【ChatterBot】自然言語処理ライブラリのMeCabを使用してチャットボットの日本語検索を強化する
投稿日 2021年1月9日 >> 更新日 2023年3月1日
今回はPythonのチャットボットフレームワークである「ChatterBot」に、自然言語処理ライブラリの「MeCab」を組み込んで日本語の検索ワードを強化したチャットボットを実装していきたいと思います。
ChatterBotは簡単なコードでチャットボットを実装できるPythonの外部ライブラリであり、そのアルゴリズムでは「spacy」という自然言語処理ライブラリが使用されています。
いわゆるディーブラーニングの技術が使われていると言っても過言ではないspacyを利用して、データベース内の検索ワードを作成しています。
spacyによって形態素解析されたユーザーからの入力文章を、「n-gram」と言った形に変形して検索対象として使用しています。
検索エンジンなどではこのような手法が使用されていますが、やはり重要になってくるのが自然言語処理による「n-gram」の作成になってくるかと思われます。
spacyは様々な国の自然言語を解析できる強力なライブラリですけれど、独特な言語を持つ日本なら最適なライブラリを使用したいと思うはずです。
そこで今回はChatterBotに標準で搭載されている自然言語処理ライブラリの「spacy」を使用せず、日本語に特化されたライブラリの「MeCab」を使用して検索に必要な「n-gram」を自作していきたいと思います。
MeCabはCRF(Conditional Random Field)という機械学習の識別モデルが採用されており、他の解析器であるChaSen、Juman、KAKASIより高速に動作するとのことです。
この記事での前提としては、ChatterBotを軽く実装したことがありMeCabが既にインストール済みを想定しているので、宜しければ公式ドキュメントや私の過去記事、その他のサンプルなんかを参考に前提をクリアしてもらえるとスムーズです。
実行環境&使用ライブラリ¶
| 実行環境 |
|---|
| Windows Subsystem for Linux |
| Python 3.6.9 |
| pip 9.0.1 |
| 使用ライブラリ | ライセンス |
|---|---|
| ChatterBot==1.1.0 | BSD |
| mecab-python3==0.996.2 | BSD |
ChatterBotの実装¶
まず手始めに、ChatterBotライブラリを簡単に実装していきたいと思います。
本体をインストールしてきます。
※エラーなどに躓いてしまう場合は上部ページのリンク(過去記事)をご参照してみください。
$ pip install chatterbot
必要なライブラリがインストールされたら、自然言語処理ライブラリの「spacy」が自然言語を解析するために必要な統計モデルをダウンロードします。
統計モデルはディープラーニングにより学習された学習済みモデルとも言われており、今回は英語モデルの「en」をダウンロードします。
$ python3 -m spacy download en
これでChatterBotモジュールから必要なコード記述し、チャットを開始してみます。
ファイルは「chatbot.py」で作成しています。
# chatbot.py
from chatterbot import ChatBot
# 初期化
bot = ChatBot(
name='MyBot',
)
while True:
try:
input_data = input('YOU: ')
response = bot.get_response(input_data) # インプットデータをボットに渡す
print('{}: {}'.format(bot.name, response))
print('-------------------\n')
except(KeyboardInterrupt, EOFError, SystemExit): # 終了する場合は「ctrl」+「c」を入力
break
ファイルを実行すると会話を始めることができます。
$ python3 chatbot.py
YOU: Hello bot!
MyBot: Hello bot!
-------------------
YOU: How are you?
MyBot: Hello bot!
-------------------
YOU: Who are you?
MyBot: Hello bot!
-------------------
ChatterBotの名前としている「MyBot」の応答では、ユーザーが初めて入力した「Hello bot!」という文章を続けて返しているのが分かります。
ChatterBotでは学習機能が備えられており、文章を学習(データベースに蓄積)することによって入力された文章に相応しい応答を返せるようになっていきます。
しかし単純に初期化されただけのチャットボットでは無学習の状態なので、応答に使用されるデータはこれまでにユーザーが入力した文章をランダムに返すものにすぎません。
ある文章に対してある応答を返すように学習させるには、トレーニングクラスを使用をします。
# chatbot.py
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer # インポート
# 初期化
bot = ChatBot(
name='MyBot',
)
# トレーニングクラスを初期化
trainer = ListTrainer(bot)
# トレーニングデータを挿入
trainer.train([
"Hello!",
"Hello World!",
"How are you?",
"I am very fine!",
"That's good",
"Do you like AI?",
])
while True:
...
