【Python】チャットボットフレームワーク、ChatterBotの実装
投稿日 2020年12月10日 >> 更新日 2023年3月1日
今回は、PythonのチャットボットフレームワークであるChatterBotのインストールから実装までをご紹介していきたいと思います。
チャットボットというのは、「おしゃべりボット」とも言うようにユーザーの声明に対して何らかの応答を返すシステムです。
有名なソフトでは、初期のチャットボット(人工無能)である「ELIZA(イライザ)」やLINEの「りんな」、音声認識インターフェイスではAppleの「Siri」などです。

挙げてみれば切りがありませんが、そんなチャットボットを簡単な実装で開発できてしまうのがChatterBotであります。
ChatterBotは非常に汎用性が高く、様々な言語に対応しており、Webフレームワーク(DjangoやFlask)にも対応できるように考えられたライブラリです。
ボットとの会話のやりとりはSQLデータベース(デフォルトではSQlite3)へ逐次保存されていき、知識として保管されていきます。
ボットが応答を返す仕組みや言語設定などに関しては公式サイト、もしくわ別の記事にてご紹介するとして、今回は私が実際にChatterBotを実装してきた上で躓いた事(特にインストールの時)も踏まえて、ボットとの会話が行えるようになるまでを実践していきます。
公式サイトは以下のリンクとなります。

実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
※「ChatterBot==1.1.0」は削除されているみたいなので、別のバージョンで試してみて下さい。
| 使用ライブラリ | ライセンス |
|---|---|
| ChatterBot==1.1.0 | BSD |
| spacy==2.1.9(ChatterBotとセット) | MIT |
ChatterBotのインストール¶
ChatterBotライブラリは他にも多くのライブラリを含んでインストールしてきます。
お使いの環境で不足しているビルドツールがある場合、ChatterBotのインストール中にエラーで停止してしまう可能性があります。
素直にインストールするのであれば
$ pip install chatterbot
インストールの最中、何かしらのエラーで中断してしまう場合は幾つかセットアップ、もしくわ特定のソフトウェアで必要なビルドツールをインスールします。
エラー対策¶
ChatterBotライブラリでは、多くのモジュールも一緒にインストールされてきます。
その中でも特に引っかかってしまいやすいモジュールと言えば「Spacy(スペイシー)」だと思われます。
Spacyは有名な自然言語処理のモジュールとして知られており、Spacyをインストールするにも多くのモジュールが一緒にインストールされます。
恐らくそのインストールの過程でモジュールに必要とされているツール(ビルドツール)などが不足している原因であると思います。
Spacy単体でインストールが行えれば他の原因が考えられますが、試しにインストールして見ましょう。
ChatterBotで一緒にインストールされるSpacyはバージョン2.1.9なので、それに合わせておきます。
$ pip install spacy==2.1.9
以下はSpacyのインストールで必要な環境構築です。
以下のような場合
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-build-f2euto16/srsly/setup.py", line 11, in <module>
from Cython.Build import cythonize
ModuleNotFoundError: No module named 'Cython'
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-f2euto16/srsly/
もしくわ
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-build-vxdu214c/cymem/setup.py", line 10, in <module>
from Cython.Build import cythonize
ModuleNotFoundError: No module named 'Cython'
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-vxdu214c/cymem/
両者のエラーともに「ModuleNotFoundError: No module named 'Cython'」と出力されましたがspacy==2.1.9のバージョンでは「cymem==2.0.5」もしくわ「srsly==1.0.5」で「Cython」パッケージが必要との事です。
このようなエラーが出力された場合は、pipで「Cython」モジュールをインストールまたはアップグレードします。
Cythonは、C関数を直接呼び出すことができる機能としてPythonのような構文を使用しながらCレベルのパフォーマンスを実行できるとのことです。
他にも「srsly」では「setuptools」と「wheel」を最新にしておく必要があるので、一緒にアップグレードしておきます。
$ pip install --upgrade setuptools wheel cython
これで「spacy==2.1.9」がインストールできれば完了です。
$ pip install chatterbot
$ pip freeze
blis==0.2.4
certifi==2020.12.5
chardet==3.0.4
ChatterBot==1.1.0
click==7.1.2
cymem==2.0.5
Cython==0.29.21
idna==2.10
importlib-metadata==3.1.1
importlib-resources==3.3.0
joblib==0.17.0
mathparse==0.1.2
murmurhash==1.0.5
nltk==3.5
numpy==1.19.4
packaging==20.7
Pint==0.16.1
pkg-resources==0.0.0
plac==0.9.6
preshed==2.0.1
pyparsing==2.4.7
python-dateutil==2.8.1
pytz==2020.4
PyYAML==5.3.1
regex==2020.11.13
requests==2.25.0
six==1.15.0
spacy==2.1.9
SQLAlchemy==1.3.20
srsly==1.0.5
thinc==7.0.8
tqdm==4.54.1
urllib3==1.26.2
wasabi==0.8.0
zipp==3.4.0
統計モデルのダウンロード¶
ChatterBotのインストール時でも触れた通り、自然言語処理ツールの「SpaCy」も一緒にインストールされてくることから、ChatterBotの内部で処理される文字列の解析にはSpaCyが使用されています。
そのSpaCyが特定の文字列を解析するためには、別途統計モデルをダウンロードする必要があります。
統計モデルとは、機械学習もしくわ深層学習により事前にトレーニングされた学習済みモデルで、60以上の言語に対応した各モデルが用意されています。
このモデルをダウンロードして設定することにより、ある特定の文字列を解析することができます。
例えば、ダウンロードせずにChatterBotを初期化させてみると以下のようなエラーが出力されます。
$ python3
Python 3.6.9 (default, Oct 8 2020, 12:12:24)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
>>> # chatterbotモジュールからオブジェクトをインポート
>>> from chatterbot import ChatBot
>>>
>>> chatbot = ChatBot(name='MyBot')
Traceback (most recent call last):
.....
