【Python】chatterbot-corpusのインストールとChatterBotの日本語設定
投稿日 2020年12月15日 >> 更新日 2023年3月1日
今回はPythonのチャットボットフレームワークであるChatterBotに、自然的な会話のトレーニングを簡易的に実装させることのできる「chatterbot-corpus」をインストールしていきたいと思います。
それに伴い日本語設定に関する方法も細かくご紹介していこうと思います。
この記事ではChatterBot本体のインストールやチュートリアル的な事は行わないので、興味のある方は以下の記事、もしくわ本家のChatterBot公式ドキュメントをご参照ください。

実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
※「ChatterBot==1.1.0」は削除されているみたいなので、別のバージョンで試してみて下さい。
| 使用ライブラリ | ライセンス |
|---|---|
| ChatterBot==1.1.0 | BSD |
| chatterbot-corpus==1.2.0 | BSD |
| spacy==2.3.0 or 2.2.0 | MIT |
| ja-core-news-sm==2.3.1 | 不明 |
| ginza==2.2.1 | MIT |
| mysqlclient==2.0.2 | GNU General Public License (GPL) |
chatterbot-corpusのインストール¶
chatterbot-corpusとは、英語をはじめ様々な言語の文章が集積されたコーパスが収録されているライブラリです。
pipでインストールすることができますが、こちらには日本語のコーパスは収録されていません。
$ pip install chatterbot-corpus
日本語のコーパスが収録されている「chatterbot-corpus」を利用するには、開発者のGitHubにある最新のリポジトリからコーパスデータをインストールする必要があります。
すでに「pip install chatterbot-corpus」でインストールしている場合は、アンインストールを行ってから再度GitHubのリポジトリからインストールを実行します。
$ pip uninstall chatterbot-corpus
pipの中に「chatterbot-corpus」が存在していない場合↓
$ pip install git+git://github.com/gunthercox/chatterbot-corpus/@master#egg=chatterbot_corpus
インストールが完了したらさっそくコーパスデータをトレーニングしてみます。
ChatterBotCorpusTrainerでコーパスデータの訓練¶
ChatterBotでは事前に収録した会話をトレーニングすることができるTrainerクラスが幾つか用意されており、その中の「ChatterBotCorpusTrainer」オブジェクトを利用する事で「chatterbot-corpus」のコーパスデータを訓練させることができます。
日本語のパターンは後ほど行うとして、まずは英語のコーパスを使ってChatterBotCorpusTrainerを実装してみたいと思います。
# chatbot.py
from chatterbot import ChatBot
from chatterbot.trainers import ChatterBotCorpusTrainer
bot = ChatBot(
name='MyBot'
)
trainer = ChatterBotCorpusTrainer(bot)
# trainメソッドに「chatterbot.corpus.言語」の文字列を渡す
trainer.train(
'chatterbot.corpus.english' # 英語のコーパス
)
while True:
try:
input_data = input('YOU: ')
response = bot.get_response(input_data)
print('{}: {}'.format(bot.name, response))
except(KeyboardInterrupt, EOFError, SystemExit):
break
実行すると以下のようにログが出力されコーパスデータがデータベースに保存されます。
$ python3 chatbot.py
Training ai.yml: [####################] 100%
Training botprofile.yml: [####################] 100%
Training computers.yml: [####################] 100%
Training conversations.yml: [####################] 100%
Training emotion.yml: [####################] 100%
Training food.yml: [####################] 100%
Training gossip.yml: [####################] 100%
Training greetings.yml: [####################] 100%
Training health.yml: [####################] 100%
Training history.yml: [####################] 100%
Training humor.yml: [####################] 100%
Training literature.yml: [####################] 100%
Training money.yml: [####################] 100%
Training movies.yml: [####################] 100%
Training politics.yml: [####################] 100%
Training psychology.yml: [####################] 100%
Training science.yml: [####################] 100%
Training sports.yml: [####################] 100%
Training trivia.yml: [####################] 100%
YOU: Hello?