これでチャットボットを実行してみると、トレーニングが開始されデフォルトのデータベース(sqlite3)へ保存され準備が整います。
$ python3 chatbot.py
List Trainer: [####################] 100%
YOU: Hello
MyBot: Hello World!
-------------------
YOU: How are you?
MyBot: I am very fine!
-------------------
YOU: That's good
MyBot: Do you like AI?
-------------------
トレーニングさせることによって入力された文章に相応しい応答データを検索して返せるようになりましたが、トレーニングしているデータとされていないデータの違いを理解するためにデータベースに保存されているデータを探索してみます。
ChatterBotデータベース内の探索¶
ChatterBotを実行すると、デフォルトで設定されているSQLite3データベースが作成され、会話の記録として保存されます。
$ ls
db.sqlite3 chatbot.py
ではSQLite3データベースに接続して保存データを確認してみましょう。
# sqlite3コマンドで接続を開始する
$ sqlite3 db.sqlite3
SQLite version 3.22.0 2018-01-22 18:45:57
Enter ".help" for usage hints.
sqlite>
sqlite> # DB内のテーブルを確認
sqlite> .tables
statement tag tag_association
sqlite>
sqlite> # statementテーブル内のカラム情報を取得
sqlite> .schema statement
CREATE TABLE statement (
id INTEGER NOT NULL,
text VARCHAR(255),
search_text VARCHAR(255) DEFAULT '' NOT NULL,
conversation VARCHAR(32) DEFAULT '' NOT NULL,
created_at DATETIME DEFAULT (CURRENT_TIMESTAMP),
in_response_to VARCHAR(255),
search_in_response_to VARCHAR(255) DEFAULT '' NOT NULL,
persona VARCHAR(50) DEFAULT '' NOT NULL,
PRIMARY KEY (id)
);
sqlite>
sqlite> # データを取得する際のカラム名をオンにする
sqlite> .header on
sqlite>
sqlite> # データをテーブル構造に設定する
sqlite> .mode column
sqlite>
sqlite> # created_at(日付)以外のカラムを取得する
sqlite> select
...> id, text, search_text, conversation, in_response_to, search_in_response_to, persona
...> from statement;
id text search_text conversation in_response_to search_in_response_to persona
---------- ---------- ----------- ------------ -------------- --------------------- ----------