.....
File "/user/lib/python3.6/site-packages/spacy/util.py", line 139, in load_model
raise IOError(Errors.E050.format(name=name))
OSError: [E050] Can't find model 'en'. It doesn't seem to be a shortcut link, a Python package or a valid path to a data directory.
>>>
「OSError: [E050] Can't find model 'en'. It doesn't seem to be a shortcut link, a Python package or a valid path to a data directory.」このようなエラーが出力されます。
これは「モデル’en’が見つかりません」、要するに’Englich'のモデルが見つかりませんとなります。
ChatterBotではデフォルト設定で「Englich」が指定されているのでこのようなエラーが出力されます。
では「en」モデルをPythonパッケージとしてSpaCyコマンドを利用しダウンロードします。
$ python3 -m spacy download en
ダウンロードが完了したら、現在インストールされているモデルに互換性があるかどうかを確認してみます。
$ python3 -m spacy validate
✔ Loaded compatibility table
====================== Installed models (spaCy v2.1.9) ======================
ℹ spaCy installation:
/user/lib/python3.6/site-packages/spacy
TYPE NAME MODEL VERSION
package en-core-web-sm en_core_web_sm 2.1.0 ✔
link en en_core_web_sm 2.1.0 ✔
これで正常に実行できるようになります。
ChatterBotの実装¶
ここでの実装は、英語に特化されたChatterBotを使用していきます。
日本語設定に関しては別記事の方でご紹介していけたらと思います。
ではPythonファイルとして「chatbot.py」を作成し以下のように記述します。
# chatbot.py
from chatterbot import ChatBot
bot = ChatBot(name='MyBot')
chatterbotモジュールからChatBotを呼び出し、チャットボットの名前を「MyBot」として初期化します。
初期化時では、デフォルトで設定されているSQLデータベースとしてSQLite3データベースがカレントディレクトリに自動で作成されます。
これで後は、botインスタンスから「get_response()」メソッドの引数に任意の文字列を渡すだけで、MyBotからの応答を出力することができます。
# chatbot.py
from chatterbot import ChatBot
bot = ChatBot(name='MyBot')
# ----------続き----------
response = bot.get_response('Hello')
print('{}: {}'.format(bot.name, response))
name属性を呼び出すと、初期化時に設定したチャットボットの名前を出力できます。
それではコンソールにて実行してみます。
$ python3 chatbot.py
MyBot: Hello
「Hello」と返されました。
チャットボットの応答は、入力テキストを元にデータベース内から「既知」のデータを探し出して、データが見つかればそのデータが応答として出力されます。
では作成されたSQLite3データベース内がどうなっているか確認してみます。
「ls」コマンドでカレントディレクトリ内のファイルを表示させると「db.sqlite3」が作成されているのが分かるかと思います。
$ ls
chatbot.py db.sqlite3
sqlite3のパッケージがインストール済みであれば、sqlite3コマンドでデータベースに接続することができるはずです。
$ # データベースを指定
$ sqlite3 db.sqlite3
sqlite> # データベース内のテーブルを確認
sqlite> .tables
statement tag tag_association
sqlite>
sqlite> # テーブル内の表示に関する設定
sqlite> .header on
sqlite> .mode column
sqlite>
sqlite> # 会話内容が保存されているstatementの中身を表示
sqlite> select * from statement;
id text search_text conversation created_at in_response_to search_in_response_to persona
---------- ---------- ----------- ------------ -------------------------- -------------- --------------------- ----------
1 Hello hello 2020-12-10 15:44:00.236669
2 Hello 2020-12-10 15:44:00.352337 Hello bot:MyBot
sqlite>
終了する場合は、キーボードの「Ctrl」+「D」で抜けれます。
最初は入力されたテキスト「Hello」に対してデータベース内からデータを選び出すことができなかったため、入力テキストをそのまま応答として返すアルゴリズムとなっています。
私なりのstatementテーブル内の各カラムの解釈は以下のような意味付けであると思います。
| statementテーブル | |
|---|---|
| カラム | 内容 |
| id | 連番 |
| text | personaによる声明 |
| search_text | 最初の検索に使用される値(textの※バイグラムペア) |
| conversation | 訓練された会話であるか否か(トレーニング) |
| create_at | textが保存された日付 |
| in_response_to | ユーザーが直近で発したtext(声明) |
| search_in_response_to | 最後の検索に使用される値(in_response_toのバイグラムペア) |
| persona | 人物名 |
- ※バイグラム(bigram)とは、任意の文字列が2文字だけ続いた文字列のことであり、2文字、つまり2つの隣接し合う単語のペアをバイグラムペアと呼ぶ。
初期化時のチャットボットは知識無しから始まるので、データベースに会話のやりとりが蓄えられるまでは入力テキストに対する応答としてオウム返しとなります。
そんなチャットボットをより賢くさせるためには、トレーニングを積ませることが手っ取り早いです。
トレーニング¶
ChatterBotではチャットボットに会話の訓練を行う為のトレーニングクラスが用意されています。
トレーニングクラスは数種類ありますが、今回は「ListTrainer」を呼び出して、公式チュートリアルと同じようにチャットボットに会話の訓練を行ってからおしゃべりしてみたいと思います。
では、chatbot.pyファイルを編集します。
# chatbot.py
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
bot = ChatBot(name='MyBot')
# 訓練用のリスト
conversation = [
"Hello", # こんにちは
"Hi there!", # こんにちは!