MyBot: Hi
日本語に対応させる¶
ChatterBotの内部では自然言語処理ライブラリの「SpaCy」が使用されており、ユーザーの声明に対する応答として検索される文字列はSpaCyによって作成されます。
厳密には深層学習による学習済みモデルをSpacyで初期化して、入力されてきた文章を解析し品詞を抽出します。
抽出された要素を元にバイグラムペアに変換し、検索用の要素として使用されます。
こちらの記事でやや詳しく説明しています。
ChatterBotの基本設定では、英語以外の言語は正しくバイグラムに変換されないので、他言語でも変換されるようにし、大規模なSQLデータベースにもしっかり対応されるように順に実装していきます。
まずはデフォルト設定のまま日本語のコーパスをトレーニングさせてみましょう。
日本語用コーパスのトレーニング¶
GitHubから最新のchatterbot-corpusを取得済みであれば、日本語の自然言語が集積されたコーパスを使用することができます。
それではトレーニングを実行させてみます。
# chatbot.py
from chatterbot import ChatBot
from chatterbot.trainers import ChatterBotCorpusTrainer
bot = ChatBot(
name='MyBot'
)
trainer = ChatterBotCorpusTrainer(bot)
trainer.train(
'chatterbot.corpus.japanese' # 日本語用コーパス
)
while True:
try:
input_data = input('YOU: ')
response = bot.get_response(input_data)
print('{}: {}'.format(bot.name, response))
except(KeyboardInterrupt, EOFError, SystemExit):
break
「chatbot.py」を実行し、適当に会話を楽しんでみます。
$ python3 chatbot.py
Training ai.yml: [####################] 100%
Training botprofile.yml: [####################] 100%
Training computers.yml: [####################] 100%
Training conversations.yml: [####################] 100%
Training emotion.yml: [####################] 100%
Training food.yml: [####################] 100%
Training gossip.yml: [####################] 100%
Training greetings.yml: [####################] 100%
Training health.yml: [####################] 100%
Training history.yml: [####################] 100%
Training humor.yml: [####################] 100%
Training literature.yml: [####################] 100%
Training money.yml: [####################] 100%
Training movies.yml: [####################] 100%
Training politics.yml: [####################] 100%
Training psychology.yml: [####################] 100%
Training science.yml: [####################] 100%
Training sports.yml: [####################] 100%
Training trivia.yml: [####################] 100%
YOU: あなたは誰ですか?
MyBot: 私は自分自身を自営業者と考えています。
YOU: 業者の方ですか?
MyBot: 怒っていません。なぜ聞くのですか?
YOU: 私は何も聞いていません
MyBot: あなたは誰をも憎んでいますか?
YOU:
始まりの会話から繋げていこうと質問を返してみましたが余り噛み合ってないように思えます。
もちろんトレーニングされていない文章を入力するとチャットボットは返す言葉を見つけられないので、データベース内からランダムに応答となる文章を選び出します。
一旦データベースの中身を確認してみましょう。
SQLite3データベースに接続
$ sqlite3 db.sqlite3
sqlite>
sqlite> # テーブル内のカラム名を出力
sqlite> .header on
sqlite>
sqlite> # テーブル内の幅を調整(左から3つのid:5 text:30 search_text:30)
sqlite> .width 5 30 30
sqlite>
sqlite> select id, text, search_text, persona from statement;
id|text|search_text|persona
1|AIとは何ですか?|aiとは何ですか ?|
2|人工知能は、思考する機械を構築することに専念する工学と科学の枝である。|人工知能は、思考する機械を構築することに専念する工学と科学の枝である 。|
3|AIとは何ですか?|aiとは何ですか ?|
4|AIは人間の心の機能を再現するハードウェアとソフトウェアの構築に関わる科学の分野です。|aiは人間の心の機能を再現するハードウェアとソフトウェアの構築に関わる科学の分野で す 。|
...
...