1 Hello bot! INTJ:bot
2 Hello bot! Hello bot! bot:MyBot
3 How are yo ADV:be AUX: Hello bot!
4 Hello bot! How are you? bot:MyBot
5 Who are yo PRON:be AUX How are you?
6 Hello bot! Who are you? bot:MyBot
7 Hello! hello ! training
8 Hello Worl INTJ:world training Hello! hello !
9 How are yo ADV:be AUX: training Hello World! INTJ:world
10 I am very PRON:be AUX training How are you? ADV:be AUX:-pron-
11 That's goo DET:good training I am very fine PRON:be AUX:very ADV:
12 Do you lik VERB:ai training That's good DET:good
13 Hello hello Who are you?
14 Hello Worl Hello bot:MyBot
15 How are yo ADV:be AUX: Hello
16 I am very How are you? bot:MyBot
17 That's goo DET:good How are you?
18 Do you lik That's good bot:MyBot
sqlite>
各カラム列の文字列制限の関係で一部文章が途中で切れてしまっていますが、データベース内のstatementテーブルでは会話が行われた順に保存されています。
ここでは「created_at」の日付カラムを除いた6つのカラムを出力していますが、各カラムの内容は以下のようになります。
- text:ユーザーの入力文章もしくわボットの応答文章
- search_text:text(文章)のbigram(バイグラム)ペア
- conversation:学習データかそうでないか
- in_response_to:学習データであれば応答のtextとして返す為の文章、学習データでなければユーザーが手前に入力した文章
- search_in_response_to:in_response_toのbigram(バイグラム)ペア
- persona:ユーザーデータかボットデータか
まずsearch_textとsearch_in_response_toに格納されているバイグラムペアを簡単に説明すると、文章を検索するために特化した「n-gram法」を使用したペアに変換しています。
n-gramの「n」は文字列の数を表しており、何個の文字列で文章を区切っていくかを指しています。
例えばある文章を2つの連続する文字列で分割していくと、以下のようになります。
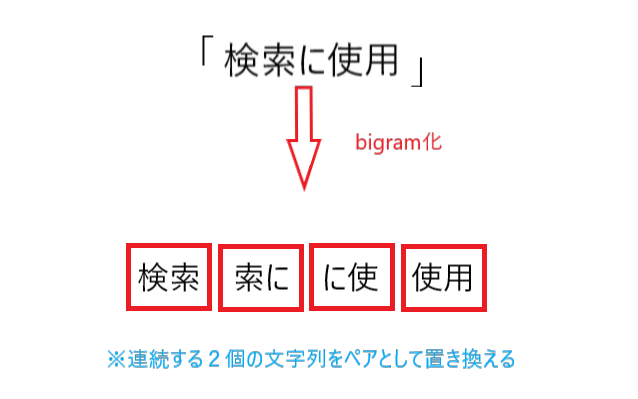
上図ではニコイチで1セットとしているので通称「bigram(バイグラム)」と言い、文字列の数によって「〇gram」と表記されます。
そして「search_text」と「search_in_response_to」では少し複雑なバイグラムとなっていますが、これは自然言語処理ライブラリのspacyによって形態素解析された文章のエンティティから、「品詞:単語の原形」といったバイグラムペアとなっています。
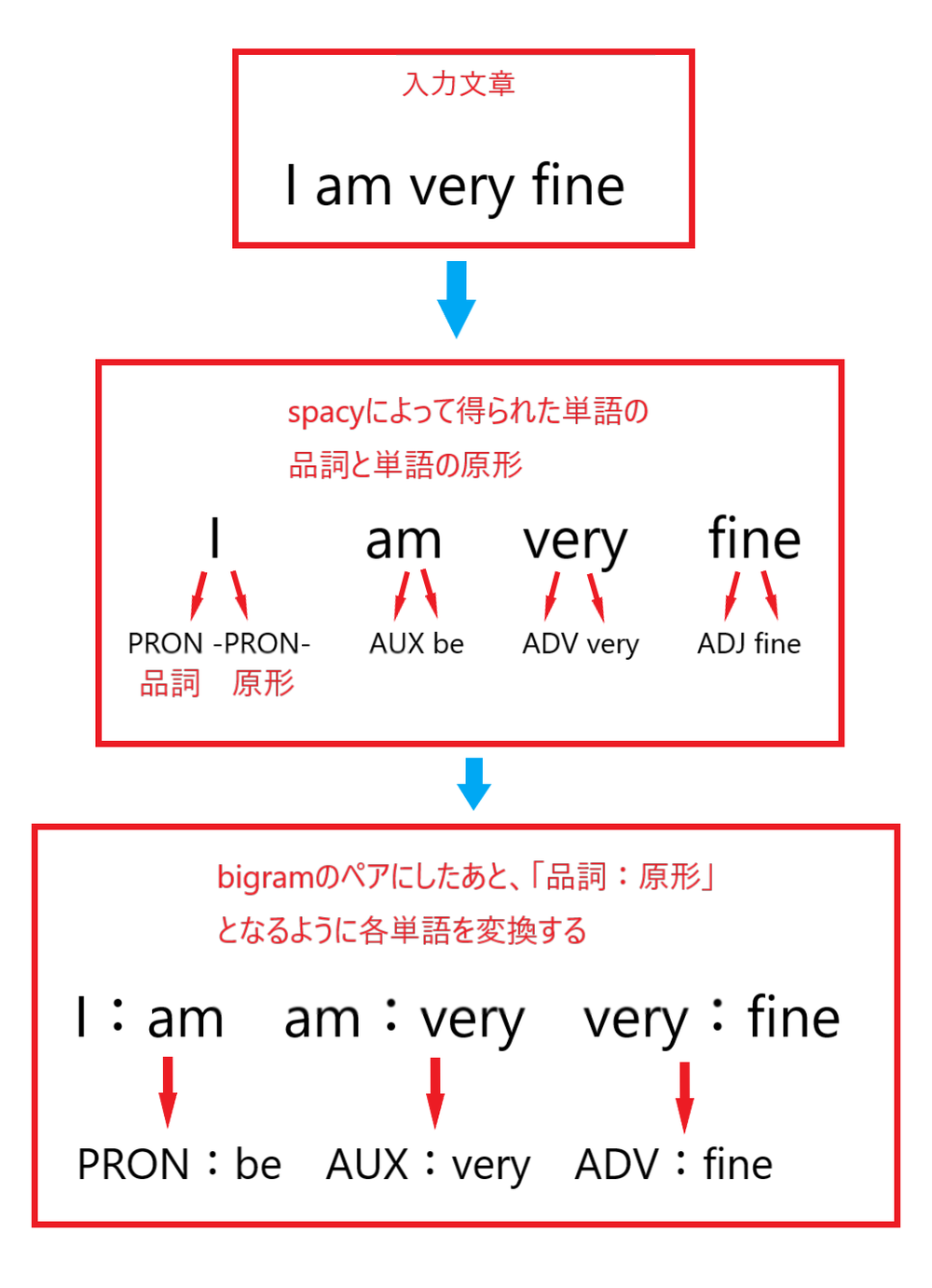