"How are you?", # お元気ですか?
"I am good.", # 私は元気です。
"That is good to hear.", # それは良かった。
"Thank you", # ありがとうございました
"You are welcome.", # どう致しまして。
]
trainer = ListTrainer(bot)
trainer.train(conversation)
# ループ処理で声明を受け取る
# 終了する場合は「ctrl」+「c」を入力
while True:
try:
input_data = input('YOU: ')
response = bot.get_response(input_data)
print('{}: {}'.format(bot.name, response))
except(KeyboardInterrupt, EOFError, SystemExit):
break
ListTrainerクラスにbotインスタンスを渡し「trainer」変数に格納します。
そしてクラスメソッドの「train」に訓練データであるリストを渡します。
この時点でデータベース内にはconversationリストの要素が順次保存されています。
ではchatbot.pyを起動し会話をしてみましょう。
$ # 実行
$ python3 chatbot.py
List Trainer: [####################] 100%
YOU: Hello
MyBot: Hi there!
YOU: How are you?
MyBot: I am good.
YOU: That is good to hear.
MyBot: Thank you
YOU: You are welcome.
MyBot: Hello
これで最初のコミュニケーションである「あいさつ」はこなす事ができるようになりました。
トレーニングされた会話データはデータベース内ではどのように保存されているのか確認してみます。
$ sqlite3 db.sqlite3
sqlite>
sqlite> # テーブル内にヘッダーを設ける設定
sqlite> .header on
sqlite> .mode column
sqlite>
sqlite> select * from statement;
id text search_text conversation created_at in_response_to search_in_response_to persona
---------- ---------- ----------- ------------ -------------------------- -------------- --------------------- ----------
1 Hello hello 2020-12-10 15:44:00.236669
2 Hello 2020-12-10 15:44:00.352337 Hello bot:MyBot
3 Hello hello training 2020-12-11 08:27:14.118928
4 Hi there! INTJ:there training 2020-12-11 08:27:14.147802 Hello hello
5 How are yo ADV:be VERB training 2020-12-11 08:27:14.168469 Hi there! INTJ:there
6 I am good. PRON:be VER training 2020-12-11 08:27:14.182964 How are you? ADV:be VERB:-pron-
7 That is go ADJ:hear training 2020-12-11 08:27:14.197022 I am good. PRON:be VERB:good
8 Thank you VERB:-pron- training 2020-12-11 08:27:14.204618 That is good t ADJ:hear
9 You are we PRON:be VER training 2020-12-11 08:27:14.215226 Thank you VERB:-pron-
10 Hello hello 2020-12-11 08:27:52.540282 Hello
11 Hi there! 2020-12-11 08:27:52.685526 Hello bot:MyBot
12 How are yo ADV:be VERB 2020-12-11 08:28:05.431188 Hello
13 I am good. 2020-12-11 08:28:05.458580 How are you? bot:MyBot
14 That is go ADJ:hear 2020-12-11 08:28:16.396231 How are you?
15 Thank you 2020-12-11 08:28:16.425426 That is good t bot:MyBot
16 You are we PRON:be VER 2020-12-11 08:28:31.419079 That is good t
17 Hello 2020-12-11 08:28:31.448226 You are welcom bot:MyBot
sqlite>
通常の入力されたテキストとは違い、トレーニングされたテキストには「conversation」列に「training」として保存されています。
trainingとして保存されているデータには「search_in_response_to」列にも値が格納されています。
このチャットボットのデフォルトで使用されている検索アルゴリズムでは、「search_text」または「search_in_response_to」の値を選び出し入力に対する応答として出力されています。