1870|あなたは誰ですか?|あなたは誰ですか ?|
1871|私は自分自身を自営業者と考えています。||bot:MyBot
1872|業者の方ですか?|業者の方ですか ?|
1873|怒っていません。なぜ聞くのですか?||bot:MyBot
1874|私は何も聞いていません|私は何も聞いていません|
1875|あなたは誰をも憎んでいますか?||bot:MyBot
sqlite>
データベース内のstatementテーブルから取得したカラムは、「text、search_text、persona」ですが、ここで重要なのが「search_text」に保存されるべきデータです。
中身を確認してみると、text、つまり入力した文章をそのままsearch_textに保存されていますが、本来であればChatterBot独特の「バイグラムペア」として保存されなければなりません。
この章の冒頭でも言いましたが、バイグラムペアの変換には自然言語処理ライブラリの「SpaCy」が使用されているので、日本語の品詞抽出が行われるように設定する必要があります。
SpaCyから日本語版統計モデルをダウンロード¶
Spacyで日本語の形態素解析を実装するには「ja_core_news_sm」、もしくわ「ja_ginza」をインストールする必要があります。
現時点でのChatterBot==1.1.0でこれらの日本語統計モデルを試してみた結果、spacyのバージョンによって互換性のあるものと無いものでインストールできるモデルが限られてしまいます。
とはいえ、同じ言語のモデルは二つも必要ないかと思うので、どちらかお好きな方のモデルをインストールしましょう。
ja_core_news_sm¶
まずは「ja_core_news_sm」のインストール方法です。
このモデルは現在のspacyのバージョンを「spacy==2.1.9」から「spacy==2.3.0」にアップグレードする必要があります。
$ pip install --upgrade spacy==2.3.0
アップグレードが完了したら、公式ドキュメントに従って日本語版の統計モデルをダウンロードします。
$ python3 -m spacy download ja_core_news_sm
GitHubからpip経由でインスールすることもできます。
$ pip install https://github.com/explosion/spacy-models/releases/download/ja_core_news_sm-2.3.1/ja_core_news_sm-2.3.1.tar.gz
既に「en」という英語の統計モデルをインストール済みの場合、「spacy==2.1.9」と互換性のあるモデルとなっているので、必要であれば再度ダウンロードしておきます。
$ python3 -m spacy download en
次にGINZAモデルのインストール方法です。
GINZA¶
ja_ginzaのモデルでは、最近の単語にも対応した形態素を出力するモデルだと見受けられます。
例えば、「ja_core_news_sm」モデルでは「人工知能とは何ですか?」という単語を解析するのに「人工・知能・とは・何・ですか?」などの品詞に分けます。
同じ文章を「ja_ginza」モデルを使用して解析すると、「人工知能・とは・何・ですか?」などという品詞に分けられ、「人工知能」としっかり推論できています。
小さな違いではありますが、ChatterBotの検索アルゴリズムで処理されている「n-gram法」に大きく影響されるので、おススメではあります。
詳細は公式ドキュメントをお読みください。
最新のGINZAモデルでは、spacy==2.3.5にバージョンを上げなければならず、ChatterBot==1.1.0では扱えなくなってしまうので、ChatterBotとの互換性を保つために、ginza==2.2.1が使用できるspacy==2.2.0をインストールします。
$ pip install --upgrade spacy==2.2.0
pip経由でインストールします。
$ pip install "https://github.com/megagonlabs/ginza/releases/download/latest/ginza-latest.tar.gz"
ダウンロードが完了したらChatterBotに読み込ませます。
ChatterBotに統計モデルを読み込ませる¶
ChatterBotに統計モデルを指定するにはパラメータ「tagger_language」に言語オブジェクトを渡します。
言語オブジェクトはChatterBotソースコードの「languages.py」にあります。
例えばデフォルトの英語統計モデルが指定されている場合は以下のようになります。
from chatterbot import ChatBot
from chatterbot import languages # 言語モジュール
bot = ChatBot(
name='MyBot',
tagger_language=languages.ENG # 統計モデルの言語指定
)
languages.pyの中にあらゆる言語を使えるようにするクラスが定義されています。
このクラス名は上から下にA~Zのアルファベット順に定義されており、Jから始まるクラスを探すと「JPN」と日本語用のクラスが定義されています。
class JPN:
ISO_639_1 = 'ja'
ISO_639 = 'jpn'
ENGLISH_NAME = 'Japanese'
このクラスをChatterBotのパラメータ「tagger_language」に設定すれば良いのですが、残念なことにエラーとなってしまいます。