このようにチャットボットが応答メッセージを的確に返すための文字列として、「search_text」と「search_in_response_to」に格納されます。
なぜ検索用として使用されるデータが「search_text」と「search_in_response_to」に分かれているのかというと、チャットボットが応答メッセージを発するまでに2回の検索をかけているからです。
ユーザーから文章が入力されると、第1検索では「search_text」から最も一致する文章を探します。
第2検索では、「search_text」から見つかった文章を使って「search_in_response_to」から最も一致する文章を探し、見つかった場合はそのデータの「text」が応答メッセージとして出力されます。
つまり「search_in_response_to」カラム内にデータが無い場合は、データベース内に保存されているデータをランダムに返すだけのチャットボットとなります。
次にconversationカラム内を見てみると、「training」というデータが保存されていますが、これはトレーニングクラスを使って学習されたデータである事を表します。

トレーニングデータにのみ「search_in_response_to」カラム列にbigramペアが格納されていますが、これは応答用の「text」を検索するためのデータです。

トレーニングされたデータと非トレーニングデータの違い、そして検索用に使用されているバイグラムペアの詳細を見てきましたが、バイグラムペアの要素が重要であることが分かりました。
ChatterBotがデフォルトで実装しているspacyによるバイグラムペアを、日本語に特化させるためにMeCabモジュールを使用して自作のバイグラムペアに変更していきます。
MeCabを使用したカスタムTaggerの作成¶
自然言語処理ライブラリspacyによるバイグラムペアが実装されているクラスオブジェクトは「chatterbot.tagging.PosLemmaTagger」にあります。
ソースコードはChatterBot開発者のGitHubから確認することができます。
# tagging.py
import string
from chatterbot import languages
class LowercaseTagger(object):
"""
Returns the text in lowercase.
"""
def __init__(self, language=None):
self.language = language or languages.ENG
def get_text_index_string(self, text):
return text.lower()
# spacyによるバイグラムペアの作成はこちら
class PosLemmaTagger(object):
def __init__(self, language=None):
import spacy
self.language = language or languages.ENG
self.punctuation_table = str.maketrans(dict.fromkeys(string.punctuation))
self.nlp = spacy.load(self.language.ISO_639_1.lower())
def get_text_index_string(self, text):
"""
Return a string of text containing part-of-speech, lemma pairs.