では「search_text」「search_in_response_to」に格納されている値、「バイグラムペア」について見ていきます。
検索に使用されるバイグラムペアについて¶
ChatterBotの検索アルゴリズムではバイグラムペアを使用して既知のデータを抽出してきているため、ここでは簡単な説明をしていきます。
公式ドキュメントでも分かりやすい説明がされています。
バイグラム(bigram)とは、連続する2個の文字列をペアとしてまとめられた文字列で、以下のような形に置き換わります。
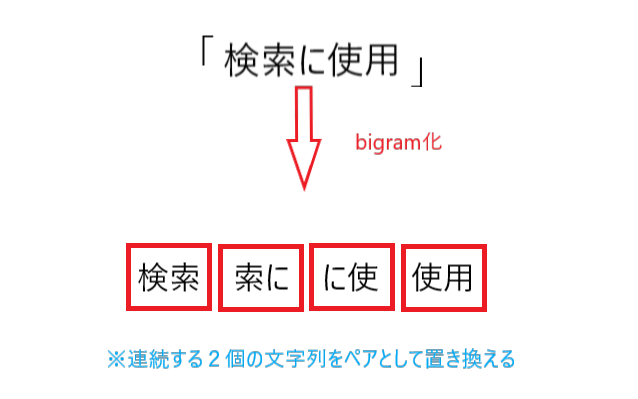
連続する1個の文字列であればユニグラム(unigram)、連続する3個の文字であればトライグラム(trigram)となり、4個以上であれば4-gram、5-gram、...、と表されます。
これらは通称「n-gram」と言われており、n個の連続する文字列を一組として置き換え、検索システムの条件などに使用されています。
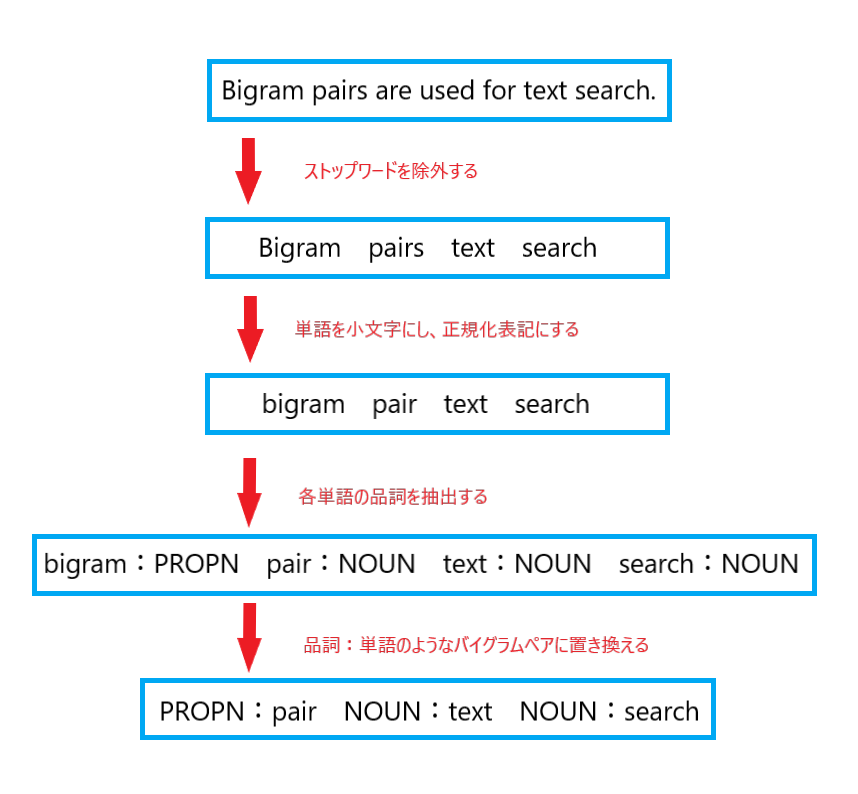
そしてChatterBotでは、文章内の単語の「品詞」と「単語」をペアとしてバイグラムに置き換えています。
品詞の抽出には自然言語処理ライブラリのSpaCyが使用されているので、試しに実装してみます。
>>> # Pythonインタープリター
>>>
>>> # モジュールをインポート
>>> import spacy
>>>
>>> # ダウンロードされている’en’モデルをロード
>>> nlp = spacy.load('en')
>>>
>>> text = 'Bigram pairs are used for text search.'
>>>
>>> # テキストを解析する
>>> tokens = nlp(text)
>>>
>>> # tokensから「テキスト」「品詞」「正規化表記」「ストップワード」を抽出する
>>> for token in tokens:
... print('{} === {} === {} === {}'.format(
... token.text, # テキスト
... token.pos_, # 品詞
... token.lemma_, # 正規化表記
... token.is_stop # ストップワード
... ))
...
Bigram === PROPN === Bigram === False
pairs === NOUN === pair === False
are === VERB === be === True
used === VERB === use === True
for === ADP === for === True
text === NOUN === text === False
search === NOUN === search === False
. === PUNCT === . === False
>>>
SpaCyによって抽出された要素を元に、バイグラムペアを以下のような形に置き換えています。
では実際に「Bigram pairs are used for text search.」という文章をチャットボットに入力して、search_textカラムのバイグラムペアを確認してみましょう。
sqlite>
sqlite> .headers on
sqlite> # id、text、search_textのみ取得
sqlite> select id, text, search_text from statement;
id|text|search_text
1|Hello|hello
2|Hello|
....
....
18|Bigram pairs are used for text search|PROPN:pair NOUN:text NOUN:search
図と同じバイグラムペアに変換されていることが分かります。
このような検索システムを使い、ChatterBotは最も一致する声明として応答をしているわけです。
もちろん検索に引っかかるデータは一つだけとは限らず会話を行った分ヒットする数も増えます。
数十、数百となる場合がありますが、その中で最も一致する応答として決定づけているのが「信頼度」となる割合です。
ChatterBotは検索アルゴリズムの中で「信頼度」をどのように決定づけているのか見ていきます。
検索されたデータの信頼度について¶
ChatterBotでは入力に対する応答として、入力テキストのバイグラムペアを元にデータベース内から既知の応答用データを検索しています。
初期の状態でデータベース内が空であれば、入力されてきたメッセージをオウム返しで応答するわけですが、大量にデータが蓄積されたデータベースだった場合どのように1つの応答メッセージを返しているのか気になります。
その答えが「信頼度」における評価です。
ChatterBotは非常に汎用性が高く、応答を決定づけるアルゴリズムは幾つか用意されており、且つ自作することも可能なのですが、ここでご紹介するのはデフォルトで設定されている「レーベンシュタイン距離」における評価方法です。
レーベンシュタイン距離とは、Wikipediaによると「二つの文字列がどの程度異なっているかを示す距離の一種である。編集距離(へんしゅうきょり、英: edit distance)とも呼ばれる。」です。

ChatterBot公式ドキュメントでは、「レーベンシュタイン距離アルゴリズムに基づく二つの文字列の類似性を比較する」とありますが、実際に使用されているアルゴリズムはPython標準ライブラリの「difflib.SequenceMatcher」による評価です。
では「difflib.SequenceMatcher」オブジェクトを使用して、二つの文字列を比較してみたいと思います。
>>>
>>> from difflib import SequenceMatcher
>>>
>>> # 比較する文字列を2つ用意します
>>> a = 'Bigram pairs are used for text search.'