「OSError: [E050] Can't find model 'ja'. It doesn't seem to be a shortcut link, a Python package or a valid path to a data directory.」
ChatterBot内部で日本語統計モデルをロードしようとしているSpaCyは、JPNクラスの「ISO_639_1」を取得しているので、要素の「ja」では見つからないとなりました。
ISO_639_1 = 'ja'
本来ロードしたいモデルは「ja_core_news_sm」なので、「ja」を書き換えたいと思います。
ソースコードを編集してしまうのは不味いので、カレントディレクトリに新規で「languages.py」を作成してしまいます。
カレントディレクトリ
|- chatbot.py
|-languages.py # 新規作成
# languages.py
class JPN:
ISO_639_1 = 'ja_core_news_sm' # jaからja_core_news_smに変更
ISO_639 = 'jpn'
ENGLISH_NAME = 'Japanese'
# GINZAモデル
class GINZA:
ISO_639_1 = 'ja_ginza'
ISO_639 = 'ginza'
ENGLISH_NAME = 'ginza'
そしてchatbot.pyで読み込みます。
# chatbot.py
from chatterbot import ChatBot
#from chatterbot import languages
import languages # 自作言語モジュール
bot = ChatBot(
name='MyBot',
tagger_language=languages.JPN # 日本語モデルを指定
# tagger_language=languages.GINZA # GINZAモデルの場合
)
これによりSpaCyは日本語の文章から品詞を抽出し、それらの要素を元にバイグラムペアに変換されるようになったかと思います。
ではデータベースファイル(db.sqlite3)を一旦削除してから、chatbot.pyを実行します。
$ python3 chatbot.py
Training ai.yml: [####################] 100%
Training botprofile.yml: [####################] 100%
Training computers.yml: [####################] 100%
Training conversations.yml: [####################] 100%
Training emotion.yml: [####################] 100%
Training food.yml: [####################] 100%
Training gossip.yml: [####################] 100%
Training greetings.yml: [####################] 100%
Training health.yml: [####################] 100%
Training history.yml: [####################] 100%
Training humor.yml: [####################] 100%
Training literature.yml: [####################] 100%
Training money.yml: [####################] 100%
Training movies.yml: [####################] 100%
Training politics.yml: [####################] 100%
Training psychology.yml: [####################] 100%
Training science.yml: [####################] 100%
Training sports.yml: [####################] 100%
Training trivia.yml: [####################] 100%
YOU: あなたは誰ですか?
MyBot: 私は単なる人工知能です。
YOU: 人工知能とは何ですか?
MyBot: 人工知能は、思考する機械を構築することに専念する工学と科学の枝である。
YOU: 凄いですね
MyBot: それはよかった
先ほどよりかは上手く会話のキャッチボールができているように見受けられます。
データベース内を確認してみます。
sqlite> select id, text, search_text, persona from statement;
id|text|search_text|persona
1|AIとは何ですか?|NOUN:何|
2|人工知能は、思考する機械を構築することに専念する工学と科学の枝である。|NOUN:知能 NOUN:思考 VERB:機械 NOUN:構築 VERB:専念 VERB:工学 NOUN:科学 NOUN:枝|
3|AIとは何ですか?|NOUN:何|
4|AIは人間の心の機能を再現するハードウェアとソフトウェアの構築に関わる科学の分野です。|NOUN:人間 NOUN:心 NOUN:機能 NOUN:再現 VERB:ハードウェア NOUN:ソフトウェア NOUN:構築 NOUN:関わる VERB:科学 NOUN:分野|
...
...
