# 変換器の初期化
num_imp = SimpleImputer(strategy='mean')
cat_imp = SimpleImputer(strategy='most_frequent')
scaler = StandardScaler()
# 各データを変換
arr_num_imp = num_imp.fit_transform(df_num)
arr_cat_imp = cat_imp.fit_transform(df_cat)
# 数値属性のスケーリング
arr_num_scaler = scaler.fit_transform(arr_num_imp)
# 各配列を結合しデータフレームに格納
arr_join = np.concatenate([arr_num_scaler, arr_cat_imp], axis=1)
df_join = pd.DataFrame(arr_join, columns=df.columns)
# カテゴリー属性を数値化するpandasのダミー変数化
df_dummies = pd.get_dummies(df_join[['F', 'G']])
df_dummies = pd.concat([df_join.drop(['F', 'G'], axis=1), df_dummies], axis=1)
df_dummies
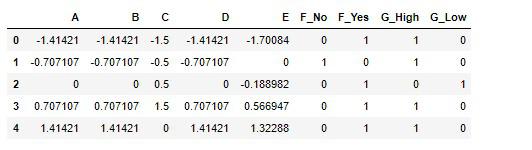
FeatureUnion(full_pipeline)の結果をデータフレームに格納します。
# 実行
new_df = pd.DataFrame(X, columns=df_dummies.columns)
new_df
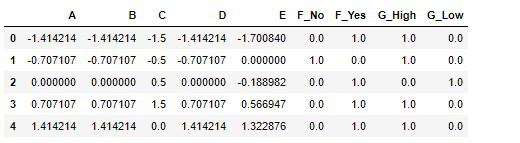
間違いなくFeatureUnionは機能していることが分かります。
前処理の実装を1つのオブジェクトとして自動化することが出来たので、本番システムでも使えるように保存しておきましょう。
フルパイプラインの保存¶
ここではpickleモジュールを使用してフルパイプラインの保存を行います。
保存
import pickle
# SimpleImputerを平均値に直す
full_pipeline.set_params(num_pipeline__imputer__strategy='mean')
with open('full_pipeline.pickle', 'wb') as f:
pickle.dump(full_pipeline, f)
保存したフルパイプラインを読み込んで、本番さながらのようなデータを使い試してみましょう。
with open('full_pipeline.pickle', 'rb') as f:
full_pip = pickle.load(f)
dfデータから、インデックス2のデータだけ取り出します。
test_data = df[2:3]
test_data

それではtransformメソッドを呼び出して変換をしてみます。
※fit・fit_transformメソッドを呼び出すと適合されてしまい前提が変わってしまうので注意
# 実行
full_pip.transform(test_data)
# 結果
array([[ 0. , 0. , 0.5 , 0. , -0.18898224,
0. , 1. , 0. , 1. ]])
問題無く変換されています。
FeatureUnionに変換器をまとめてしまうことで、1つの部品として扱う事ができるので非常に便利なツールです。
是非オリジナルの変換器を作成してみましょう。
FeatureUnionの簡素版、make_union¶
scikit-learnの公式ドキュメント make_union
FeatureUnionの無駄を無くし、簡単な定義で実装できるのがmake_unionです。
FeatureUnionではオブジェクトを定義した際にキーとなる名前も定義しましたが、make_unionではオブジェクトから自動的に名前付けをしてくれます。
FeatureUnionで定義した数値属性のPipelineとカテゴリー属性のPipelineを使用して実際に行っていきます。
# 実行
from sklearn.pipeline import make_union
make_pipeline = make_union(num_pipeline, cat_pipeline)
make_pipeline.fit_transform(df)
# 結果
array([[-1.41421356, -1.41421356, -1.5 , -1.41421356, -1.70084013,
0. , 1. , 1. , 0. ],
[-0.70710678, -0.70710678, -0.5 , -0.70710678, 0. ,
1. , 0. , 1. , 0. ],
[ 0. , 0. , 0.5 , 0. , -0.18898224,
0. , 1. , 0. , 1. ],
[ 0.70710678, 0.70710678, 1.5 , 0.70710678, 0.56694671,
0. , 1. , 1. , 0. ],
[ 1.41421356, 1.41421356, 0. , 1.41421356, 1.32287566,
0. , 1. , 1. , 0. ]])
get_params属性を呼び出してみます。
# 実行
make_pipeline.get_params()
# 結果
{'n_jobs': None, 'transformer_list': [('pipeline-1', Pipeline(memory=None,
steps=[('num_selecter', Selecter(num_attribute=True)),
('imputer',
SimpleImputer(add_indicator=False, copy=True, fill_value=None,
....
....
長いので省略
....
....
'pipeline-1__verbose': False,
'pipeline-1__num_selecter': Selecter(num_attribute=True),
'pipeline-1__imputer': SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='mean', verbose=0),
'pipeline-1__scaler': StandardScaler(copy=True, with_mean=True, with_std=True),
'pipeline-1__num_selecter__num_attribute': True,
'pipeline-1__imputer__add_indicator': False,
'pipeline-1__imputer__copy': True,
'pipeline-1__imputer__fill_value': None,
'pipeline-1__imputer__missing_values': nan,
'pipeline-1__imputer__strategy': 'mean',
'pipeline-1__imputer__verbose': 0,
'pipeline-1__scaler__copy': True,
'pipeline-1__scaler__with_mean': True,
'pipeline-1__scaler__with_std': True,
'pipeline-2__memory': None,
'pipeline-2__steps': [('cat_selecter',
Selecter(num_attribute=False)),
('imputer', SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='most_frequent', verbose=0)),
('onehot',
OneHotEncoder(categorical_features=None, categories=None, drop=None,
dtype=<class 'numpy.float64'>, handle_unknown='error',
n_values=None, sparse=False))],
'pipeline-2__verbose': False, 'pipeline-2__cat_selecter': Selecter(num_attribute=False),
'pipeline-2__imputer': SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='most_frequent', verbose=0),
'pipeline-2__onehot':
OneHotEncoder(categorical_features=None, categories=None, drop=None,
dtype=<class 'numpy.float64'>, handle_unknown='error',
n_values=None, sparse=False),
'pipeline-2__cat_selecter__num_attribute': False,
'pipeline-2__imputer__add_indicator': False,
'pipeline-2__imputer__copy': True,
'pipeline-2__imputer__fill_value': None,
'pipeline-2__imputer__missing_values': nan,
'pipeline-2__imputer__strategy': 'most_frequent',
'pipeline-2__imputer__verbose': 0,
'pipeline-2__onehot__categorical_features': None,
'pipeline-2__onehot__categories': None,
'pipeline-2__onehot__drop': None,
'pipeline-2__onehot__dtype': numpy.float64,
'pipeline-2__onehot__handle_unknown': 'error',
'pipeline-2__onehot__n_values': None,
'pipeline-2__onehot__sparse': False}
辞書構造で少し見難いですが、しっかり名前付けがされています。
make_unionはシンプルな定義でセッティングできるので非常に便利です。
他にもscikit-learnには優れた機能が豊富に揃っているので、自分に合った機能を探して試して遊び倒していきましょう。
それでは以上となります。
最後までご覧いただきありがとうございました。