>>> b = 'Trigram pairs are used for text search.'
>>>
>>> # 初期化
>>> s = SequenceMatcher(None, a, b)
>>>
>>> # ratio()メソッドで類似度を測る
>>> print(s.ratio())
0.961038961038961
>>>
ちなみに、Python外部ライブラリのレーベンシュタイン距離アルゴリズムによる類似度も同じ結果になることが分かっています。
$ pip install python-Levenshtein
>>> from difflib import SequenceMatcher
>>> # レーベンシュタイン距離
>>> import Levenshtein
>>>
>>> a = 'Bigram pairs are used for text search.'
>>> b = 'Trigram pairs are used for text search.'
>>>
>>> s = SequenceMatcher(None, a, b)
>>> print('SequenceMatcher=={}'.format(s.ratio()))
SequenceMatcher==0.961038961038961
>>>
>>> print('Levenshtein=={}'.format(Levenshtein.ratio(a, b)))
Levenshtein==0.961038961038961
>>>
両者のモジュールは幾つか共通する機能が含まれているので、余力のある方は試してみて下さい。
話は戻りますが、この数値化(比率)された結果をChatterBotでは「信頼度」としての評価基準とし、最も信頼度の割合が大きかった既知のデータが1つだけ選び出されます。
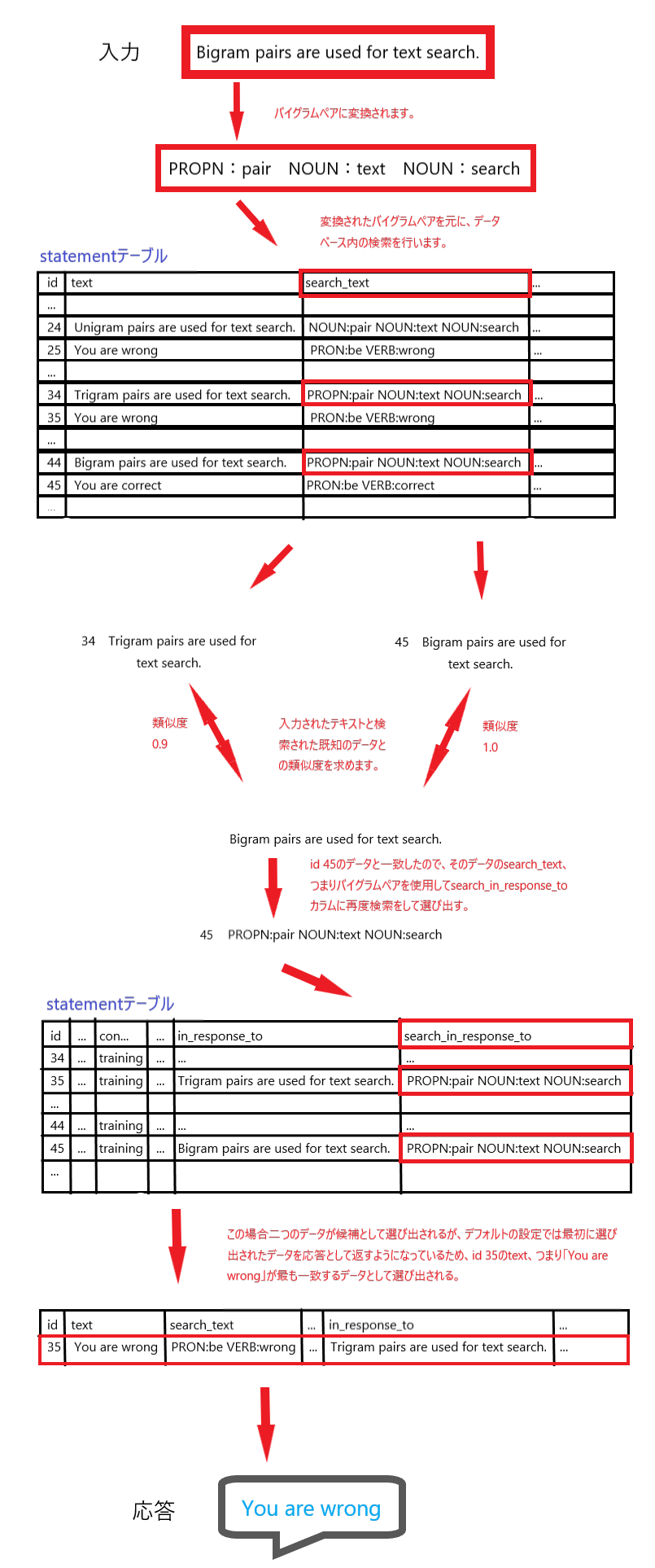
本来であれば「Bigram pairs are used for text search.」の入力に対して、「You are correct」と応答してほしかったのですが、上の図では「類似度」に着目した内容としたので応答に関する設定上及びデータベースに保存された順番により上手く返されていませんでした。
トレーニングクラスを使った上図の模範を載せておきます。
# chatbot.py
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
bot = ChatBot(name='MyBot')
# 訓練用のリスト
conversation = [
"Hello", # こんにちは
"Hi there!", # こんにちは!