1870|あなたは誰ですか?|PRON:誰|
1871|私は単なる人工知能です。||bot:MyBot
1872|人工知能とは何ですか?|NOUN:知能 NOUN:何|
1873|人工知能は、思考する機械を構築することに専念する工学と科学の枝である。||bot:MyBot
1874|凄いですね|ADJ:です AUX:ね|
1875|それはよかった||bot:MyBot
sqlite>
カラム「search_text」にはしっかりとバイグラムペアに変換された要素が保存されています。
ただし日本語設定で考えなければならないのは、日本語の文章をどのようにバイグラムペアとして変換しているかです。
ChatterBotの検索アルゴリズムでは英語の文法に従って品詞とテキストのペアとして形成されているため、当然日本語でもそのようなバイグラムとして形成されます。
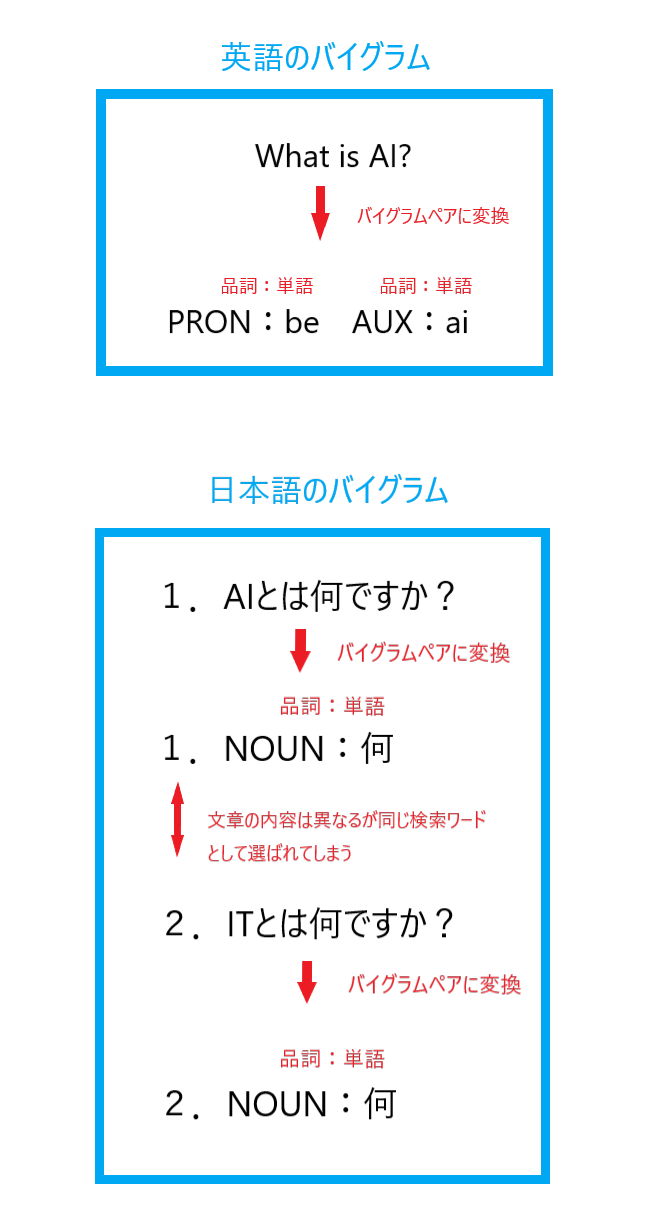
上図のように日本語のバイグラムペアでは、文章が異なっていても検索ワードは同一のものを選び出すので、何か工夫をしなければ噛み合わない応答となってしまいます。
$ python3 chatbot.py
YOU: AIとは何ですか?
MyBot: 人工知能は、思考する機械を構築することに専念する工学と科学の枝である。
YOU: ITとは何ですか?
MyBot: 人工知能は、思考する機械を構築することに専念する工学と科学の枝である。
YOU:
デフォルトのバイグラムペアアルゴリズムはこちらのソースコードにあります。
MySQLデータベースに接続¶
ここではSQLでーベースの切り替えでMySQLデータベースの接続を例に実装していきますので、その他のSQLキャリアの方はSQLAlchemyのデータベース接続に関するサンプル記事をご参照ください。
ではChatterBotの内部で動いているSQLAlchemyでMySQLの接続に必要なツールをインストールします。
pip install mysqlclient
このようなエラーが出力された場合は、システムに開発者ツールをインストールします。
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-build-gw4uqp3t/mysqlclient/setup.py", line 15, in <module>
metadata, options = get_config()
File "/tmp/pip-build-gw4uqp3t/mysqlclient/setup_posix.py", line 65, in get_config
libs = mysql_config("libs")
File "/tmp/pip-build-gw4uqp3t/mysqlclient/setup_posix.py", line 31, in mysql_config
raise OSError("{} not found".format(_mysql_config_path))
OSError: mysql_config not found
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-gw4uqp3t/mysqlclient/
Ubuntuの場合
$ sudo apt install python3-dev default-libmysqlclient-dev
MacOSの場合は以下が参考になるかと思います。
これでmysqlclientをインストールできるかと思います。
pip install mysqlclient
インストールができたら、ChatterBotのパラメータ「database_uri」に接続先のデータベースを設定します。
from chatterbot import ChatBot
bot = ChatBot(
name='MyBot',
database_uri='mysql://root:password@127.0.0.1:3306/db_name' # mysql://root:パスワード@ホスト:ポート/データベース名
)
※データベースの作成をお忘れなく
言語を日本語設定にした場合は「UnicodeEncodeError」に躓くので注意しましょう。
from chatterbot import ChatBot
import languages
bot = ChatBot(
name='MyBot',
tagger_language=languages.JPN, # 日本語設定
database_uri='mysql://root:password@127.0.0.1:3306/db_name' # mysql://root:パスワード@ホスト:ポート/データベース名
)
実行してみます。
$ python3 chatbot.py
YOU:こんにちは
...