"""
bigram_pairs = []
if len(text) <= 2:
text_without_punctuation = text.translate(self.punctuation_table)
if len(text_without_punctuation) >= 1:
text = text_without_punctuation
document = self.nlp(text)
if len(text) <= 2:
bigram_pairs = [
token.lemma_.lower() for token in document
]
else:
tokens = [
token for token in document if token.is_alpha and not token.is_stop
]
if len(tokens) < 2:
tokens = [
token for token in document if token.is_alpha
]
for index in range(1, len(tokens)):
bigram_pairs.append('{}:{}'.format(
tokens[index - 1].pos_,
tokens[index].lemma_.lower()
))
if not bigram_pairs:
bigram_pairs = [
token.lemma_.lower() for token in document
]
return ' '.join(bigram_pairs)
上記ソースコード内のPosLemmaTaggerクラス内で処理されているコードをモチーフにして、自作のMecabTaggerクラスを「my_tagging.py」として作成します。
そして「mecab-python3」のバージョンですが、都合上「mecab-python3==0.996.2」がカナ文字を取得しやすいので、こちらを使用して実装します。
$ pip install mecab-python3==0.996.2
MeCabが使用できる状態でしたら、以下のように定義していきます。
# my_tagging.py
from chatterbot import languages
import MeCab
class MecabTagger(object):
def __init__(self, language=None):
"""
languageパラメータはChatterBotの初期化時に
tagger_language='フォーマット'
として渡します。
"""
self.language = language
# デフォルトではspacyの「en」モデルが使用されるので「分かち書き」に変更
if self.language == languages.ENG:
self.language = '-Owakati'
self.tagger = MeCab.Tagger(self.language)
def get_text_index_string(self, text):
"""
bigramペアを作成するクラスメソッドです。
この機能を使用使用するには、ChatterBot初期化時に
tagger=MecabTagger
のように渡します。
bigramの要素は、「カナ文字:品詞」の形に作成されます。
"""
bigram_pairs = []
document = self.tagger.parseToNode(text).next
if document:
tokens = []
while document.next:
feature = document.feature.split(',')
if feature[0] in ['補助記号', '記号']: # リスト内の要素は除外
pass
else:
tokens.append(feature[0]) # 名詞を追加
tokens.append(feature[-1]) # カナ文字を追加
document = document.next
for index in range(2, len(tokens), 2): # bigramペア「カナ:品詞」を作成
bigram_pairs.append('{}:{}'.format(
tokens[index - 1],
tokens[index]
))
if not bigram_pairs:
document = self.tagger.parseToNode(text).next
while document.next:
feature = document.feature.split(',')
if feature[0] in ['補助記号', '記号']:
pass
else:
bigram_pairs.append(
feature[-1]
)
document = document.next
return ' '.join(bigram_pairs)
上記の処理は英文などには考慮していませんので、適宜好きなように書き換えてみて下さい。
また、バイグラムペアの要素もインデックス番号を変えるだけで変更できます。
MeCab自体の処理は以下の記事で説明しているので宜しければそちらをご参照ください。
ではChatterBotのパラメータに自作したMecabTaggerクラスを渡します。
# chatbot.py
from chatterbot import ChatBot
from my_tagging import MecabTagger # 自作Taggerをインポート
bot = ChatBot(
name='MyBot',
tagger=MecabTagger, # パラメータに自作Taggerを渡す
)
# 終了する場合は「ctrl」+「c」を入力
while True:
try:
input_data = input('YOU: ')
response = bot.get_response(input_data)
print('{}: {}'.format(bot.name, response))
print('-------------------\n')
except(KeyboardInterrupt, EOFError, SystemExit):
break
SQLite3データベースを削除しておきます。
$ rm db.sqlite3
では適当に実行してみます。
$ python3 chatbot.py
YOU: こんにちは
MyBot: こんにちは
-------------------
YOU: あなたは誰ですか?