"How are you?", # お元気ですか?
"I am good.", # 私は元気です。
"That is good to hear.", # それは良かった。
"Thank you", # ありがとうございました
"You are welcome.", # どう致しまして。
]
conversation_2 = [
'Unigram pairs are used for text search.', # ユニグラムペアはテキスト検索に使用されます。
'You are wrong', # あなたは間違っている
'What is the correct answer?', # 正解は何ですか?
'ChatterBot uses bigram pairs.' # ChatterBotはバイグラムペアを使用します。
]
conversation_3 = [
'Trigram pairs are used for text search.', # トライグラムペアはテキスト検索に使用されます。
'You are wrong', # あなたは間違っている
'What is the correct answer?', # 正解は何ですか?
'ChatterBot uses bigram pairs.' # ChatterBotはバイグラムペアを使用します。
]
conversation_4 = [
'Bigram pairs are used for text search.', # バイグラムペアはテキスト検索に使用されます。
'You are correct' # あなたは正しいです
]
trainer = ListTrainer(bot)
# トレーニング開始
trainer.train(conversation)
trainer.train(conversation_2)
trainer.train(conversation_3)
trainer.train(conversation_4)
# ループ処理で声明を受け取る
# 終了する場合は「ctrl」+「c」を入力
while True:
try:
input_data = input('YOU: ')
response = bot.get_response(input_data)
print('{}: {}'.format(bot.name, response))
except(KeyboardInterrupt, EOFError, SystemExit):
break
SQLite3データベースファイル(db.sqlite3)を削除しておきます。
$ rm db.sqlite3
チャットボットを起動します。
$ python3 chatbot.py
List Trainer: [####################] 100%
List Trainer: [####################] 100%
List Trainer: [####################] 100%
List Trainer: [####################] 100%
YOU: Bigram pairs are used for text search.
MyBot: You are wrong
YOU: What is the correct answer?
MyBot: ChatterBot uses bigram pairs.
YOU: Thank you
MyBot: You are welcome.
ではSQLite3データベースの中身を確認してみます。
$ sqlite3 db.sqlite3
sqlite> # テーブルのカラムをONにする
sqlite> .headers on
sqlite> # フレーム形式にする
sqlite> .mode column
sqlite> # 各カラムの幅の文字数を設定
sqlite> .width 3 40 31 12 40 31
sqlite> # 取得したいデータを指定
sqlite> select id, text, search_text, conversation, in_response_to, search_in_response_to, persona from statement;
id text search_text conversation in_response_to search_in_response_to persona
--- ---------------------------------------- ------------------------------- ------------ ---------------------------------------- ------------------------------- ----------