...
UnicodeEncodeError: 'charmap' codec can't encode characters in position 0-4: character maps to <undefined>
このようエラーが出力された場合は、SQLAlchemyのドキュメントを参考にしデータベースに接続するパスに「?charset=utf8」、もしくわ「?charset=utf8mb4」を追加します。
from chatterbot import ChatBot
import languages
bot = ChatBot(
name='MyBot',
tagger_language=languages.JPN, # 日本語設定
database_uri='mysql://root:password@127.0.0.1:3306/db_name?charset=utf8mb4' # mysql://root:パスワード@ホスト:ポート/データベース名?文字セット
)
これで正常にMySQLデータベースへ保存されるかと思います。
残りは、日本語版コーパスデータのトレーニングに関してのエラーです。
まずはChatterBotCorpusTrainerクラスでコーパスを設定します。
# chatbot.py
from chatterbot import ChatBot
from chatterbot.trainers import ChatterBotCorpusTrainer
import languages
bot = ChatBot(
name='MyBot',
tagger_language=languages.JPN, # 日本語設定
database_uri='mysql://root:password@127.0.0.1:3306/db_name?charset=utf8mb4' # mysql://root:パスワード@ホスト:ポート/データベース名?文字セット
)
trainer = ChatterBotCorpusTrainer(bot)
trainer.train(
'chatterbot.corpus.japanese' # 日本語版コーパスを設定
)
while True:
try:
input_data = input('YOU: ')
response = bot.get_response(input_data)
print('{}: {}'.format(bot.name, response))
except(KeyboardInterrupt, EOFError, SystemExit):
break
実行してみると
$ python3 chatbot.py
Training ai.yml: [####################] 100%
Training botprofile.yml: [####################] 100%
Training computers.yml: [####################] 100%
Training conversations.yml: [####################] 100%
Training emotion.yml: [####################] 100%
Traceback (most recent call last):
...
...
sqlalchemy.exc.DataError: (MySQLdb._exceptions.DataError) (1406, "Data too long for column 'search_text' at row 1")
[SQL: INSERT INTO statement (text, search_text, conversation, created_at, in_response_to, search_in_response_to, persona) VALUES (%s, %s, %s, %s, %s, %s, %s)]
[parameters: ('私は実際に嫉妬を感じることはできませんが、私があたかもあたかもあたかもあたかもあたかもあたかもあたかもあたかもあたかもあたかもあたかもあたかもあたかもあたかもあたかも あたかもあたかもあたかもあたかもあたかもあたかもあたかもあたかもあたかもあたかもあたかも', 'PRON:実際 NOUN:嫉妬 NOUN:感じる VERB:ます AUX:私 PRON:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも ADV:あたかも', 'training', datetime.datetime(2020, 12, 17, 10, 34, 43, 605013, tzinfo=<UTC>), 'わたし?私は何を嫉妬していますか?', 'PRON:私 PRON:何 PRON:嫉妬', '')]
(Background on this error at: http://sqlalche.me/e/13/9h9h)
「sqlalchemy.exc.DataError: (MySQLdb._exceptions.DataError) (1406, "Data too long for column 'search_text' at row 1")」このようにコーパス内の文章をバイグラムペアに変換し、「search_text」に保存する際の文字列が長すぎてしまうというエラーです。
コーパスのトレーニング経過を見ると「emotion.yml」でエラーが出力されているのが分かるので、emotion.ymlの中身を確認し、文章を正しく修正する必要があります。
他にも同じようなエラーで躓いてしまう部分があるかと思いますが、適宜修正していきましょう。
これで一通りの日本語に関する設定は行えているかと思うので、あとはあなただけのチャットボットを開発していくだけです。
楽しいチャットボットライフをしていきましょう。
それでは以上です。
最後までご覧いただきありがとうございました。