MyBot: こんにちは
-------------------
YOU: 人工知能ですか?
MyBot: あなたは誰ですか?
-------------------
上手く会話が行えていればMecabTaggerクラスを実行してバイグラムペアが作成されていると思われます。
「db.sqlite3」データベース内を探索してみます。
$ sqlite3 db.sqlite3
sqlite> .header on
sqlite> .mode column
sqlite> .width 5 20 30 # カラム列の幅を調整
sqlite> select id, text, search_text from statement;
id text search_text
----- -------------------- ------------------------------
1 こんにちは コンニチワ
2 こんにちは
3 あなたは誰ですか? アナタ:助詞 ワ:名詞 ダレ:助動詞 デス:助詞
4 こんにちは
5 人工知能ですか? ジンコー:名詞 チノー:助動詞 デス:助詞
6 あなたは誰ですか?
sqlite>
上手い事「カナ:品詞」というバイグラムに変換されています。
「id」5の「search_text」に注目してみると、「人工知能」と言う単語が別々の単語へと置き換わっています。
MeCabのデフォルトで使用されている辞書では新語に対応していない場合があるので、新語に対応した別の辞書を使用してみたいと思います。
辞書のインストールに関してはこちらをご参照ください。
ではChatterBotのパラメータに辞書を設定します。
# chatbot.py
from chatterbot import ChatBot
from my_tagging import MecabTagger
bot = ChatBot(
name='MyBot',
tagger=MecabTagger,
tagger_language='-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd' # -dオプションで辞書のパスを指定
)
# 終了する場合は「ctrl」+「c」を入力
while True:
try:
input_data = input('YOU: ')
response = bot.get_response(input_data)
print('{}: {}'.format(bot.name, response))
print('-------------------\n')
except(KeyboardInterrupt, EOFError, SystemExit):
break
適当に会話をします。
$ python3 chatbot.py
YOU: 人工知能ですか?
MyBot: こんにちは
-------------------
YOU: 自然言語処理ライブラリをご存知ですか?
MyBot: 人工知能ですか?
-------------------
YOU: ディープラーニングを実装出来ますか?
MyBot: あなたは誰ですか?
-------------------
データベース内のバイグラムを確認してみます。
$ sqlite3 db.sqlite3
sqlite> .header on
sqlite> .mode column
sqlite> .width 5 40 50
sqlite> select id, text, search_text from statement;
id text search_text
----- ---------------------------------------- --------------------------------------------------
1 こんにちは コンニチワ
2 こんにちは
3 あなたは誰ですか? アナタ:助詞 ワ:名詞 ダレ:助動詞 デス:助詞
4 こんにちは
5 人工知能ですか? ジンコー:名詞 チノー:助動詞 デス:助詞
6 あなたは誰ですか?
7 人工知能ですか? ジンコーチノー:助動詞 デス:助詞
8 こんにちは
9 自然言語処理ライブラリをご存知ですか? シゼンゲンゴショリ:名詞 ライブラリ:助詞 ヲ:名詞 ゴゾンジ:助動詞 デス:助詞
10 人工知能ですか?
11 ディープラーニングを実装出来ますか? ディープラーニング:助詞 ヲ:名詞 ジッソー:動詞 デキ:助動詞 マス:助詞
12 あなたは誰ですか?
sqlite>
しっかり新語が対応されています。
しかし今回ここで実装しているMeCabは少し古いバージョンですので、最新ですとさらに対応されているかと思います。
今回は単純な実装となりましたが、MeCabを使うことによってカタカナを取得することができるので入力文章に近い既知のデータを漏らさずにすくい上げることが出来るようになったかと思います。
あとは特定の品詞以外はストップワードとして除外するなど、何かしらの工夫をすることによってさらに性能が向上するかもしれません。
他にも様々なパラメータに自作機能を設定できるので公式ドキュメントなどを参考にしてChatterBotライフを楽しんでください。
それでは以上となります。
最後までご覧いただきありがとうございました。