1 Hello hello training
2 Hi there! INTJ:there training Hello hello
3 How are you? ADV:be VERB:-pron- training Hi there! INTJ:there
4 I am good. PRON:be VERB:good training How are you? ADV:be VERB:-pron-
5 That is good to hear. ADJ:hear training I am good. PRON:be VERB:good
6 Thank you VERB:-pron- training That is good to hear. ADJ:hear
7 You are welcome. PRON:be VERB:welcome training Thank you VERB:-pron-
8 Unigram pairs are used for text search. NOUN:pair NOUN:text NOUN:search training
9 You are wrong PRON:be VERB:wrong training Unigram pairs are used for text search. NOUN:pair NOUN:text NOUN:search
10 What is the correct answer? ADJ:answer training You are wrong PRON:be VERB:wrong
11 ChatterBot uses bigram pairs. PROPN:use VERB:bigram NOUN:pair training What is the correct answer? ADJ:answer
12 Trigram pairs are used for text search. PROPN:pair NOUN:text NOUN:searc training
13 You are wrong PRON:be VERB:wrong training Trigram pairs are used for text search. PROPN:pair NOUN:text NOUN:searc
14 What is the correct answer? ADJ:answer training You are wrong PRON:be VERB:wrong
15 ChatterBot uses bigram pairs. PROPN:use VERB:bigram NOUN:pair training What is the correct answer? ADJ:answer
16 Bigram pairs are used for text search. PROPN:pair NOUN:text NOUN:searc training
17 You are correct PRON:be VERB:correct training Bigram pairs are used for text search. PROPN:pair NOUN:text NOUN:searc
18 Bigram pairs are used for text search. PROPN:pair NOUN:text NOUN:searc
19 You are wrong Bigram pairs are used for text search. bot:MyBot
20 What is the correct answer? ADJ:answer Bigram pairs are used for text search.
21 ChatterBot uses bigram pairs. What is the correct answer? bot:MyBot
22 Thank you VERB:-pron- What is the correct answer?
23 You are welcome. Thank you bot:MyBot
sqlite>
今回は余り深掘りはしませんが、応答の選択なども設定できるので余力のある方は公式ドキュメントをご参照してみてください。
ChatterBotパラメータの設定¶
ChatteBotには様々なパラメータを設定することができますが、最初の段階では割とブラックボックスのような状態です。
どのようなパラメータがあり、自分好みの設定でチャットボットを開発していけばいいのか見ていきましょう。
Python標準ライブラリの「inspect」モジュールを使用して、デフォルトで使用されている各パラメータを確認してみます。
>>>
>>> from chatterbot import ChatBot
>>> from inspect import signature
>>>
>>> # オブジェクトのパラメータ(引数)を確認
>>> signature(ChatBot)
<Signature (name, **kwargs)>
>>>
次に、初期化された後のクラスメソッドや属性にはどのような値が設定されているか確認してみます。
>>>
>>> from inspect import getmembers
>>>
>>> # 初期化
>>> bot = ChatBot('MyBot')
>>>
>>> # リストの変数として格納される
>>> members = getmembers(bot)
>>>
>>> for index, member in enumerate(members, 1):
... print('{} {} === {}'.format(index, member[0], member[1]))
... print('---------------------------------------------')
...
1 ChatBotException === <class 'chatterbot.chatterbot.ChatBot.ChatBotException'>
---------------------------------------------
2 __class__ === <class 'chatterbot.chatterbot.ChatBot'>
---------------------------------------------
3 __delattr__ === <method-wrapper '__delattr__' of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
4 __dict__ === {'name': 'MyBot', 'logic_adapters': [<chatterbot.logic.best_match.BestMatch object at 0x7f2d3ef8d470>], 'storage': <chatterbot.storage.sql_storage.SQLStorageAdapter object at 0x7f2d571bdda0>, 'search_algorithms': {'indexed_text_search': <chatterbot.search.IndexedTextSearch object at 0x7f2d3ef6bdd8>, 'text_search': <chatterbot.search.TextSearch object at 0x7f2d3ef6be80>}, 'preprocessors': [<function clean_whitespace at 0x7f2d3ef70e18>], 'logger': <Logger chatterbot.chatterbot (WARNING)>, 'read_only': False}
---------------------------------------------
5 __dir__ === <built-in method __dir__ of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
6 __doc__ ===
A conversational dialog chat bot.
---------------------------------------------
7 __eq__ === <method-wrapper '__eq__' of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
8 __format__ === <built-in method __format__ of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
9 __ge__ === <method-wrapper '__ge__' of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
10 __getattribute__ === <method-wrapper '__getattribute__' of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
11 __gt__ === <method-wrapper '__gt__' of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
12 __hash__ === <method-wrapper '__hash__' of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
13 __init__ === <bound method ChatBot.__init__ of <chatterbot.chatterbot.ChatBot object at 0x7f2d5807b6a0>>
---------------------------------------------
14 __init_subclass__ === <built-in method __init_subclass__ of type object at 0x23fadc8>
---------------------------------------------
15 __le__ === <method-wrapper '__le__' of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
16 __lt__ === <method-wrapper '__lt__' of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
17 __module__ === chatterbot.chatterbot
---------------------------------------------
18 __ne__ === <method-wrapper '__ne__' of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
19 __new__ === <built-in method __new__ of type object at 0x9d17a0>
---------------------------------------------
20 __reduce__ === <built-in method __reduce__ of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
21 __reduce_ex__ === <built-in method __reduce_ex__ of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
22 __repr__ === <method-wrapper '__repr__' of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
23 __setattr__ === <method-wrapper '__setattr__' of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
24 __sizeof__ === <built-in method __sizeof__ of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
25 __str__ === <method-wrapper '__str__' of ChatBot object at 0x7f2d5807b6a0>
---------------------------------------------
26 __subclasshook__ === <built-in method __subclasshook__ of type object at 0x23fadc8>
---------------------------------------------
27 __weakref__ === None
---------------------------------------------
28 generate_response === <bound method ChatBot.generate_response of <chatterbot.chatterbot.ChatBot object at 0x7f2d5807b6a0>>
---------------------------------------------
29 get_latest_response === <bound method ChatBot.get_latest_response of <chatterbot.chatterbot.ChatBot object at 0x7f2d5807b6a0>>
---------------------------------------------
30 get_response === <bound method ChatBot.get_response of <chatterbot.chatterbot.ChatBot object at 0x7f2d5807b6a0>>
---------------------------------------------
31 learn_response === <bound method ChatBot.learn_response of <chatterbot.chatterbot.ChatBot object at 0x7f2d5807b6a0>>
---------------------------------------------
32 logger === <Logger chatterbot.chatterbot (WARNING)>
---------------------------------------------
33 logic_adapters === [<chatterbot.logic.best_match.BestMatch object at 0x7f2d3ef8d470>]
---------------------------------------------
34 name === MyBot
---------------------------------------------
35 preprocessors === [<function clean_whitespace at 0x7f2d3ef70e18>]
---------------------------------------------
36 read_only === False
---------------------------------------------
37 search_algorithms === {'indexed_text_search': <chatterbot.search.IndexedTextSearch object at 0x7f2d3ef6bdd8>, 'text_search': <chatterbot.search.TextSearch object at 0x7f2d3ef6be80>}
---------------------------------------------
38 storage === <chatterbot.storage.sql_storage.SQLStorageAdapter object at 0x7f2d571bdda0>
---------------------------------------------
>>>
それぞれのパラメータにはオブジェクトが格納されているのが分かります。
これらは独立した機能を持ち、ChatterBotライブラリで用意されている別の機能を設定したり自作機能なんかも作成してチャットボットをカスタマイズすることもできます。
主な構成要素は、「ロジックアダプター」や「ストレージアダプター」と呼ばれる部分ですが、今回は簡単な設定内容を変更していこうと思うので、詳細は公式ドキュメントをご参照してみください。
データベースの変更(SQLite3)¶
ChatterBotではPython外部ライブラリのSQLAlchemyによってデータベースへの接続を行っています。
なので、大規模なSQLデータベースを使用する際なんかは、各SQLキャリアのドライバをインストールしてあげるだけで、簡単に設定できてしまいます。
今回はSQLite3のデータベースファイルを変更するだけですが、会話の自動保存をオフにする方法も見ていきます。
データベースを変更するには、パラメータ「database_uri」にパスを指定します。
from chatterbot import ChatBot
bot = ChatBot(
name='MyBot',
database_uri='sqlite:///mydb.sqlite3' # キャリア名:///データベース名
)
これだけで設定できてしまいます。
このデータベースパラメータの設定はストレージアダプターによって処理されてゆき、モデルを構築します。
MongoDB以外のデータベースであれば、デフォルト値のストレージアダプターで利用可能だと思われます。
from chatterbot import ChatBot
bot = ChatBot(
name='MyBot',
storage_adapter='chatterbot.storage.SQLStorageAdapter', # デフォルト値
database_uri='sqlite:///mydb.sqlite3' # キャリア名:///データベース名
)
次に、自動保存されるチャットボットの会話を「オフ」に設定します。
そのためには「read_only」属性に「True」を設定します。
from chatterbot import ChatBot
bot = ChatBot(
name='MyBot',
read_only=True, # デフォルトではFalse
storage_adapter='chatterbot.storage.SQLStorageAdapter',
database_uri='sqlite:///mydb.sqlite3'
)
これでユーザーからの不用意な声明を保存しなくて済みます。
MySQLデータベースへの接続および日本語設定に関しては以下の記事をご参照ください。
ロジックアダプターの設定¶
ロジックアダプターは、字のごとくChatterBotの核と言える部分です。
ユーザーからの入力声明に対する応答を細かく制御することができます。
デフォルトでは「BestMatchAdapter」と言われる機能が使われていて、他にも数種類のアダプターが用意されています。
1つひとつに細かい設定が可能で、且つ複数のロジックアダプターを設定できるので非常に柔軟なソフトウェアです。
from chatterbot import ChatBot
bot = ChatBot(
name='MyBot',
logic_adapters = [
'chatterbot.logic.BestMatch' # デフォルト値
]
)
パラメータの「logic_adapters」にはリスト形式でお好みのロジックアダプターを設定しますが、ロジックアダプターオブジェクトに備わっている各種設定を行うには、リスト内に辞書形式で属性値の設定を行います。
from chatterbot import ChatBot
bot = ChatBot(
name='MyBot',
logic_adapters = [
{
'import_path': 'chatterbot.logic.BestMatch', # ロジックアダプターを指定
'default_response': 'How do you feel about it?', # 入力声明が信頼度が80%以下だった場合に返される応答
'maximum_similarity_threshold': 0.80 # 80%以下の信頼度だった場合にdefault_responseを応答させる
}
]
)
ロジックアダプターの「default_response」属性に任意の文字列を渡すことで、入力に対する既知のデータが見つからなかった場合に応答として返すようにできます。
default_response属性にリスト形式で渡すこともでき、ランダムな応答で返してくれるようになります。
'default_response': ['How do you feel about it?', 'I still lack knowledge'], # ランダムに応答を返す
例えばトレーニングされていない声明を入力すると
YOU: Do you like artificial intelligence?
MyBot: How do you feel about it?
上記のように、既知のデータが見つからなかった場合はユーザーの質問に対してユーザー自身が答えてくれるような応答を設定することができるので、後から保存されたデータを分析しチャットボットにトレーニングを積ませればどんどん会話の幅が増えて来るかと思われます。
ログを有効にして処理情報を取得する¶
ChatterBotにはPython標準ライブラリの「logging」モジュールが使用されているので、簡単にログ出力を実行できます。
from chatterbot import ChatBot
import logging
# ログレベルを設定
logging.basicConfig(level=logging.INFO)
bot = ChatBot('MyBot')
ロギングを有効にすると、コンソール上で入力と応答の間で処理されている各種情報が一緒に出力されてきます。
YOU: Hello
INFO:chatterbot.chatterbot:Beginning search for close text match
INFO:chatterbot.chatterbot:Processing search results
INFO:chatterbot.chatterbot:Using "Hello" as a close match to "Hello" with a confidence of 0
INFO:chatterbot.chatterbot:No responses found. Generating alternate response list.
INFO:chatterbot.chatterbot:No known response to the input was found. Selecting a random response.
INFO:chatterbot.chatterbot:BestMatch selected "How do you feel about it?" as a response with a confidence of 0
INFO:chatterbot.chatterbot:Adding "Hello" as a response to "None"
MyBot: How do you feel about it?
YOU:
その他の設定について¶
この記事ではある程度ChatterBot公式チュートリアルに習ってポイントとなる実装を進めてきましたが、非常に汎用的で高機能なライブラリであると同時に様々な設定が可能であることが分かりました。
日本語の設定や機能の拡張、そしてWebフレームワークとの連携などをご紹介できなかった内容が多々あるので、別途記事にしていきたいと思います。
ではチャットボットライフを楽しみましょう。
最後までご覧いただきありがとうございました。